 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comparative Study of Machine Learning Models for Predicting the State of Reactive Mixing
Feb 24, 2020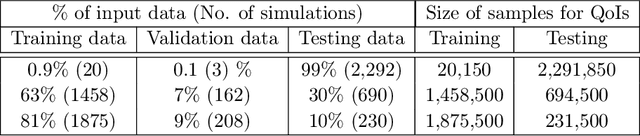
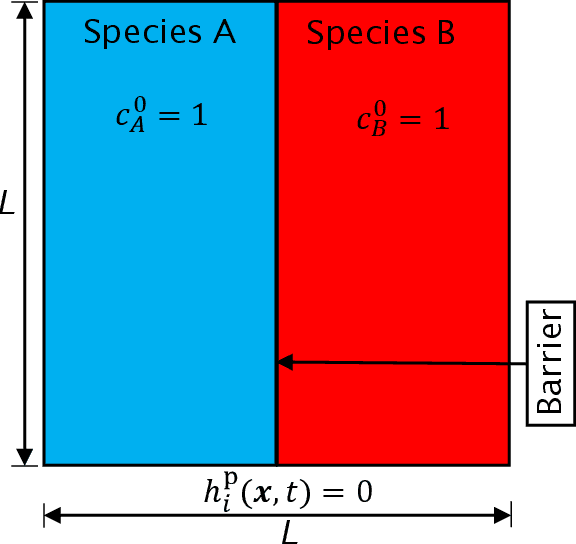

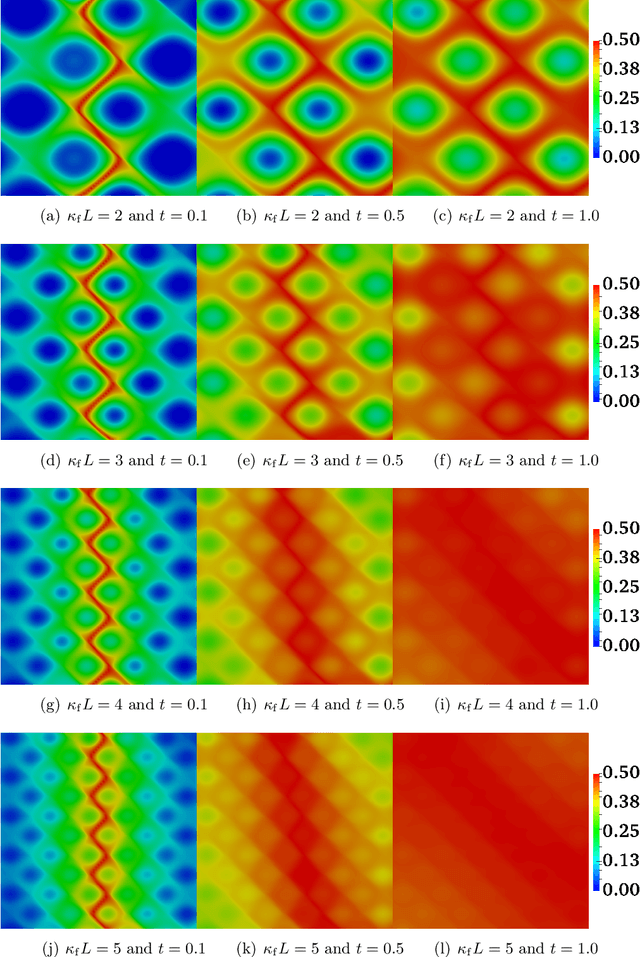
Accurate predictions of reactive mixing are critical for many Earth and environmental science problems. To investigate mixing dynamics over time under different scenarios, a high-fidelity, finite-element-based numerical model is built to solve the fast, irreversible bimolecular reaction-diffusion equations to simulate a range of reactive-mixing scenarios. A total of 2,315 simulations are performed using different sets of model input parameters comprising various spatial scales of vortex structures in the velocity field, time-scales associated with velocity oscillations, the perturbation parameter for the vortex-based velocity, anisotropic dispersion contrast, and molecular diffusion. Outputs comprise concentration profiles of the reactants and products. The inputs and outputs of these simulations are concatenated into feature and label matrices, respectively, to train 20 different machine learning (ML) emulators to approximate system behavior. The 20 ML emulators based on linear methods, Bayesian methods, ensemble learning methods, and multilayer perceptron (MLP), are compared to assess these models. The ML emulators are specifically trained to classify the state of mixing and predict three quantities of interest (QoIs) characterizing species production, decay, and degree of mixing. Linear classifiers and regressors fail to reproduce the QoIs; however, ensemble methods (classifiers and regressors) and the MLP accurately classify the state of reactive mixing and the QoIs. Among ensemble methods, random forest and decision-tree-based AdaBoost faithfully predict the QoIs. At run time, trained ML emulators are $\approx10^5$ times faster than the high-fidelity numerical simulations. Speed and accuracy of the ensemble and MLP models facilitate uncertainty quantification, which usually requires 1,000s of model run, to estimate the uncertainty bounds on the QoIs.
