 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyDeMiC: A Deep Learning-based Mineral Classifier using Hyperspectral Data
Jan 24, 2026Hyperspectral imaging (HSI) has emerged as a powerful remote sensing tool for mineral exploration, capitalizing on unique spectral signatures of minerals. However, traditional classification methods such as discriminant analysis, logistic regression, and support vector machines often struggle with environmental noise in data, sensor limitations, and the computational complexity of analyzing high-dimensional HSI data. This study presents HyDeMiC (Hyperspectral Deep Learning-based Mineral Classifier), a convolutional neural network (CNN) model designed for robust mineral classification under noisy data. To train HyDeMiC, laboratory-measured hyperspectral data for 115 minerals spanning various mineral groups were used from the United States Geological Survey (USGS) library. The training dataset was generated by convolving reference mineral spectra with an HSI sensor response function. These datasets contained three copper-bearing minerals, Cuprite, Malachite, and Chalcopyrite, used as case studies for performance demonstration. The trained CNN model was evaluated on several synthetic 2D hyperspectral datasets with noise levels of 1%, 2%, 5%, and 10%. Our noisy data analysis aims to replicate realistic field conditions. The HyDeMiC's performance was assessed using the Matthews Correlation Coefficient (MCC), providing a comprehensive measure across different noise regimes. Results demonstrate that HyDeMiC achieved near-perfect classification accuracy (MCC = 1.00) on clean and low-noise datasets and maintained strong performance under moderate noise conditions. These findings emphasize HyDeMiC's robustness in the presence of moderate noise, highlighting its potential for real-world applications in hyperspectral imaging, where noise is often a significant challenge.
CoolPINNs: A Physics-informed Neural Network Modeling of Active Cooling in Vascular Systems
Mar 09, 2023Emerging technologies like hypersonic aircraft, space exploration vehicles, and batteries avail fluid circulation in embedded microvasculatures for efficient thermal regulation. Modeling is vital during these engineered systems' design and operational phases. However, many challenges exist in developing a modeling framework. What is lacking is an accurate framework that (i) captures sharp jumps in the thermal flux across complex vasculature layouts, (ii) deals with oblique derivatives (involving tangential and normal components), (iii) handles nonlinearity because of radiative heat transfer, (iv) provides a high-speed forecast for real-time monitoring, and (v) facilitates robust inverse modeling. This paper addresses these challenges by availing the power of physics-informed neural networks (PINNs). We develop a fast, reliable, and accurate Scientific Machine Learning (SciML) framework for vascular-based thermal regulation -- called CoolPINNs: a PINNs-based modeling framework for active cooling. The proposed mesh-less framework elegantly overcomes all the mentioned challenges. The significance of the reported research is multi-fold. First, the framework is valuable for real-time monitoring of thermal regulatory systems because of rapid forecasting. Second, researchers can address complex thermoregulation designs inasmuch as the approach is mesh-less. Finally, the framework facilitates systematic parameter identification and inverse modeling studies, perhaps the current framework's most significant utility.
