 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comparative Study of Machine Learning Models for Predicting the State of Reactive Mixing
Feb 24, 2020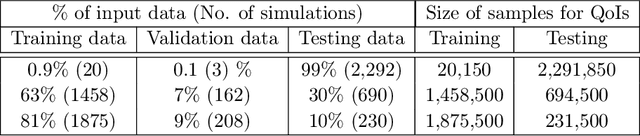
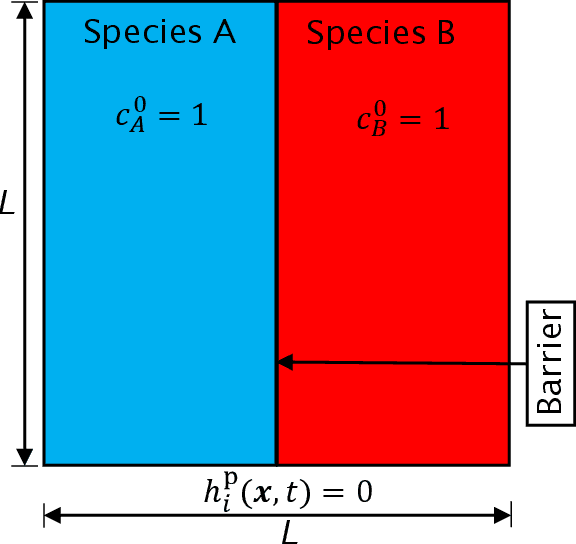

Accurate predictions of reactive mixing are critical for many Earth and environmental science problems. To investigate mixing dynamics over time under different scenarios, a high-fidelity, finite-element-based numerical model is built to solve the fast, irreversible bimolecular reaction-diffusion equations to simulate a range of reactive-mixing scenarios. A total of 2,315 simulations are performed using different sets of model input parameters comprising various spatial scales of vortex structures in the velocity field, time-scales associated with velocity oscillations, the perturbation parameter for the vortex-based velocity, anisotropic dispersion contrast, and molecular diffusion. Outputs comprise concentration profiles of the reactants and products. The inputs and outputs of these simulations are concatenated into feature and label matrices, respectively, to train 20 different machine learning (ML) emulators to approximate system behavior. The 20 ML emulators based on linear methods, Bayesian methods, ensemble learning methods, and multilayer perceptron (MLP), are compared to assess these models. The ML emulators are specifically trained to classify the state of mixing and predict three quantities of interest (QoIs) characterizing species production, decay, and degree of mixing. Linear classifiers and regressors fail to reproduce the QoIs; however, ensemble methods (classifiers and regressors) and the MLP accurately classify the state of reactive mixing and the QoIs. Among ensemble methods, random forest and decision-tree-based AdaBoost faithfully predict the QoIs. At run time, trained ML emulators are $\approx10^5$ times faster than the high-fidelity numerical simulations. Speed and accuracy of the ensemble and MLP models facilitate uncertainty quantification, which usually requires 1,000s of model run, to estimate the uncertainty bounds on the QoIs.
