 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGDSRec: Graph-Based Decentralized Collaborative Filtering for Social Recommendation
May 20, 2022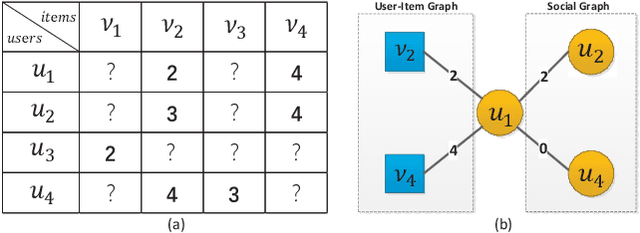
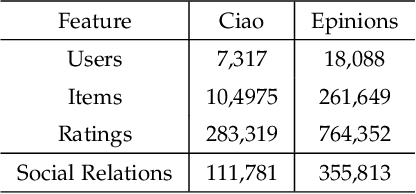
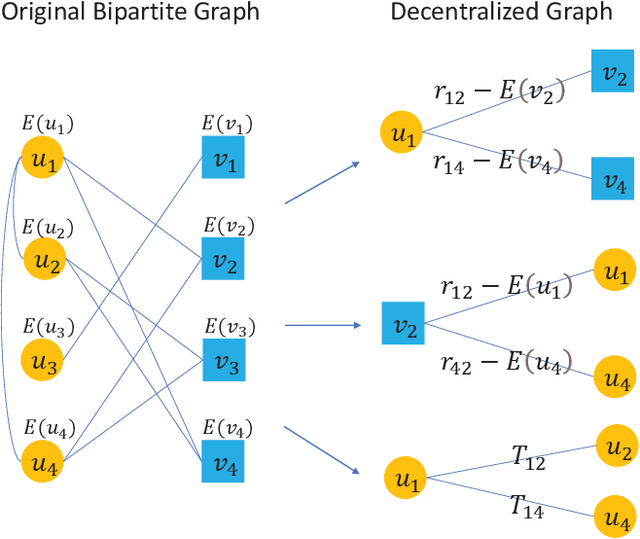
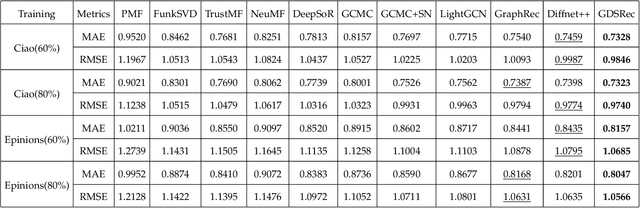
Generating recommendations based on user-item interactions and user-user social relations is a common use case in web-based systems. These connections can be naturally represented as graph-structured data and thus utilizing graph neural networks (GNNs) for social recommendation has become a promising research direction. However, existing graph-based methods fails to consider the bias offsets of users (items). For example, a low rating from a fastidious user may not imply a negative attitude toward this item because the user tends to assign low ratings in common cases. Such statistics should be considered into the graph modeling procedure. While some past work considers the biases, we argue that these proposed methods only treat them as scalars and can not capture the complete bias information hidden in data. Besides, social connections between users should also be differentiable so that users with similar item preference would have more influence on each other. To this end, we propose Graph-Based Decentralized Collaborative Filtering for Social Recommendation (GDSRec). GDSRec treats the biases as vectors and fuses them into the process of learning user and item representations. The statistical bias offsets are captured by decentralized neighborhood aggregation while the social connection strength is defined according to the preference similarity and then incorporated into the model design. We conduct extensive experiments on two benchmark datasets to verify the effectiveness of the proposed model. Experimental results show that the proposed GDSRec achieves superior performance compared with state-of-the-art related baselines. Our implementations are available in \url{https://github.com/MEICRS/GDSRec}.