Deep Learning to Estimate Permeability using Geophysical Data
Oct 08, 2021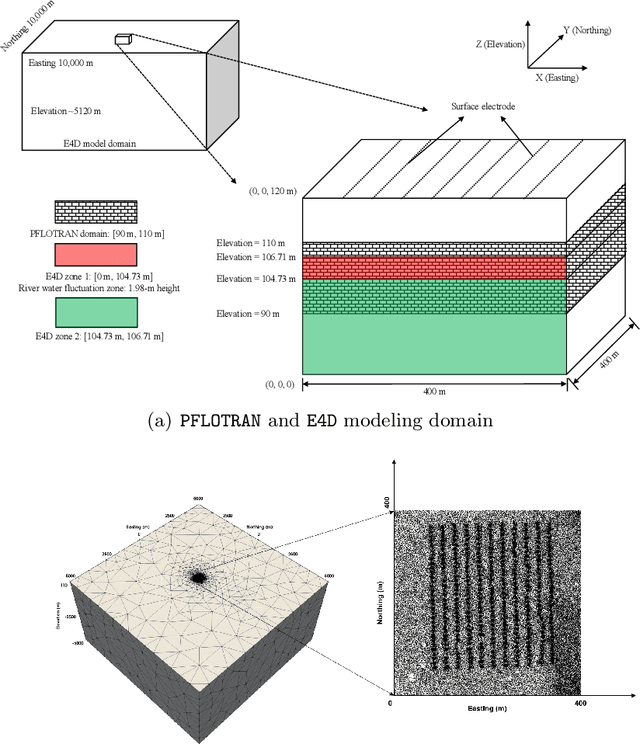
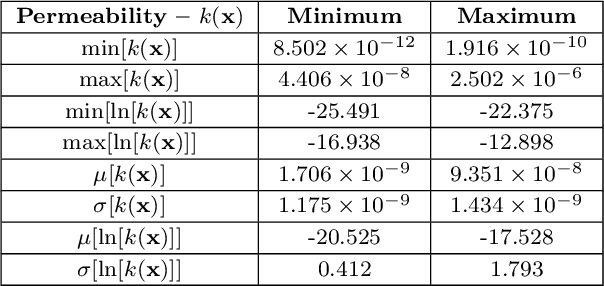
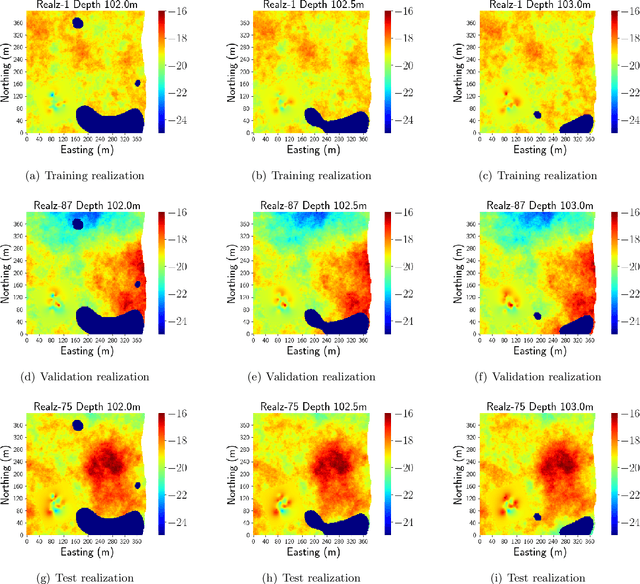

Time-lapse electrical resistivity tomography (ERT) is a popular geophysical method to estimate three-dimensional (3D) permeability fields from electrical potential difference measurements. Traditional inversion and data assimilation methods are used to ingest this ERT data into hydrogeophysical models to estimate permeability. Due to ill-posedness and the curse of dimensionality, existing inversion strategies provide poor estimates and low resolution of the 3D permeability field. Recent advances in deep learning provide us with powerful algorithms to overcome this challenge. This paper presents a deep learning (DL) framework to estimate the 3D subsurface permeability from time-lapse ERT data. To test the feasibility of the proposed framework, we train DL-enabled inverse models on simulation data. Subsurface process models based on hydrogeophysics are used to generate this synthetic data for deep learning analyses. Results show that proposed weak supervised learning can capture salient spatial features in the 3D permeability field. Quantitatively, the average mean squared error (in terms of the natural log) on the strongly labeled training, validation, and test datasets is less than 0.5. The R2-score (global metric) is greater than 0.75, and the percent error in each cell (local metric) is less than 10%. Finally, an added benefit in terms of computational cost is that the proposed DL-based inverse model is at least O(104) times faster than running a forward model. Note that traditional inversion may require multiple forward model simulations (e.g., in the order of 10 to 1000), which are very expensive. This computational savings (O(105) - O(107)) makes the proposed DL-based inverse model attractive for subsurface imaging and real-time ERT monitoring applications due to fast and yet reasonably accurate estimations of the permeability field.
