 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHighly Compressed Tokenizer Can Generate Without Training
Jun 09, 2025Commonly used image tokenizers produce a 2D grid of spatially arranged tokens. In contrast, so-called 1D image tokenizers represent images as highly compressed one-dimensional sequences of as few as 32 discrete tokens. We find that the high degree of compression achieved by a 1D tokenizer with vector quantization enables image editing and generative capabilities through heuristic manipulation of tokens, demonstrating that even very crude manipulations -- such as copying and replacing tokens between latent representations of images -- enable fine-grained image editing by transferring appearance and semantic attributes. Motivated by the expressivity of the 1D tokenizer's latent space, we construct an image generation pipeline leveraging gradient-based test-time optimization of tokens with plug-and-play loss functions such as reconstruction or CLIP similarity. Our approach is demonstrated for inpainting and text-guided image editing use cases, and can generate diverse and realistic samples without requiring training of any generative model.
CSTrack: Enhancing RGB-X Tracking via Compact Spatiotemporal Features
May 26, 2025Effectively modeling and utilizing spatiotemporal features from RGB and other modalities (\eg, depth, thermal, and event data, denoted as X) is the core of RGB-X tracker design. Existing methods often employ two parallel branches to separately process the RGB and X input streams, requiring the model to simultaneously handle two dispersed feature spaces, which complicates both the model structure and computation process. More critically, intra-modality spatial modeling within each dispersed space incurs substantial computational overhead, limiting resources for inter-modality spatial modeling and temporal modeling. To address this, we propose a novel tracker, CSTrack, which focuses on modeling Compact Spatiotemporal features to achieve simple yet effective tracking. Specifically, we first introduce an innovative Spatial Compact Module that integrates the RGB-X dual input streams into a compact spatial feature, enabling thorough intra- and inter-modality spatial modeling. Additionally, we design an efficient Temporal Compact Module that compactly represents temporal features by constructing the refined target distribution heatmap. Extensive experiments validate the effectiveness of our compact spatiotemporal modeling method, with CSTrack achieving new SOTA results on mainstream RGB-X benchmarks. The code and models will be released at: https://github.com/XiaokunFeng/CSTrack.
Enhancing Vision-Language Tracking by Effectively Converting Textual Cues into Visual Cues
Dec 27, 2024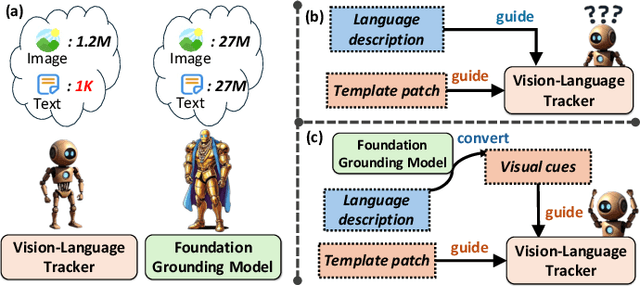
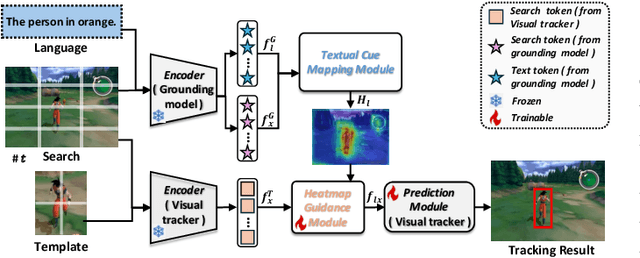
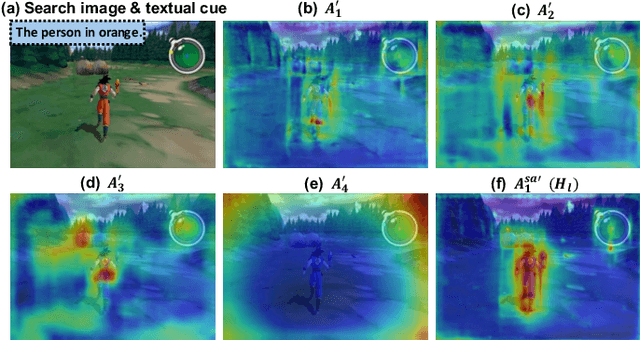
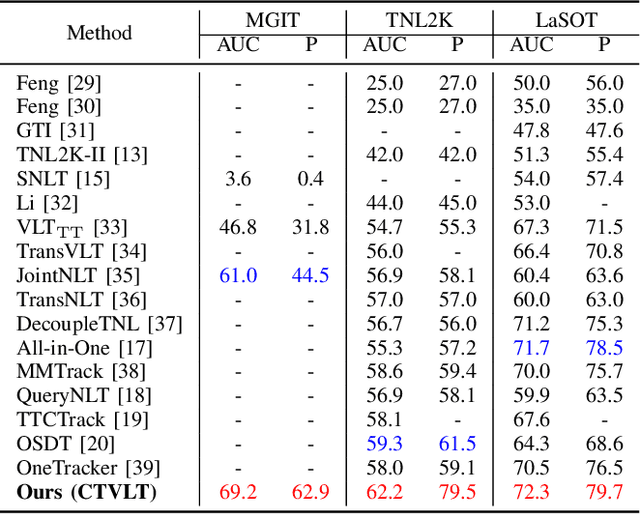