Unsupervised Machine Learning Based on Non-Negative Tensor Factorization for Analyzing Reactive-Mixing
May 16, 2018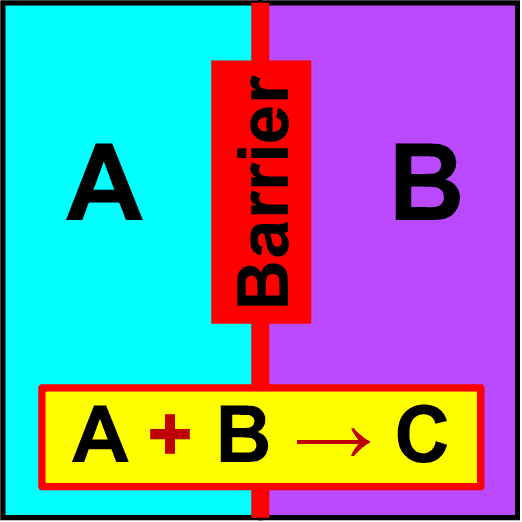
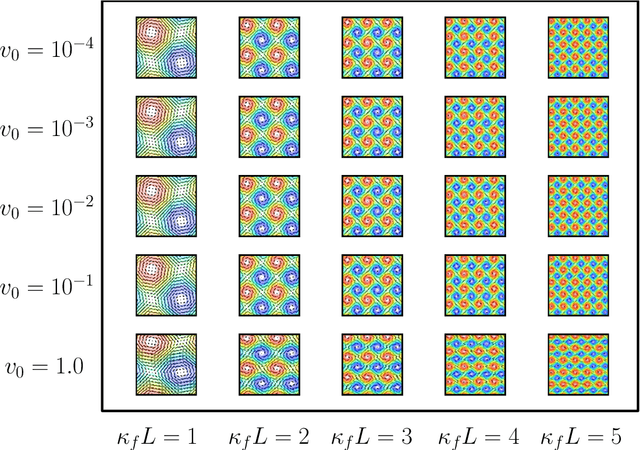
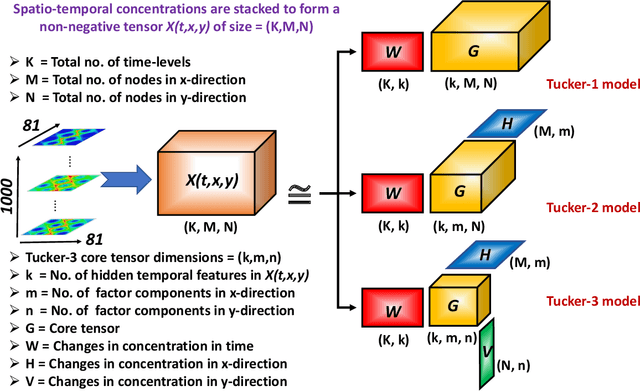

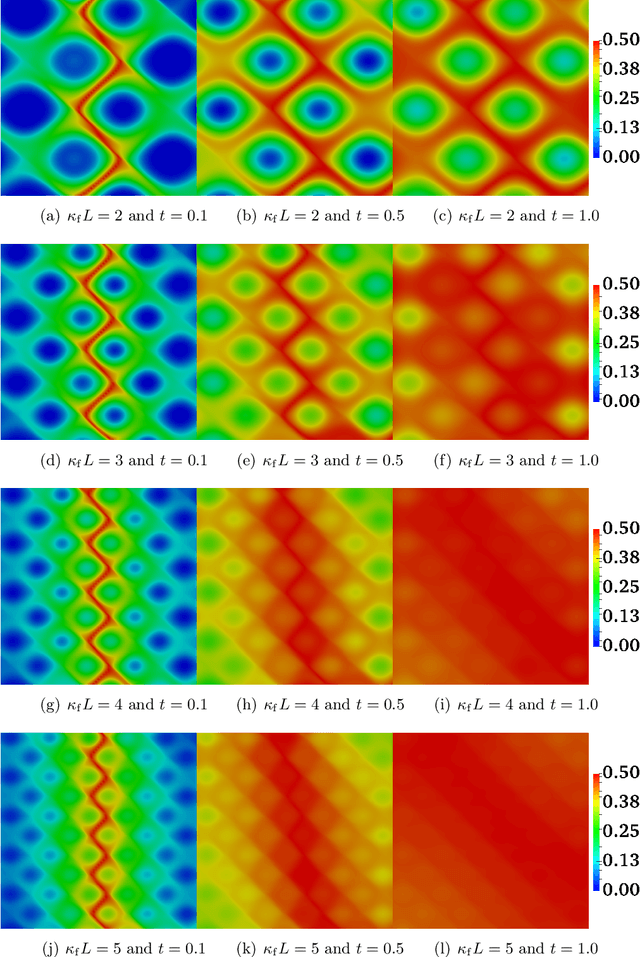
Analysis of reactive-diffusion simulations requires a large number of independent model runs. For each high-fidelity simulation, inputs are varied and the predicted mixing behavior is represented by changes in species concentration. It is then required to discern how the model inputs impact the mixing process. This task is challenging and typically involves interpretation of large model outputs. However, the task can be automated and substantially simplified by applying Machine Learning (ML) methods. In this paper, we present an application of an unsupervised ML method (called NTFk) using Non-negative Tensor Factorization (NTF) coupled with a custom clustering procedure based on k-means to reveal hidden features in product concentration. An attractive aspect of the proposed ML method is that it ensures the extracted features are non-negative, which are important to obtain a meaningful deconstruction of the mixing processes. The ML method is applied to a large set of high-resolution FEM simulations representing reaction-diffusion processes in perturbed vortex-based velocity fields. The applied FEM ensures that species concentration are always non-negative. The simulated reaction is a fast irreversible bimolecular reaction. The reactive-diffusion model input parameters that control mixing include properties of velocity field, anisotropic dispersion, and molecular diffusion. We demonstrate the applicability of the ML method to produce a meaningful deconstruction of model outputs to discriminate between different physical processes impacting the reactants, their mixing, and the spatial distribution of the product. The presented ML analysis allowed us to identify additive features that characterize mixing behavior.