Physics-Informed Machine Learning Models for Predicting the Progress of Reactive-Mixing
Aug 28, 2019
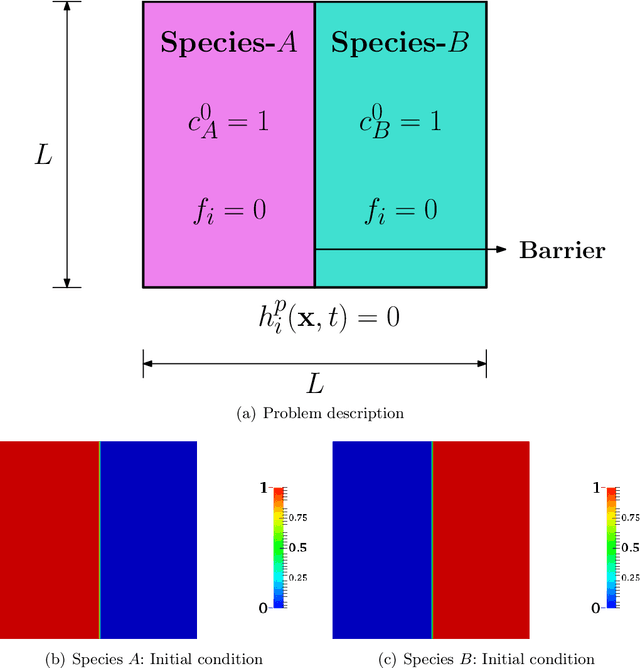

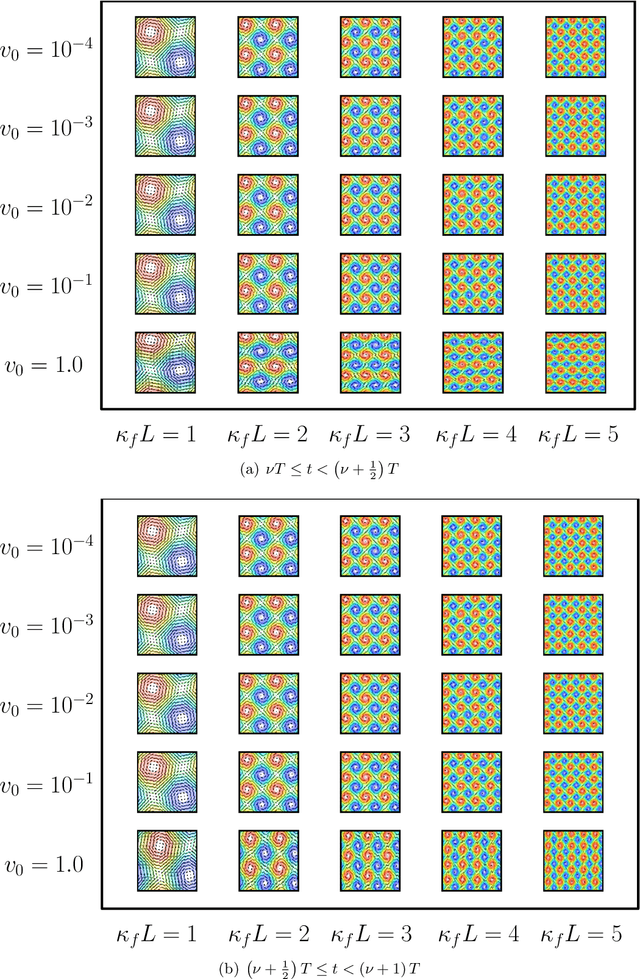
This paper presents a physics-informed machine learning (ML) framework to construct reduced-order models (ROMs) for reactive-transport quantities of interest (QoIs) based on high-fidelity numerical simulations. QoIs include species decay, product yield, and degree of mixing. The ROMs for QoIs are applied to quantify and understand how the chemical species evolve over time. First, high-resolution datasets for constructing ROMs are generated by solving anisotropic reaction-diffusion equations using a non-negative finite element formulation for different input parameters. Non-negative finite element formulation ensures that the species concentration is non-negative (which is needed for computing QoIs) on coarse computational grids even under high anisotropy. The reactive-mixing model input parameters are a time-scale associated with flipping of velocity, a spatial-scale controlling small/large vortex structures of velocity, a perturbation parameter of the vortex-based velocity, anisotropic dispersion strength/contrast, and molecular diffusion. Second, random forests, F-test, and mutual information criterion are used to evaluate the importance of model inputs/features with respect to QoIs. Third, Support Vector Machines (SVM) and Support Vector Regression (SVR) are used to construct ROMs based on the model inputs. Then, SVR-ROMs are used to predict scaling of QoIs. Qualitatively, SVR-ROMs are able to describe the trends observed in the scaling law associated with QoIs. Fourth, the scaling law's exponent dependence on model inputs/features are evaluated using $k$-means clustering. Finally, in terms of the computational cost, the proposed SVM-ROMs and SVR-ROMs are $\mathcal{O}(10^7)$ times faster than running a high-fidelity numerical simulation for evaluating QoIs.