SPAN: A Stochastic Projected Approximate Newton Method
Mar 03, 2020
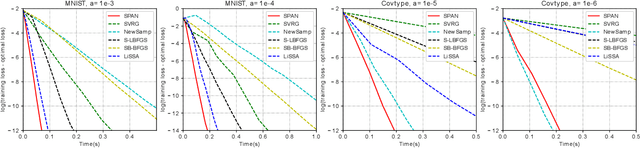
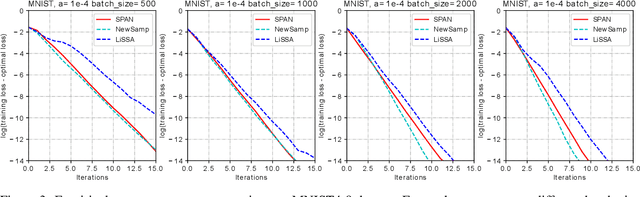
Second-order optimization methods have desirable convergence properties. However, the exact Newton method requires expensive computation for the Hessian and its inverse. In this paper, we propose SPAN, a novel approximate and fast Newton method. SPAN computes the inverse of the Hessian matrix via low-rank approximation and stochastic Hessian-vector products. Our experiments on multiple benchmark datasets demonstrate that SPAN outperforms existing first-order and second-order optimization methods in terms of the convergence wall-clock time. Furthermore, we provide a theoretical analysis of the per-iteration complexity, the approximation error, and the convergence rate. Both the theoretical analysis and experimental results show that our proposed method achieves a better trade-off between the convergence rate and the per-iteration efficiency.
Variance Reduced Local SGD with Lower Communication Complexity
Dec 30, 2019
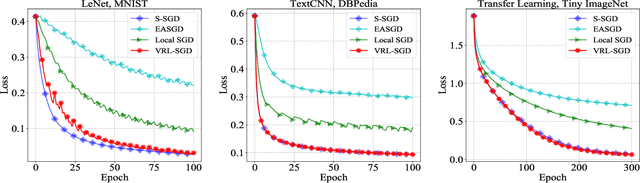

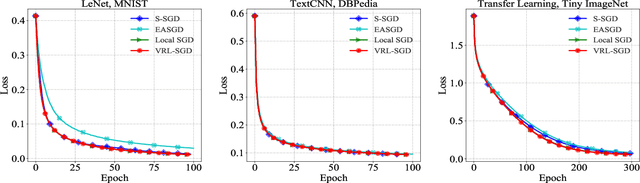
To accelerate the training of machine learning models, distributed stochastic gradient descent (SGD) and its variants have been widely adopted, which apply multiple workers in parallel to speed up training. Among them, Local SGD has gained much attention due to its lower communication cost. Nevertheless, when the data distribution on workers is non-identical, Local SGD requires $O(T^{\frac{3}{4}} N^{\frac{3}{4}})$ communications to maintain its \emph{linear iteration speedup} property, where $T$ is the total number of iterations and $N$ is the number of workers. In this paper, we propose Variance Reduced Local SGD (VRL-SGD) to further reduce the communication complexity. Benefiting from eliminating the dependency on the gradient variance among workers, we theoretically prove that VRL-SGD achieves a \emph{linear iteration speedup} with a lower communication complexity $O(T^{\frac{1}{2}} N^{\frac{3}{2}})$ even if workers access non-identical datasets. We conduct experiments on three machine learning tasks, and the experimental results demonstrate that VRL-SGD performs impressively better than Local SGD when the data among workers are quite diverse.
Long-term Joint Scheduling for Urban Traffic
Oct 27, 2019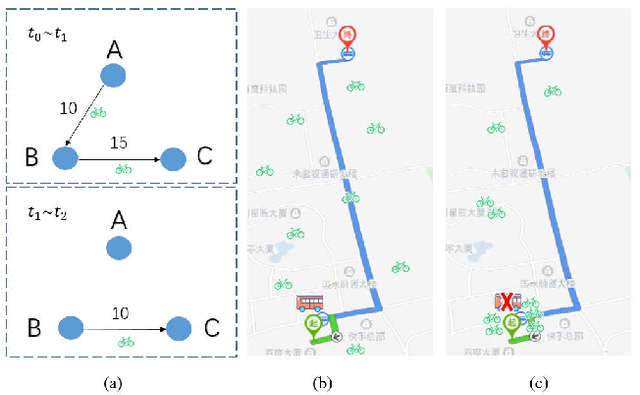
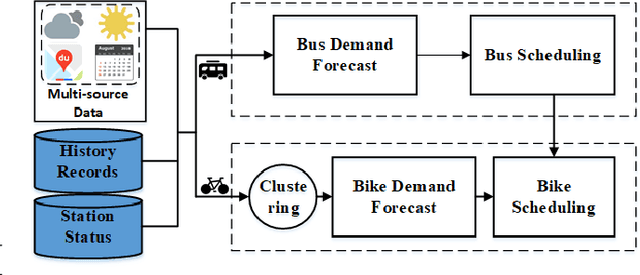
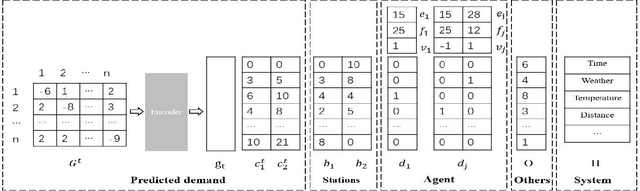
Recently, the traffic congestion in modern cities has become a growing worry for the residents. As presented in Baidu traffic report, the commuting stress index has reached surprising 1.973 in Beijing during rush hours, which results in longer trip time and increased vehicular queueing. Previous works have demonstrated that by reasonable scheduling, e.g, rebalancing bike-sharing systems and optimized bus transportation, the traffic efficiency could be significantly improved with little resource consumption. However, there are still two disadvantages that restrict their performance: (1) they only consider single scheduling in a short time, but ignoring the layout after first reposition, and (2) they only focus on the single transport. However, the multi-modal characteristics of urban public transportation are largely under-exploited. In this paper, we propose an efficient and economical multi-modal traffic scheduling scheme named JLRLS based on spatio -temporal prediction, which adopts reinforcement learning to obtain optimal long-term and joint schedule. In JLRLS, we combines multiple transportation to conduct scheduling by their own characteristics, which potentially helps the system to reach the optimal performance. Our implementation of an example by PaddlePaddle is available at https://github.com/bigdata-ustc/Long-term-Joint-Scheduling, with an explaining video at https://youtu.be/t5M2wVPhTyk.