Vision-Language Tracking (VLT) aims to localize a target in video sequences using a visual template and language description. While textual cues enhance tracking potential, current datasets typically contain much more image data than text, limiting the ability of VLT methods to align the two modalities effectively. To address this imbalance, we propose a novel plug-and-play method named CTVLT that leverages the strong text-image alignment capabilities of foundation grounding models. CTVLT converts textual cues into interpretable visual heatmaps, which are easier for trackers to process. Specifically, we design a textual cue mapping module that transforms textual cues into target distribution heatmaps, visually representing the location described by the text. Additionally, the heatmap guidance module fuses these heatmaps with the search image to guide tracking more effectively. Extensive experiments on mainstream benchmarks demonstrate the effectiveness of our approach, achieving state-of-the-art performance and validating the utility of our method for enhanced VLT.
Beyond Imitation: A Life-long Policy Learning Framework for Path Tracking Control of Autonomous Driving
Apr 26, 2024Model-free learning-based control methods have recently shown significant advantages over traditional control methods in avoiding complex vehicle characteristic estimation and parameter tuning. As a primary policy learning method, imitation learning (IL) is capable of learning control policies directly from expert demonstrations. However, the performance of IL policies is highly dependent on the data sufficiency and quality of the demonstrations. To alleviate the above problems of IL-based policies, a lifelong policy learning (LLPL) framework is proposed in this paper, which extends the IL scheme with lifelong learning (LLL). First, a novel IL-based model-free control policy learning method for path tracking is introduced. Even with imperfect demonstration, the optimal control policy can be learned directly from historical driving data. Second, by using the LLL method, the pre-trained IL policy can be safely updated and fine-tuned with incremental execution knowledge. Third, a knowledge evaluation method for policy learning is introduced to avoid learning redundant or inferior knowledge, thus ensuring the performance improvement of online policy learning. Experiments are conducted using a high-fidelity vehicle dynamic model in various scenarios to evaluate the performance of the proposed method. The results show that the proposed LLPL framework can continuously improve the policy performance with collected incremental driving data, and achieves the best accuracy and control smoothness compared to other baseline methods after evolving on a 7 km curved road. Through learning and evaluation with noisy real-life data collected in an off-road environment, the proposed LLPL framework also demonstrates its applicability in learning and evolving in real-life scenarios.
