 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Time-Series Data Augmentation Model through Diffusion and Transformer Integration
May 01, 2025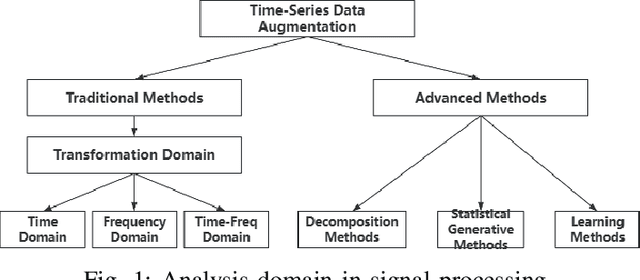



With the development of Artificial Intelligence, numerous real-world tasks have been accomplished using technology integrated with deep learning. To achieve optimal performance, deep neural networks typically require large volumes of data for training. Although advances in data augmentation have facilitated the acquisition of vast datasets, most of this data is concentrated in domains like images and speech. However, there has been relatively less focus on augmenting time-series data. To address this gap and generate a substantial amount of time-series data, we propose a simple and effective method that combines the Diffusion and Transformer models. By utilizing an adjusted diffusion denoising model to generate a large volume of initial time-step action data, followed by employing a Transformer model to predict subsequent actions, and incorporating a weighted loss function to achieve convergence, the method demonstrates its effectiveness. Using the performance improvement of the model after applying augmented data as a benchmark, and comparing the results with those obtained without data augmentation or using traditional data augmentation methods, this approach shows its capability to produce high-quality augmented data.
A Flexible Plug-and-Play Module for Generating Variable-Length
Dec 12, 2024Deep supervised hashing has become a pivotal technique in large-scale image retrieval, offering significant benefits in terms of storage and search efficiency. However, existing deep supervised hashing models predominantly focus on generating fixed-length hash codes. This approach fails to address the inherent trade-off between efficiency and effectiveness when using hash codes of varying lengths. To determine the optimal hash code length for a specific task, multiple models must be trained for different lengths, leading to increased training time and computational overhead. Furthermore, the current paradigm overlooks the potential relationships between hash codes of different lengths, limiting the overall effectiveness of the models. To address these challenges, we propose the Nested Hash Layer (NHL), a plug-and-play module designed for existing deep supervised hashing models. The NHL framework introduces a novel mechanism to simultaneously generate hash codes of varying lengths in a nested manner. To tackle the optimization conflicts arising from the multiple learning objectives associated with different code lengths, we further propose an adaptive weights strategy that dynamically monitors and adjusts gradients during training. Additionally, recognizing that the structural information in longer hash codes can provide valuable guidance for shorter hash codes, we develop a long-short cascade self-distillation method within the NHL to enhance the overall quality of the generated hash codes. Extensive experiments demonstrate that NHL not only accelerates the training process but also achieves superior retrieval performance across various deep hashing models. Our code is publicly available at https://github.com/hly1998/NHL.
AdaptSSR: Pre-training User Model with Augmentation-Adaptive Self-Supervised Ranking
Oct 24, 2023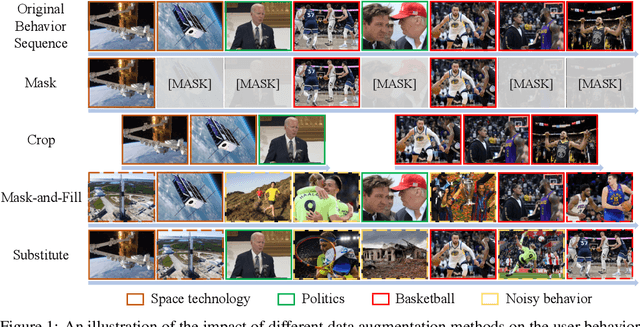
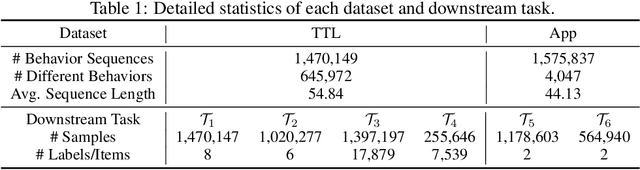
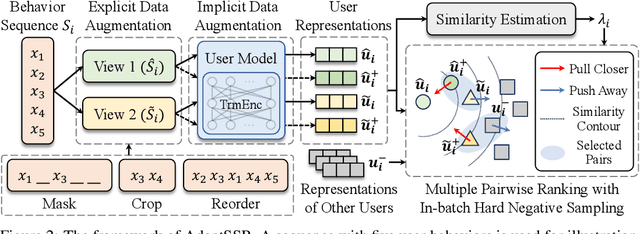
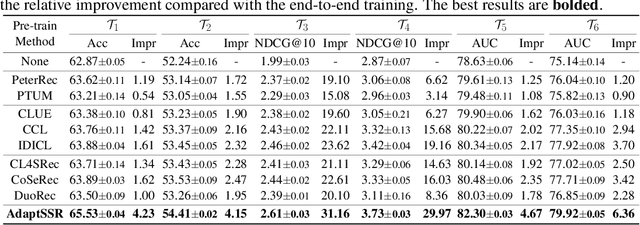
User modeling, which aims to capture users' characteristics or interests, heavily relies on task-specific labeled data and suffers from the data sparsity issue. Several recent studies tackled this problem by pre-training the user model on massive user behavior sequences with a contrastive learning task. Generally, these methods assume different views of the same behavior sequence constructed via data augmentation are semantically consistent, i.e., reflecting similar characteristics or interests of the user, and thus maximizing their agreement in the feature space. However, due to the diverse interests and heavy noise in user behaviors, existing augmentation methods tend to lose certain characteristics of the user or introduce noisy behaviors. Thus, forcing the user model to directly maximize the similarity between the augmented views may result in a negative transfer. To this end, we propose to replace the contrastive learning task with a new pretext task: Augmentation-Adaptive SelfSupervised Ranking (AdaptSSR), which alleviates the requirement of semantic consistency between the augmented views while pre-training a discriminative user model. Specifically, we adopt a multiple pairwise ranking loss which trains the user model to capture the similarity orders between the implicitly augmented view, the explicitly augmented view, and views from other users. We further employ an in-batch hard negative sampling strategy to facilitate model training. Moreover, considering the distinct impacts of data augmentation on different behavior sequences, we design an augmentation-adaptive fusion mechanism to automatically adjust the similarity order constraint applied to each sample based on the estimated similarity between the augmented views. Extensive experiments on both public and industrial datasets with six downstream tasks verify the effectiveness of AdaptSSR.