SWAT Watershed Model Calibration using Deep Learning
Oct 06, 2021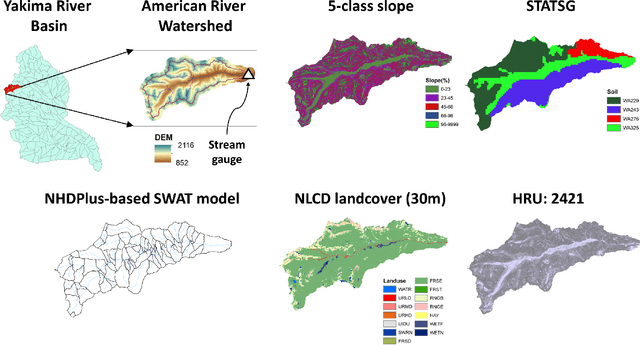
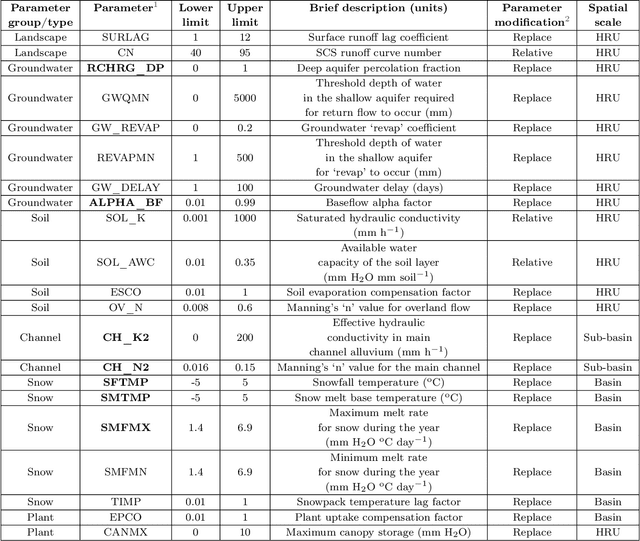
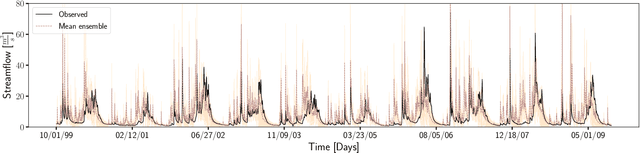

Watershed models such as the Soil and Water Assessment Tool (SWAT) consist of high-dimensional physical and empirical parameters. These parameters need to be accurately calibrated for models to produce reliable predictions for streamflow, evapotranspiration, snow water equivalent, and nutrient loading. Existing parameter estimation methods are time-consuming, inefficient, and computationally intensive, with reduced accuracy when estimating high-dimensional parameters. In this paper, we present a fast, accurate, and reliable methodology to calibrate the SWAT model (i.e., 21 parameters) using deep learning (DL). We develop DL-enabled inverse models based on convolutional neural networks to ingest streamflow data and estimate the SWAT model parameters. Hyperparameter tuning is performed to identify the optimal neural network architecture and the nine next best candidates. We use ensemble SWAT simulations to train, validate, and test the above DL models. We estimated the actual parameters of the SWAT model using observational data. We test and validate the proposed DL methodology on the American River Watershed, located in the Pacific Northwest-based Yakima River basin. Our results show that the DL models-based calibration is better than traditional parameter estimation methods, such as generalized likelihood uncertainty estimation (GLUE). The behavioral parameter sets estimated by DL have narrower ranges than GLUE and produce values within the sampling range even under high relative observational errors. This narrow range of parameters shows the reliability of the proposed workflow to estimate sensitive parameters accurately even under noise. Due to its fast and reasonably accurate estimations of process parameters, the proposed DL workflow is attractive for calibrating integrated hydrologic models for large spatial-scale applications.