Topic Scene Graph Generation by Attention Distillation from Caption
Oct 12, 2021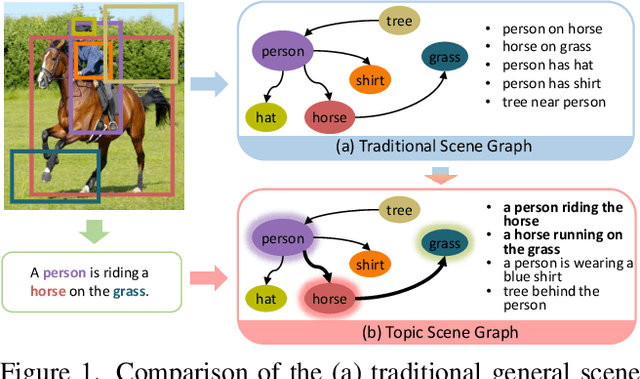
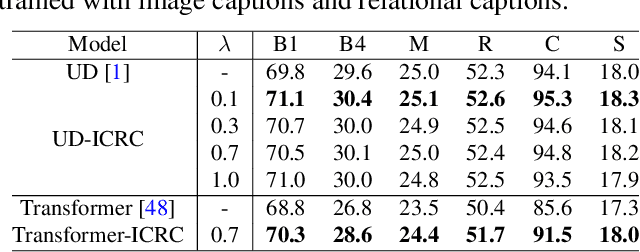
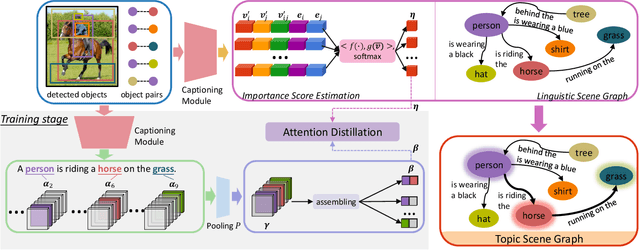
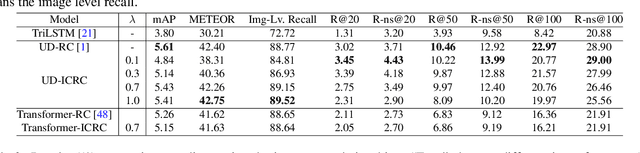
If an image tells a story, the image caption is the briefest narrator. Generally, a scene graph prefers to be an omniscient generalist, while the image caption is more willing to be a specialist, which outlines the gist. Lots of previous studies have found that a scene graph is not as practical as expected unless it can reduce the trivial contents and noises. In this respect, the image caption is a good tutor. To this end, we let the scene graph borrow the ability from the image caption so that it can be a specialist on the basis of remaining all-around, resulting in the so-called Topic Scene Graph. What an image caption pays attention to is distilled and passed to the scene graph for estimating the importance of partial objects, relationships, and events. Specifically, during the caption generation, the attention about individual objects in each time step is collected, pooled, and assembled to obtain the attention about relationships, which serves as weak supervision for regularizing the estimated importance scores of relationships. In addition, as this attention distillation process provides an opportunity for combining the generation of image caption and scene graph together, we further transform the scene graph into linguistic form with rich and free-form expressions by sharing a single generation model with image caption. Experiments show that attention distillation brings significant improvements in mining important relationships without strong supervision, and the topic scene graph shows great potential in subsequent applications.