Using Machine Learning to Discern Eruption in Noisy Environments: A Case Study using CO2-driven Cold-Water Geyser in Chimayo, New Mexico
Oct 01, 2018


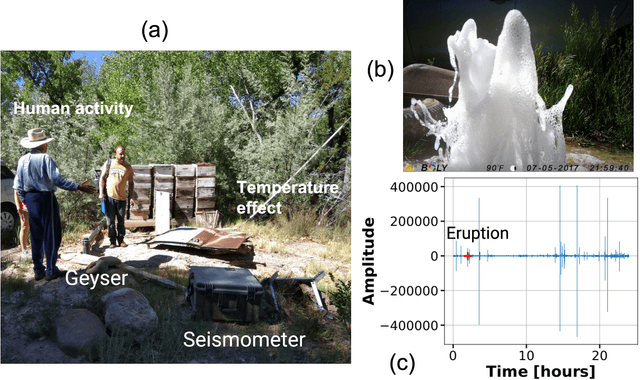
We present an approach based on machine learning (ML) to distinguish eruption and precursory signals of Chimay\'{o} geyser (New Mexico, USA) under noisy environments. This geyser can be considered as a natural analog of $\mathrm{CO}_2$ intrusion into shallow water aquifers. By studying this geyser, we can understand upwelling of $\mathrm{CO}_2$-rich fluids from depth, which has relevance to leak monitoring in a $\mathrm{CO}_2$ sequestration project. ML methods such as Random Forests (RF) are known to be robust multi-class classifiers and perform well under unfavorable noisy conditions. However, the extent of the RF method's accuracy is poorly understood for this $\mathrm{CO}_2$-driven geysering application. The current study aims to quantify the performance of RF-classifiers to discern the geyser state. Towards this goal, we first present the data collected from the seismometer that is installed near the Chimay\'{o} geyser. The seismic signals collected at this site contain different types of noises such as daily temperature variations, seasonal trends, animal movement near the geyser, and human activity. First, we filter the signals from these noises by combining the Butterworth-Highpass filter and an Autoregressive method in a multi-level fashion. We show that by combining these filtering techniques, in a hierarchical fashion, leads to reduction in the noise in the seismic data without removing the precursors and eruption event signals. We then use RF on the filtered data to classify the state of geyser into three classes -- remnant noise, precursor, and eruption states. We show that the classification accuracy using RF on the filtered data is greater than 90\%.These aspects make the proposed ML framework attractive for event discrimination and signal enhancement under noisy conditions, with strong potential for application to monitoring leaks in $\mathrm{CO}_2$ sequestration.