A deep learning modeling framework to capture mixing patterns in reactive-transport systems
Jan 11, 2021
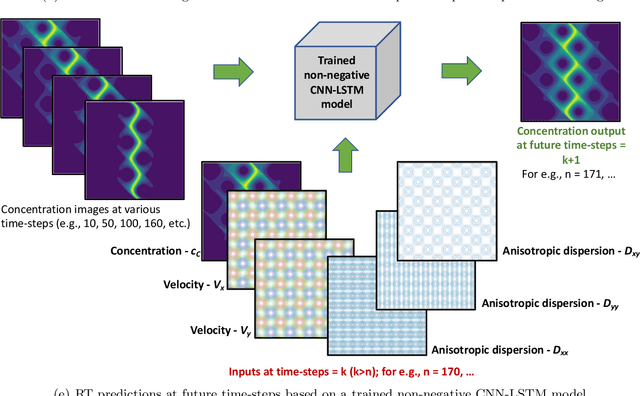


Prediction and control of chemical mixing are vital for many scientific areas such as subsurface reactive transport, climate modeling, combustion, epidemiology, and pharmacology. Due to the complex nature of mixing in heterogeneous and anisotropic media, the mathematical models related to this phenomenon are not analytically tractable. Numerical simulations often provide a viable route to predict chemical mixing accurately. However, contemporary modeling approaches for mixing cannot utilize available spatial-temporal data to improve the accuracy of the future prediction and can be compute-intensive, especially when the spatial domain is large and for long-term temporal predictions. To address this knowledge gap, we will present in this paper a deep-learning (DL) modeling framework applied to predict the progress of chemical mixing under fast bimolecular reactions. This framework uses convolutional neural networks (CNN) for capturing spatial patterns and long short-term memory (LSTM) networks for forecasting temporal variations in mixing. By careful design of the framework -- placement of non-negative constraint on the weights of the CNN and the selection of activation function, the framework ensures non-negativity of the chemical species at all spatial points and for all times. Our DL-based framework is fast, accurate, and requires minimal data for training.
A Comparative Study of Machine Learning Models for Predicting the State of Reactive Mixing
Feb 24, 2020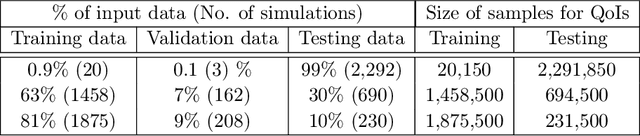

Accurate predictions of reactive mixing are critical for many Earth and environmental science problems. To investigate mixing dynamics over time under different scenarios, a high-fidelity, finite-element-based numerical model is built to solve the fast, irreversible bimolecular reaction-diffusion equations to simulate a range of reactive-mixing scenarios. A total of 2,315 simulations are performed using different sets of model input parameters comprising various spatial scales of vortex structures in the velocity field, time-scales associated with velocity oscillations, the perturbation parameter for the vortex-based velocity, anisotropic dispersion contrast, and molecular diffusion. Outputs comprise concentration profiles of the reactants and products. The inputs and outputs of these simulations are concatenated into feature and label matrices, respectively, to train 20 different machine learning (ML) emulators to approximate system behavior. The 20 ML emulators based on linear methods, Bayesian methods, ensemble learning methods, and multilayer perceptron (MLP), are compared to assess these models. The ML emulators are specifically trained to classify the state of mixing and predict three quantities of interest (QoIs) characterizing species production, decay, and degree of mixing. Linear classifiers and regressors fail to reproduce the QoIs; however, ensemble methods (classifiers and regressors) and the MLP accurately classify the state of reactive mixing and the QoIs. Among ensemble methods, random forest and decision-tree-based AdaBoost faithfully predict the QoIs. At run time, trained ML emulators are $\approx10^5$ times faster than the high-fidelity numerical simulations. Speed and accuracy of the ensemble and MLP models facilitate uncertainty quantification, which usually requires 1,000s of model run, to estimate the uncertainty bounds on the QoIs.