Deep Learning to Estimate Permeability using Geophysical Data
Oct 08, 2021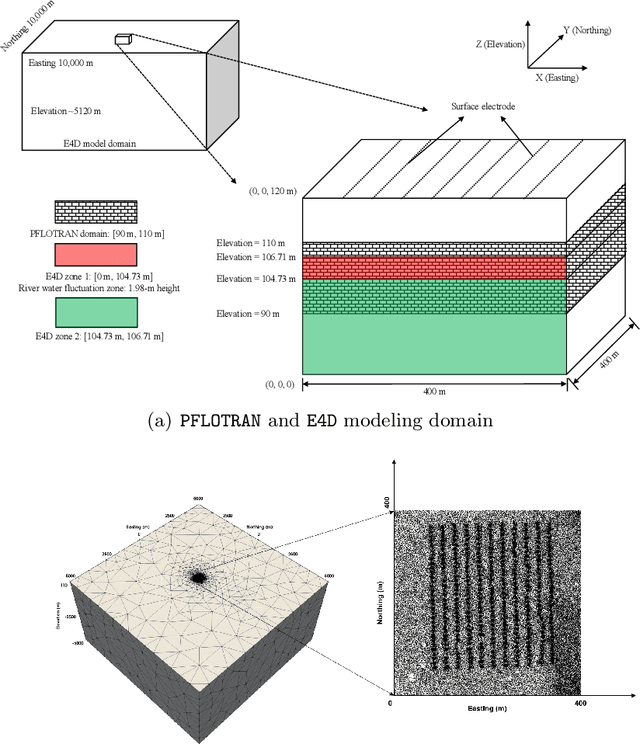
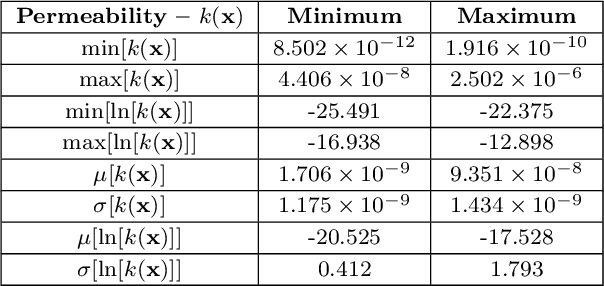
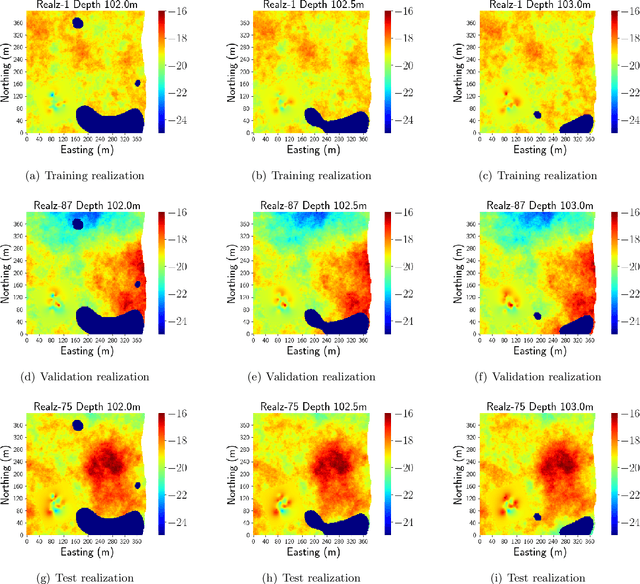

Time-lapse electrical resistivity tomography (ERT) is a popular geophysical method to estimate three-dimensional (3D) permeability fields from electrical potential difference measurements. Traditional inversion and data assimilation methods are used to ingest this ERT data into hydrogeophysical models to estimate permeability. Due to ill-posedness and the curse of dimensionality, existing inversion strategies provide poor estimates and low resolution of the 3D permeability field. Recent advances in deep learning provide us with powerful algorithms to overcome this challenge. This paper presents a deep learning (DL) framework to estimate the 3D subsurface permeability from time-lapse ERT data. To test the feasibility of the proposed framework, we train DL-enabled inverse models on simulation data. Subsurface process models based on hydrogeophysics are used to generate this synthetic data for deep learning analyses. Results show that proposed weak supervised learning can capture salient spatial features in the 3D permeability field. Quantitatively, the average mean squared error (in terms of the natural log) on the strongly labeled training, validation, and test datasets is less than 0.5. The R2-score (global metric) is greater than 0.75, and the percent error in each cell (local metric) is less than 10%. Finally, an added benefit in terms of computational cost is that the proposed DL-based inverse model is at least O(104) times faster than running a forward model. Note that traditional inversion may require multiple forward model simulations (e.g., in the order of 10 to 1000), which are very expensive. This computational savings (O(105) - O(107)) makes the proposed DL-based inverse model attractive for subsurface imaging and real-time ERT monitoring applications due to fast and yet reasonably accurate estimations of the permeability field.