Estimating Failure in Brittle Materials using Graph Theory
Jul 30, 2018
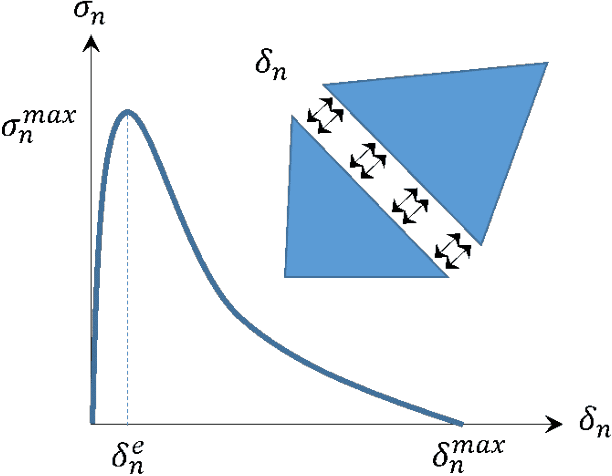
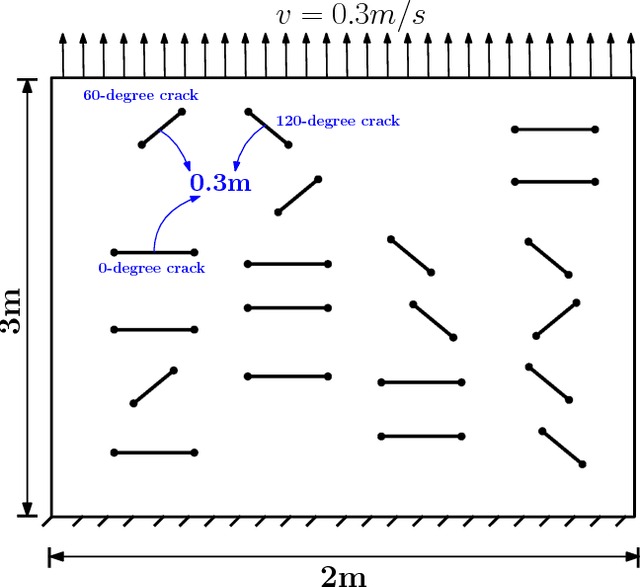
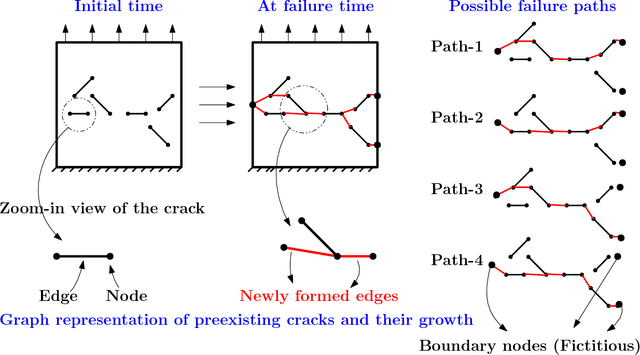
In brittle fracture applications, failure paths, regions where the failure occurs and damage statistics, are some of the key quantities of interest (QoI). High-fidelity models for brittle failure that accurately predict these QoI exist but are highly computationally intensive, making them infeasible to incorporate in upscaling and uncertainty quantification frameworks. The goal of this paper is to provide a fast heuristic to reasonably estimate quantities such as failure path and damage in the process of brittle failure. Towards this goal, we first present a method to predict failure paths under tensile loading conditions and low-strain rates. The method uses a $k$-nearest neighbors algorithm built on fracture process zone theory, and identifies the set of all possible pre-existing cracks that are likely to join early to form a large crack. The method then identifies zone of failure and failure paths using weighted graphs algorithms. We compare these failure paths to those computed with a high-fidelity model called the Hybrid Optimization Software Simulation Suite (HOSS). A probabilistic evolution model for average damage in a system is also developed that is trained using 150 HOSS simulations and tested on 40 simulations. A non-parametric approach based on confidence intervals is used to determine the damage evolution over time along the dominant failure path. For upscaling, damage is the key QoI needed as an input by the continuum models. This needs to be informed accurately by the surrogate models for calculating effective modulii at continuum-scale. We show that for the proposed average damage evolution model, the prediction accuracy on the test data is more than 90\%. In terms of the computational time, the proposed models are $\approx \mathcal{O}(10^6)$ times faster compared to high-fidelity HOSS.