Physics-Informed Machine Learning Models for Predicting the Progress of Reactive-Mixing
Aug 28, 2019
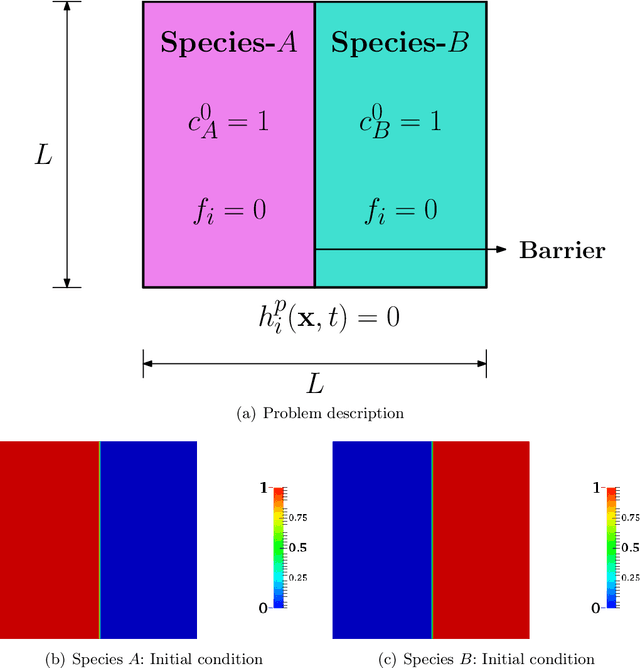

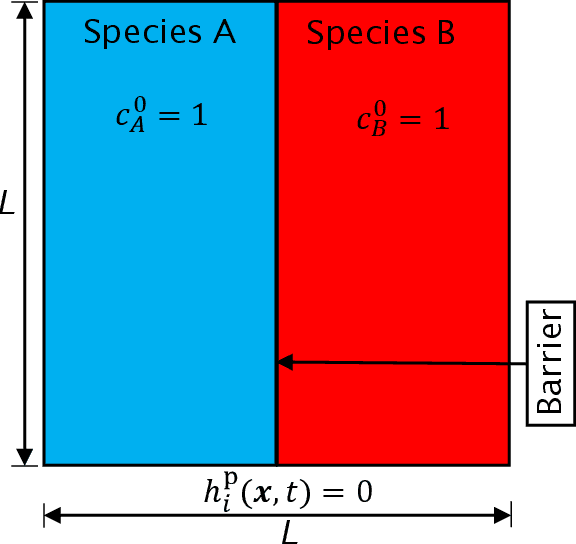
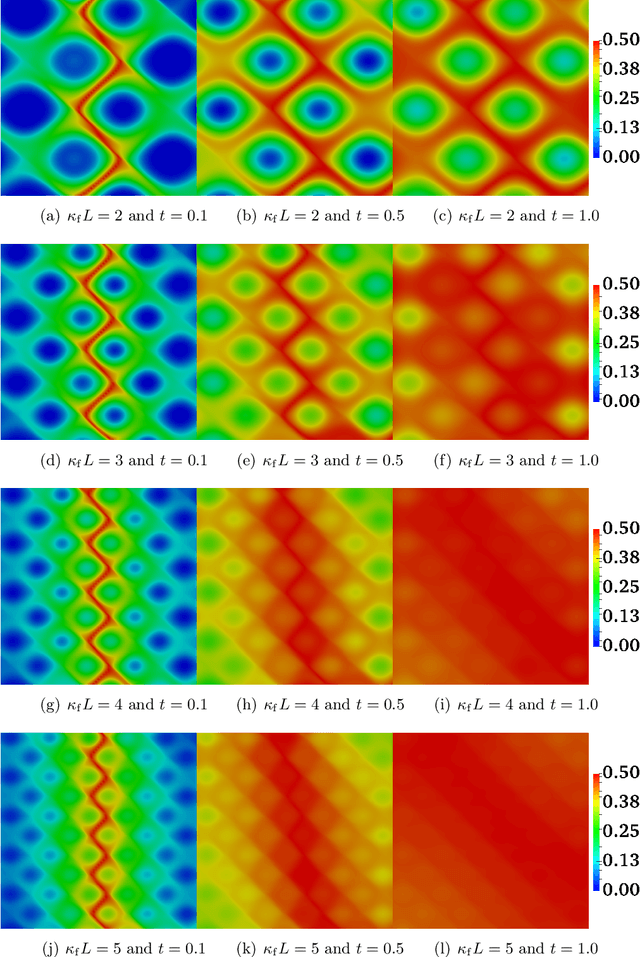
This paper presents a physics-informed machine learning (ML) framework to construct reduced-order models (ROMs) for reactive-transport quantities of interest (QoIs) based on high-fidelity numerical simulations. QoIs include species decay, product yield, and degree of mixing. The ROMs for QoIs are applied to quantify and understand how the chemical species evolve over time. First, high-resolution datasets for constructing ROMs are generated by solving anisotropic reaction-diffusion equations using a non-negative finite element formulation for different input parameters. Non-negative finite element formulation ensures that the species concentration is non-negative (which is needed for computing QoIs) on coarse computational grids even under high anisotropy. The reactive-mixing model input parameters are a time-scale associated with flipping of velocity, a spatial-scale controlling small/large vortex structures of velocity, a perturbation parameter of the vortex-based velocity, anisotropic dispersion strength/contrast, and molecular diffusion. Second, random forests, F-test, and mutual information criterion are used to evaluate the importance of model inputs/features with respect to QoIs. Third, Support Vector Machines (SVM) and Support Vector Regression (SVR) are used to construct ROMs based on the model inputs. Then, SVR-ROMs are used to predict scaling of QoIs. Qualitatively, SVR-ROMs are able to describe the trends observed in the scaling law associated with QoIs. Fourth, the scaling law's exponent dependence on model inputs/features are evaluated using $k$-means clustering. Finally, in terms of the computational cost, the proposed SVM-ROMs and SVR-ROMs are $\mathcal{O}(10^7)$ times faster than running a high-fidelity numerical simulation for evaluating QoIs.