SWAT Watershed Model Calibration using Deep Learning
Oct 06, 2021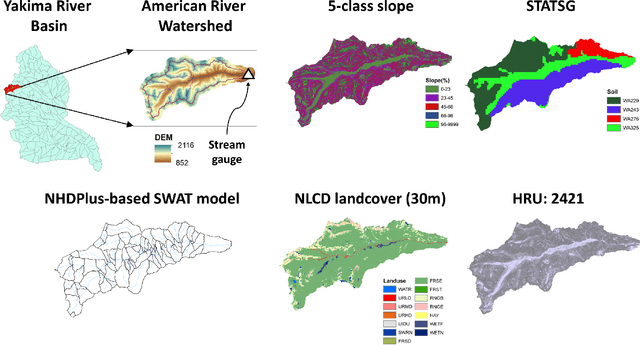
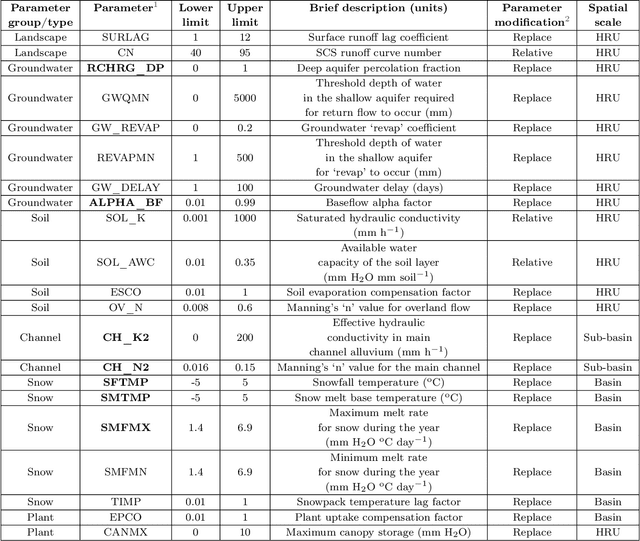
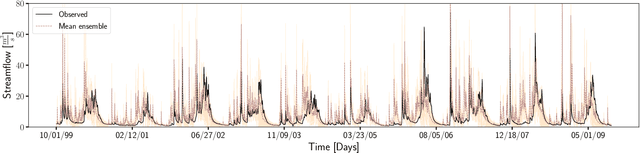

Watershed models such as the Soil and Water Assessment Tool (SWAT) consist of high-dimensional physical and empirical parameters. These parameters need to be accurately calibrated for models to produce reliable predictions for streamflow, evapotranspiration, snow water equivalent, and nutrient loading. Existing parameter estimation methods are time-consuming, inefficient, and computationally intensive, with reduced accuracy when estimating high-dimensional parameters. In this paper, we present a fast, accurate, and reliable methodology to calibrate the SWAT model (i.e., 21 parameters) using deep learning (DL). We develop DL-enabled inverse models based on convolutional neural networks to ingest streamflow data and estimate the SWAT model parameters. Hyperparameter tuning is performed to identify the optimal neural network architecture and the nine next best candidates. We use ensemble SWAT simulations to train, validate, and test the above DL models. We estimated the actual parameters of the SWAT model using observational data. We test and validate the proposed DL methodology on the American River Watershed, located in the Pacific Northwest-based Yakima River basin. Our results show that the DL models-based calibration is better than traditional parameter estimation methods, such as generalized likelihood uncertainty estimation (GLUE). The behavioral parameter sets estimated by DL have narrower ranges than GLUE and produce values within the sampling range even under high relative observational errors. This narrow range of parameters shows the reliability of the proposed workflow to estimate sensitive parameters accurately even under noise. Due to its fast and reasonably accurate estimations of process parameters, the proposed DL workflow is attractive for calibrating integrated hydrologic models for large spatial-scale applications.