Reduced-Order Modeling through Machine Learning Approaches for Brittle Fracture Applications
Jun 05, 2018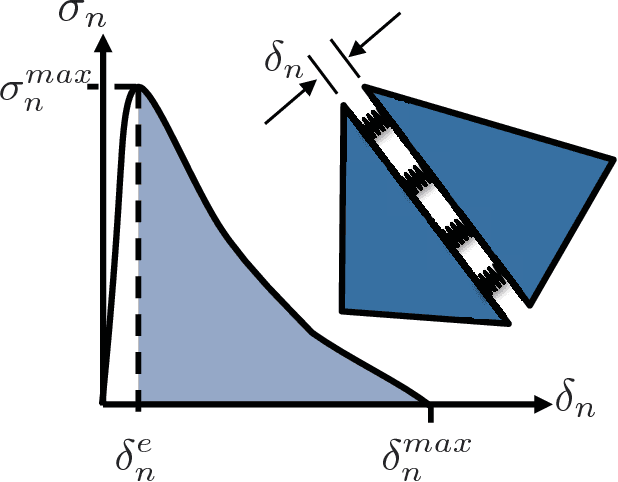
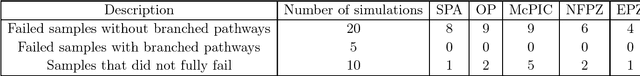

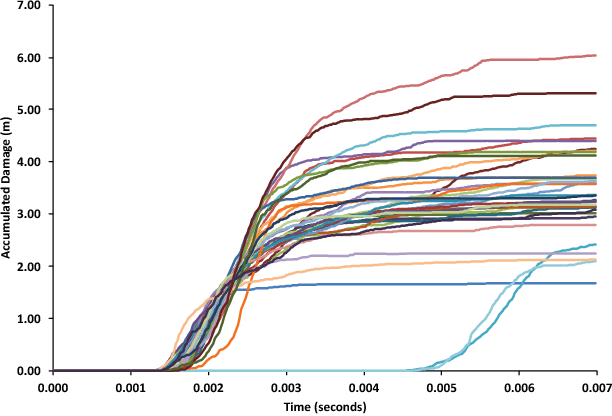
In this paper, five different approaches for reduced-order modeling of brittle fracture in geomaterials, specifically concrete, are presented and compared. Four of the five methods rely on machine learning (ML) algorithms to approximate important aspects of the brittle fracture problem. In addition to the ML algorithms, each method incorporates different physics-based assumptions in order to reduce the computational complexity while maintaining the physics as much as possible. This work specifically focuses on using the ML approaches to model a 2D concrete sample under low strain rate pure tensile loading conditions with 20 preexisting cracks present. A high-fidelity finite element-discrete element model is used to both produce a training dataset of 150 simulations and an additional 35 simulations for validation. Results from the ML approaches are directly compared against the results from the high-fidelity model. Strengths and weaknesses of each approach are discussed and the most important conclusion is that a combination of physics-informed and data-driven features are necessary for emulating the physics of crack propagation, interaction and coalescence. All of the models presented here have runtimes that are orders of magnitude faster than the original high-fidelity model and pave the path for developing accurate reduced order models that could be used to inform larger length-scale models with important sub-scale physics that often cannot be accounted for due to computational cost.
