 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReduced-Order Modeling through Machine Learning Approaches for Brittle Fracture Applications
Jun 05, 2018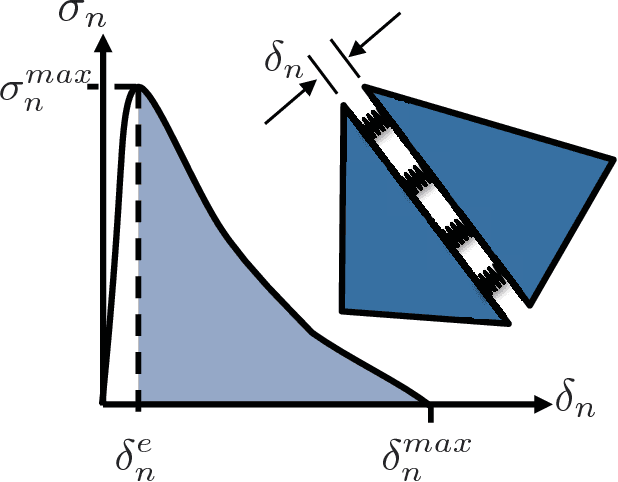

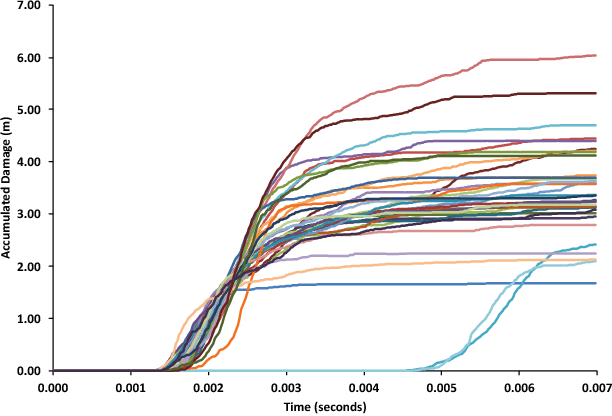
In this paper, five different approaches for reduced-order modeling of brittle fracture in geomaterials, specifically concrete, are presented and compared. Four of the five methods rely on machine learning (ML) algorithms to approximate important aspects of the brittle fracture problem. In addition to the ML algorithms, each method incorporates different physics-based assumptions in order to reduce the computational complexity while maintaining the physics as much as possible. This work specifically focuses on using the ML approaches to model a 2D concrete sample under low strain rate pure tensile loading conditions with 20 preexisting cracks present. A high-fidelity finite element-discrete element model is used to both produce a training dataset of 150 simulations and an additional 35 simulations for validation. Results from the ML approaches are directly compared against the results from the high-fidelity model. Strengths and weaknesses of each approach are discussed and the most important conclusion is that a combination of physics-informed and data-driven features are necessary for emulating the physics of crack propagation, interaction and coalescence. All of the models presented here have runtimes that are orders of magnitude faster than the original high-fidelity model and pave the path for developing accurate reduced order models that could be used to inform larger length-scale models with important sub-scale physics that often cannot be accounted for due to computational cost.
Unsupervised Machine Learning Based on Non-Negative Tensor Factorization for Analyzing Reactive-Mixing
May 16, 2018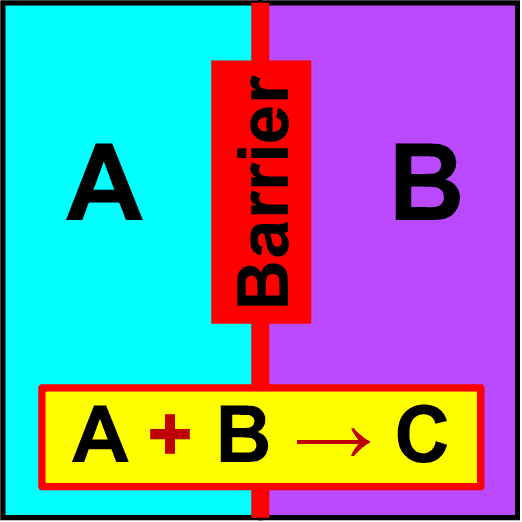
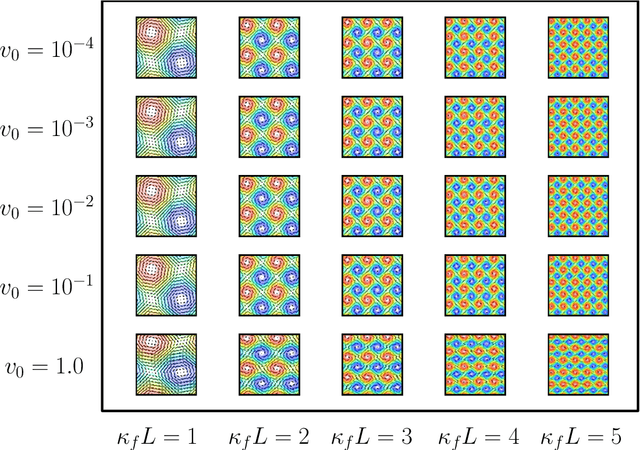
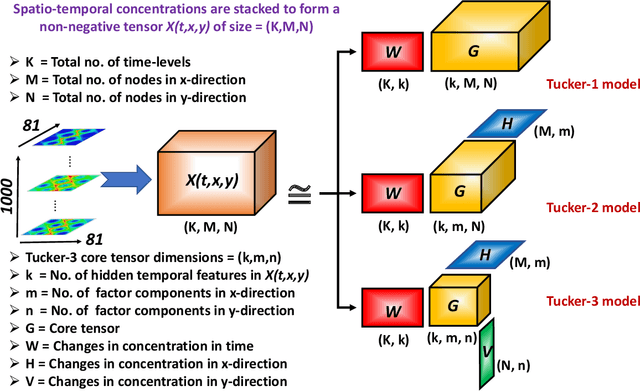

Analysis of reactive-diffusion simulations requires a large number of independent model runs. For each high-fidelity simulation, inputs are varied and the predicted mixing behavior is represented by changes in species concentration. It is then required to discern how the model inputs impact the mixing process. This task is challenging and typically involves interpretation of large model outputs. However, the task can be automated and substantially simplified by applying Machine Learning (ML) methods. In this paper, we present an application of an unsupervised ML method (called NTFk) using Non-negative Tensor Factorization (NTF) coupled with a custom clustering procedure based on k-means to reveal hidden features in product concentration. An attractive aspect of the proposed ML method is that it ensures the extracted features are non-negative, which are important to obtain a meaningful deconstruction of the mixing processes. The ML method is applied to a large set of high-resolution FEM simulations representing reaction-diffusion processes in perturbed vortex-based velocity fields. The applied FEM ensures that species concentration are always non-negative. The simulated reaction is a fast irreversible bimolecular reaction. The reactive-diffusion model input parameters that control mixing include properties of velocity field, anisotropic dispersion, and molecular diffusion. We demonstrate the applicability of the ML method to produce a meaningful deconstruction of model outputs to discriminate between different physical processes impacting the reactants, their mixing, and the spatial distribution of the product. The presented ML analysis allowed us to identify additive features that characterize mixing behavior.