 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFaster Distributed Deep Net Training: Computation and Communication Decoupled Stochastic Gradient Descent
Paper and Code
Jun 28, 2019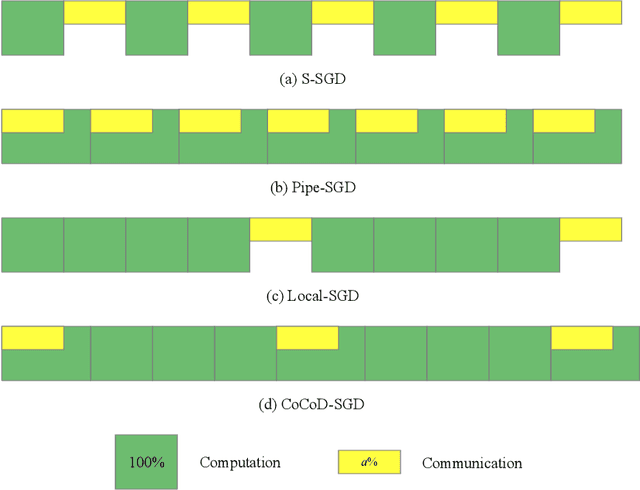
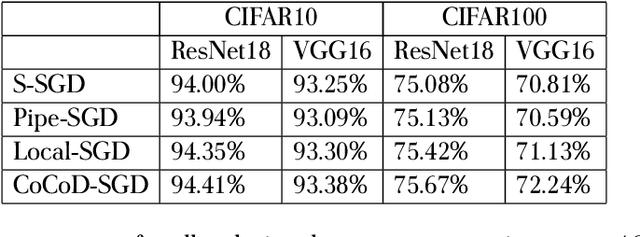

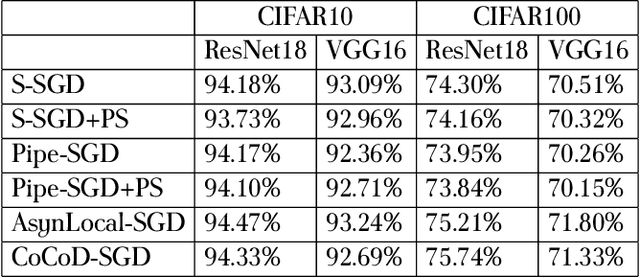
With the increase in the amount of data and the expansion of model scale, distributed parallel training becomes an important and successful technique to address the optimization challenges. Nevertheless, although distributed stochastic gradient descent (SGD) algorithms can achieve a linear iteration speedup, they are limited significantly in practice by the communication cost, making it difficult to achieve a linear time speedup. In this paper, we propose a computation and communication decoupled stochastic gradient descent (CoCoD-SGD) algorithm to run computation and communication in parallel to reduce the communication cost. We prove that CoCoD-SGD has a linear iteration speedup with respect to the total computation capability of the hardware resources. In addition, it has a lower communication complexity and better time speedup comparing with traditional distributed SGD algorithms. Experiments on deep neural network training demonstrate the significant improvements of CoCoD-SGD: when training ResNet18 and VGG16 with 16 Geforce GTX 1080Ti GPUs, CoCoD-SGD is up to 2-3$\times$ faster than traditional synchronous SGD.