Unsupervised Machine Learning Based on Non-Negative Tensor Factorization for Analyzing Reactive-Mixing
May 16, 2018
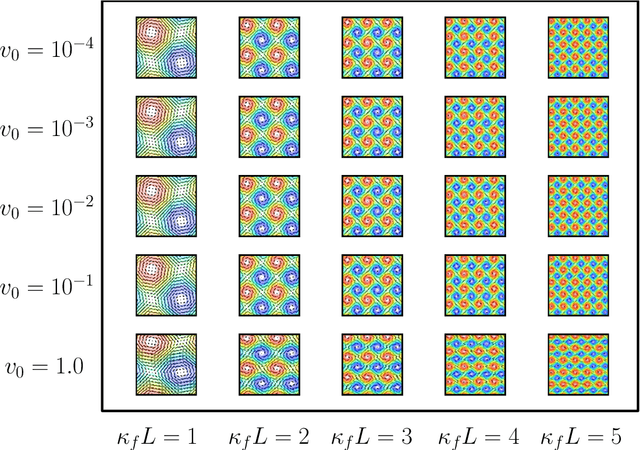
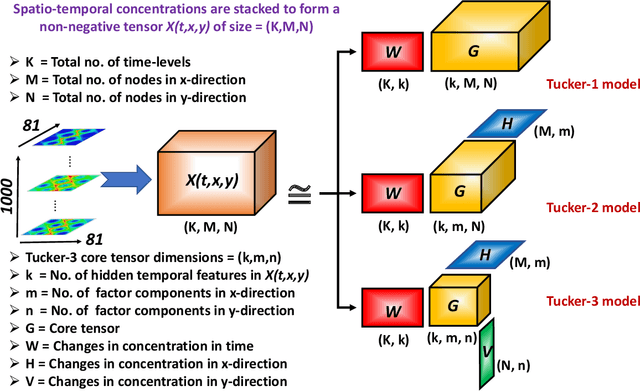

Analysis of reactive-diffusion simulations requires a large number of independent model runs. For each high-fidelity simulation, inputs are varied and the predicted mixing behavior is represented by changes in species concentration. It is then required to discern how the model inputs impact the mixing process. This task is challenging and typically involves interpretation of large model outputs. However, the task can be automated and substantially simplified by applying Machine Learning (ML) methods. In this paper, we present an application of an unsupervised ML method (called NTFk) using Non-negative Tensor Factorization (NTF) coupled with a custom clustering procedure based on k-means to reveal hidden features in product concentration. An attractive aspect of the proposed ML method is that it ensures the extracted features are non-negative, which are important to obtain a meaningful deconstruction of the mixing processes. The ML method is applied to a large set of high-resolution FEM simulations representing reaction-diffusion processes in perturbed vortex-based velocity fields. The applied FEM ensures that species concentration are always non-negative. The simulated reaction is a fast irreversible bimolecular reaction. The reactive-diffusion model input parameters that control mixing include properties of velocity field, anisotropic dispersion, and molecular diffusion. We demonstrate the applicability of the ML method to produce a meaningful deconstruction of model outputs to discriminate between different physical processes impacting the reactants, their mixing, and the spatial distribution of the product. The presented ML analysis allowed us to identify additive features that characterize mixing behavior.