Distributed Machine Learning for Wireless Communication Networks: Techniques, Architectures, and Applications
Dec 02, 2020
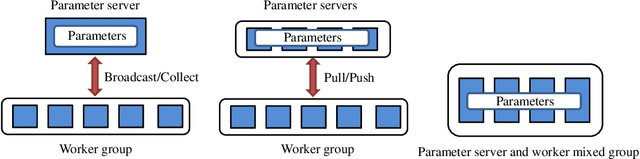
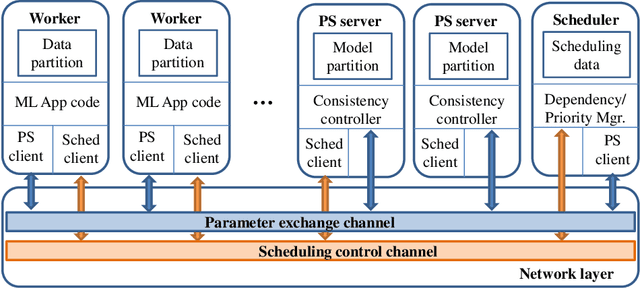
Distributed machine learning (DML) techniques, such as federated learning, partitioned learning, and distributed reinforcement learning, have been increasingly applied to wireless communications. This is due to improved capabilities of terminal devices, explosively growing data volume, congestion in the radio interfaces, and increasing concern of data privacy. The unique features of wireless systems, such as large scale, geographically dispersed deployment, user mobility, and massive amount of data, give rise to new challenges in the design of DML techniques. There is a clear gap in the existing literature in that the DML techniques are yet to be systematically reviewed for their applicability to wireless systems. This survey bridges the gap by providing a contemporary and comprehensive survey of DML techniques with a focus on wireless networks. Specifically, we review the latest applications of DML in power control, spectrum management, user association, and edge cloud computing. The optimality, scalability, convergence rate, computation cost, and communication overhead of DML are analyzed. We also discuss the potential adversarial attacks faced by DML applications, and describe state-of-the-art countermeasures to preserve privacy and security. Last but not least, we point out a number of key issues yet to be addressed, and collate potentially interesting and challenging topics for future research.