Using Machine Learning to Discern Eruption in Noisy Environments: A Case Study using CO2-driven Cold-Water Geyser in Chimayo, New Mexico
Oct 01, 2018


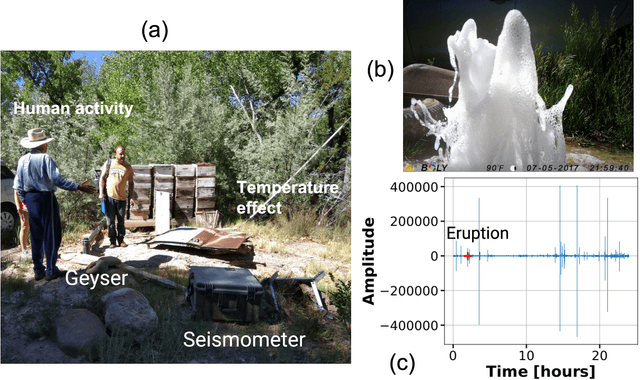
We present an approach based on machine learning (ML) to distinguish eruption and precursory signals of Chimay\'{o} geyser (New Mexico, USA) under noisy environments. This geyser can be considered as a natural analog of $\mathrm{CO}_2$ intrusion into shallow water aquifers. By studying this geyser, we can understand upwelling of $\mathrm{CO}_2$-rich fluids from depth, which has relevance to leak monitoring in a $\mathrm{CO}_2$ sequestration project. ML methods such as Random Forests (RF) are known to be robust multi-class classifiers and perform well under unfavorable noisy conditions. However, the extent of the RF method's accuracy is poorly understood for this $\mathrm{CO}_2$-driven geysering application. The current study aims to quantify the performance of RF-classifiers to discern the geyser state. Towards this goal, we first present the data collected from the seismometer that is installed near the Chimay\'{o} geyser. The seismic signals collected at this site contain different types of noises such as daily temperature variations, seasonal trends, animal movement near the geyser, and human activity. First, we filter the signals from these noises by combining the Butterworth-Highpass filter and an Autoregressive method in a multi-level fashion. We show that by combining these filtering techniques, in a hierarchical fashion, leads to reduction in the noise in the seismic data without removing the precursors and eruption event signals. We then use RF on the filtered data to classify the state of geyser into three classes -- remnant noise, precursor, and eruption states. We show that the classification accuracy using RF on the filtered data is greater than 90\%.These aspects make the proposed ML framework attractive for event discrimination and signal enhancement under noisy conditions, with strong potential for application to monitoring leaks in $\mathrm{CO}_2$ sequestration.