Sequential geophysical and flow inversion to characterize fracture networks in subsurface systems
Jul 13, 2017
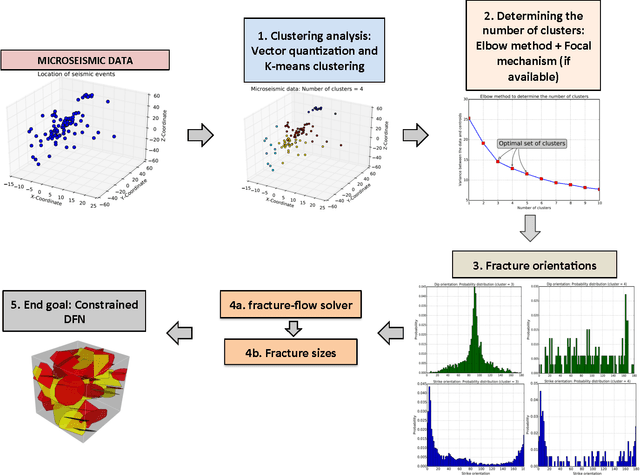


Subsurface applications including geothermal, geological carbon sequestration, oil and gas, etc., typically involve maximizing either the extraction of energy or the storage of fluids. Characterizing the subsurface is extremely complex due to heterogeneity and anisotropy. Due to this complexity, there are uncertainties in the subsurface parameters, which need to be estimated from multiple diverse as well as fragmented data streams. In this paper, we present a non-intrusive sequential inversion framework, for integrating data from geophysical and flow sources to constraint subsurface Discrete Fracture Networks (DFN). In this approach, we first estimate bounds on the statistics for the DFN fracture orientations using microseismic data. These bounds are estimated through a combination of a focal mechanism (physics-based approach) and clustering analysis (statistical approach) of seismic data. Then, the fracture lengths are constrained based on the flow data. The efficacy of this multi-physics based sequential inversion is demonstrated through a representative synthetic example.
Regression-based reduced-order models to predict transient thermal output for enhanced geothermal systems
Jul 12, 2017



The goal of this paper is to assess the utility of Reduced-Order Models (ROMs) developed from 3D physics-based models for predicting transient thermal power output for an enhanced geothermal reservoir while explicitly accounting for uncertainties in the subsurface system and site-specific details. Numerical simulations are performed based on Latin Hypercube Sampling (LHS) of model inputs drawn from uniform probability distributions. Key sensitive parameters are identified from these simulations, which are fracture zone permeability, well/skin factor, bottom hole pressure, and injection flow rate. The inputs for ROMs are based on these key sensitive parameters. The ROMs are then used to evaluate the influence of subsurface attributes on thermal power production curves. The resulting ROMs are compared with field-data and the detailed physics-based numerical simulations. We propose three different ROMs with different levels of model parsimony, each describing key and essential features of the power production curves. ROM-1 is able to accurately reproduce the power output of numerical simulations for low values of permeabilities and certain features of the field-scale data, and is relatively parsimonious. ROM-2 is a more complex model than ROM-1 but it accurately describes the field-data. At higher permeabilities, ROM-2 reproduces numerical results better than ROM-1, however, there is a considerable deviation at low fracture zone permeabilities. ROM-3 is developed by taking the best aspects of ROM-1 and ROM-2 and provides a middle ground for model parsimony. It is able to describe various features of numerical simulations and field-data. From the proposed workflow, we demonstrate that the proposed simple ROMs are able to capture various complex features of the power production curves of Fenton Hill HDR system. For typical EGS applications, ROM-2 and ROM-3 outperform ROM-1.
* 25 pages, 8 figures