Autonomous Driving at Intersections: A Critical-Turning-Point Approach for Left Turns
Mar 05, 2020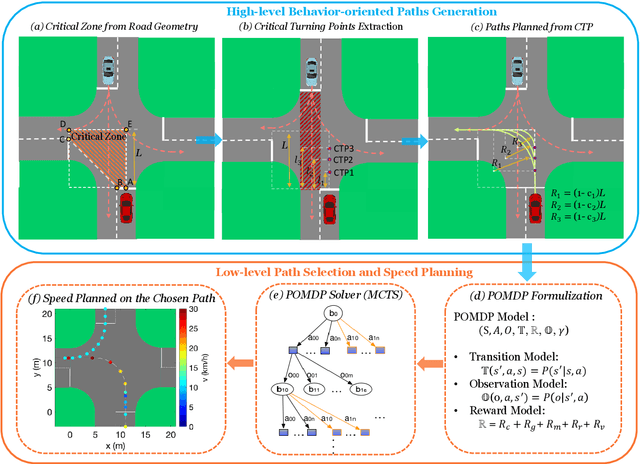
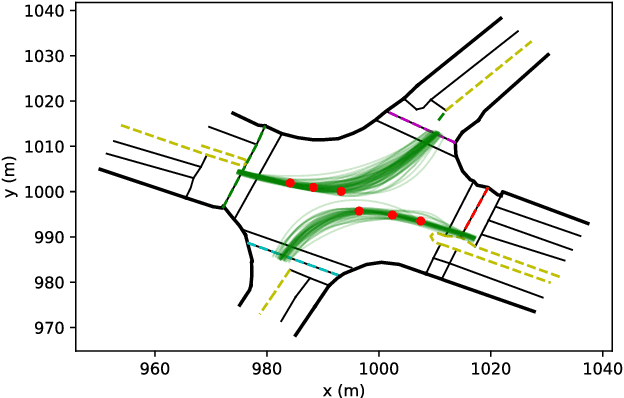
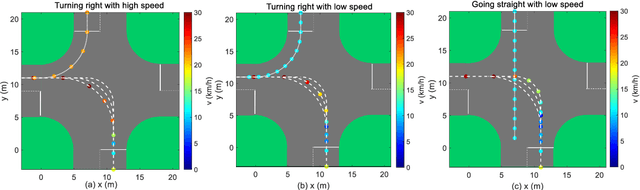
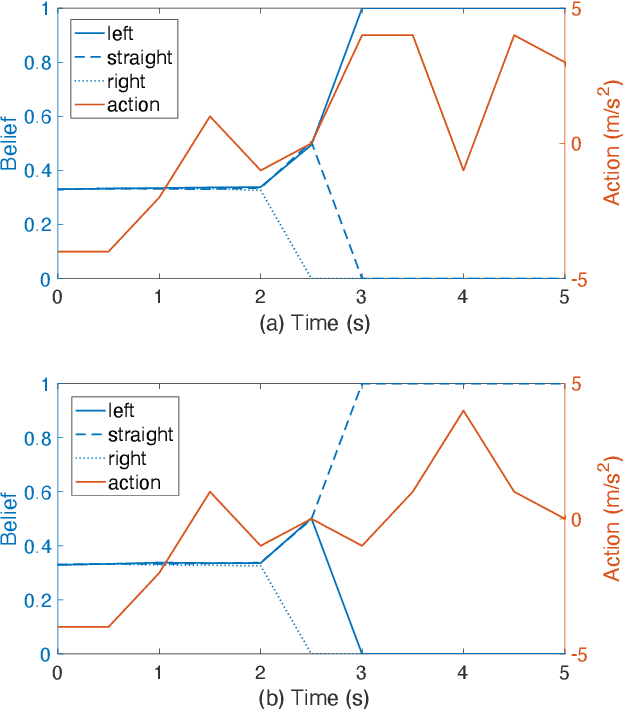
Left-turn planning is one of the formidable challenges for autonomous vehicles, especially at unsignalized intersections due to the unknown intentions of oncoming vehicles. This paper addresses the challenge by proposing a critical turning point (CTP) based hierarchical planning approach. This includes a high-level candidate path generator and a low-level partially observable Markov decision process (POMDP) based planner. The proposed (CTP) concept, inspired by human-driving behaviors at intersections, aims to increase the computational efficiency of the low-level planner and to enable human-friendly autonomous driving. The POMDP based low-level planner takes unknown intentions of oncoming vehicles into considerations to perform less conservative yet safe actions. With proper integration, the proposed hierarchical approach is capable of achieving safe planning results with high commute efficiency at unsignalized intersections in real time.