Estimating Failure in Brittle Materials using Graph Theory
Jul 30, 2018
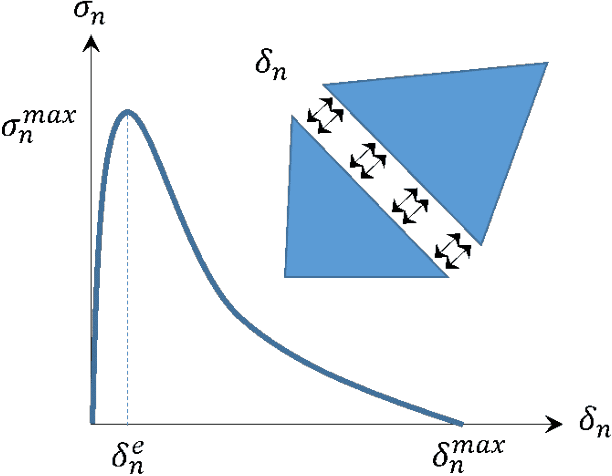
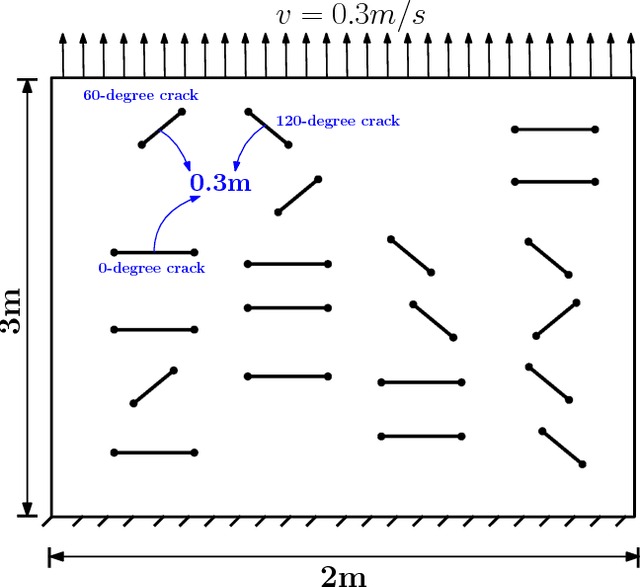
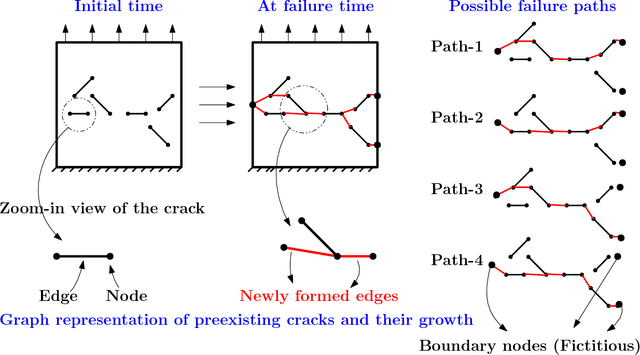
In brittle fracture applications, failure paths, regions where the failure occurs and damage statistics, are some of the key quantities of interest (QoI). High-fidelity models for brittle failure that accurately predict these QoI exist but are highly computationally intensive, making them infeasible to incorporate in upscaling and uncertainty quantification frameworks. The goal of this paper is to provide a fast heuristic to reasonably estimate quantities such as failure path and damage in the process of brittle failure. Towards this goal, we first present a method to predict failure paths under tensile loading conditions and low-strain rates. The method uses a $k$-nearest neighbors algorithm built on fracture process zone theory, and identifies the set of all possible pre-existing cracks that are likely to join early to form a large crack. The method then identifies zone of failure and failure paths using weighted graphs algorithms. We compare these failure paths to those computed with a high-fidelity model called the Hybrid Optimization Software Simulation Suite (HOSS). A probabilistic evolution model for average damage in a system is also developed that is trained using 150 HOSS simulations and tested on 40 simulations. A non-parametric approach based on confidence intervals is used to determine the damage evolution over time along the dominant failure path. For upscaling, damage is the key QoI needed as an input by the continuum models. This needs to be informed accurately by the surrogate models for calculating effective modulii at continuum-scale. We show that for the proposed average damage evolution model, the prediction accuracy on the test data is more than 90\%. In terms of the computational time, the proposed models are $\approx \mathcal{O}(10^6)$ times faster compared to high-fidelity HOSS.