Faster Distributed Deep Net Training: Computation and Communication Decoupled Stochastic Gradient Descent
Jun 28, 2019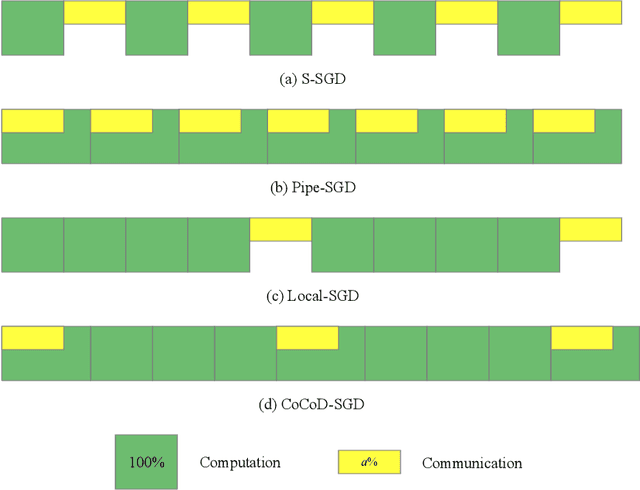
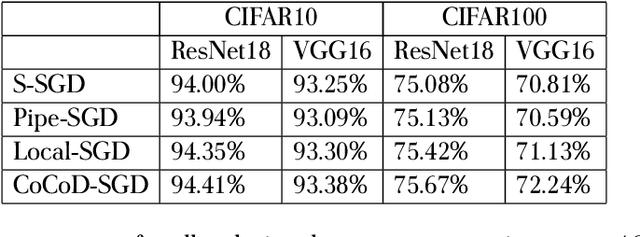

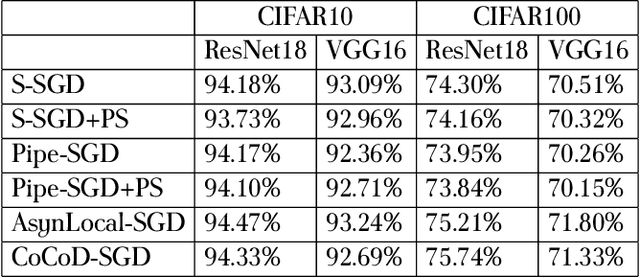
With the increase in the amount of data and the expansion of model scale, distributed parallel training becomes an important and successful technique to address the optimization challenges. Nevertheless, although distributed stochastic gradient descent (SGD) algorithms can achieve a linear iteration speedup, they are limited significantly in practice by the communication cost, making it difficult to achieve a linear time speedup. In this paper, we propose a computation and communication decoupled stochastic gradient descent (CoCoD-SGD) algorithm to run computation and communication in parallel to reduce the communication cost. We prove that CoCoD-SGD has a linear iteration speedup with respect to the total computation capability of the hardware resources. In addition, it has a lower communication complexity and better time speedup comparing with traditional distributed SGD algorithms. Experiments on deep neural network training demonstrate the significant improvements of CoCoD-SGD: when training ResNet18 and VGG16 with 16 Geforce GTX 1080Ti GPUs, CoCoD-SGD is up to 2-3$\times$ faster than traditional synchronous SGD.