S$^{2}$OMGAN: Shortcut from Remote Sensing Images to Online Maps
Jan 21, 2020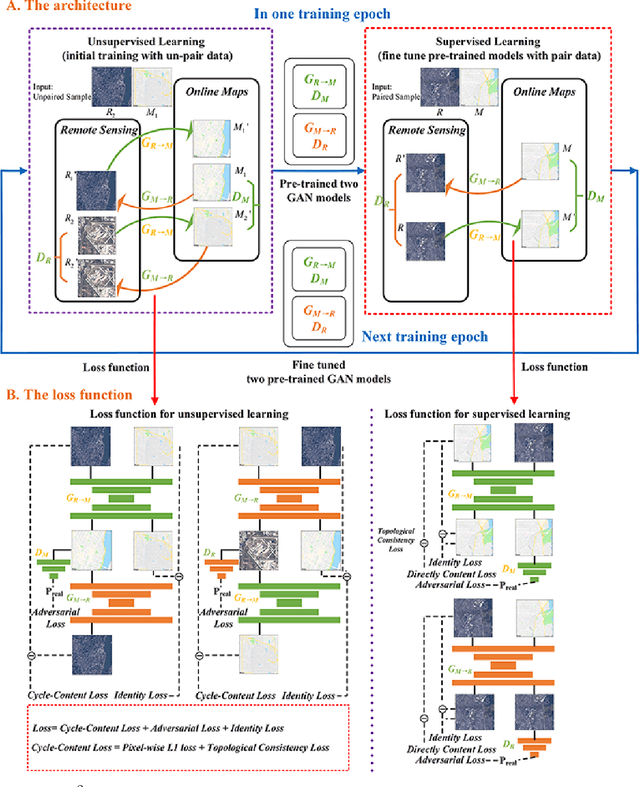
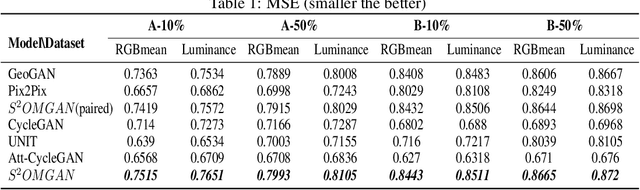
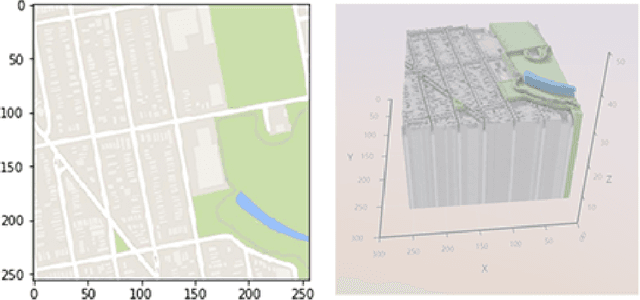
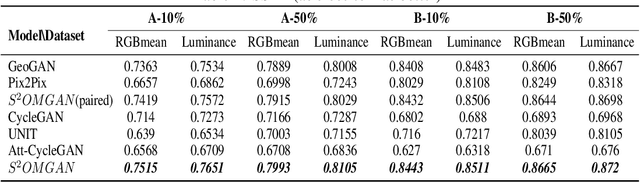
Traditional online maps, widely used on Internet such as Google map and Baidu map, are rendered from vector data. Timely updating online maps from vector data, of which the generating is time-consuming, is a difficult mission. It is a shortcut to generate online maps in time from remote sensing images, which can be acquired timely without vector data. However, this mission used to be challenging or even impossible. Inspired by image-to-image translation (img2img) techniques based on generative adversarial network (GAN), we propose a semi-supervised structure-augmented online map GAN (S$^{2}$OMGAN) model to generate online maps directly from remote sensing images. In this model, we designed a semi-supervised learning strategy to pre-train S$^{2}$OMGAN on rich unpaired samples and finetune it on limited paired samples in reality. We also designed image gradient L1 loss and image gradient structure loss to generate an online map with global topological relationship and detailed edge curves of objects, which are important in cartography. Moreover, we propose edge structural similarity index (ESSI) as a metric to evaluate the quality of topological consistency between generated online maps and ground truths. Experimental results present that S$^{2}$OMGAN outperforms state-of-the-art (SOTA) works according to mean squared error, structural similarity index and ESSI. Also, S$^{2}$OMGAN wins more approval than SOTA in the human perceptual test on visual realism of cartography. Our work shows that S$^{2}$OMGAN is potentially a new paradigm to produce online maps. Our implementation of the S$^{2}$OMGAN is available at \url{https://github.com/imcsq/S2OMGAN}.