Reduced-Order Modeling through Machine Learning Approaches for Brittle Fracture Applications
Jun 05, 2018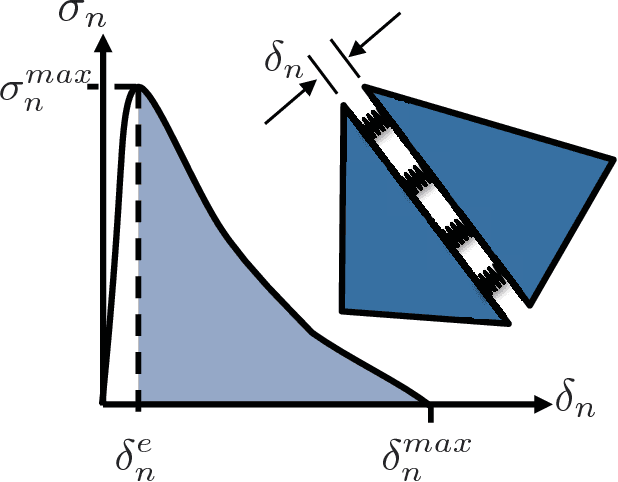
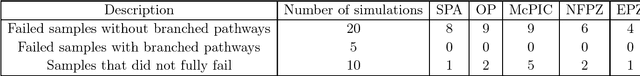

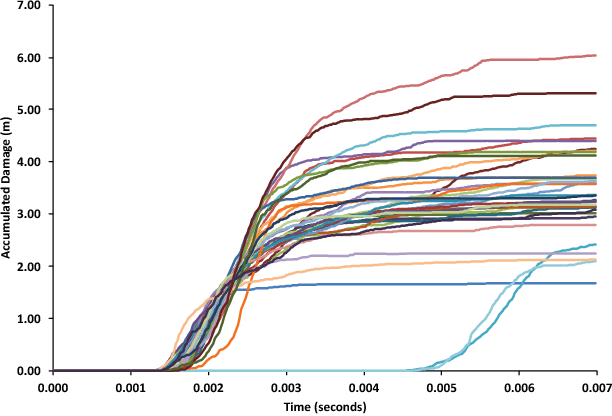
In this paper, five different approaches for reduced-order modeling of brittle fracture in geomaterials, specifically concrete, are presented and compared. Four of the five methods rely on machine learning (ML) algorithms to approximate important aspects of the brittle fracture problem. In addition to the ML algorithms, each method incorporates different physics-based assumptions in order to reduce the computational complexity while maintaining the physics as much as possible. This work specifically focuses on using the ML approaches to model a 2D concrete sample under low strain rate pure tensile loading conditions with 20 preexisting cracks present. A high-fidelity finite element-discrete element model is used to both produce a training dataset of 150 simulations and an additional 35 simulations for validation. Results from the ML approaches are directly compared against the results from the high-fidelity model. Strengths and weaknesses of each approach are discussed and the most important conclusion is that a combination of physics-informed and data-driven features are necessary for emulating the physics of crack propagation, interaction and coalescence. All of the models presented here have runtimes that are orders of magnitude faster than the original high-fidelity model and pave the path for developing accurate reduced order models that could be used to inform larger length-scale models with important sub-scale physics that often cannot be accounted for due to computational cost.