 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Eigenspace Network and Its Application to Parametric Non-selfadjoint Eigenvalue Problems
Dec 23, 2025We consider operator learning for efficiently solving parametric non-selfadjoint eigenvalue problems. To overcome the spectral instability and mode switching inherent in non-selfadjoint operators, we introduce a hybrid framework that learns the stable invariant eigensubspace mapping rather than individual eigenfunctions. We proposed a Deep Eigenspace Network (DEN) architecture integrating Fourier Neural Operators, geometry-adaptive POD bases, and explicit banded cross-mode mixing mechanisms to capture complex spectral dependencies on unstructured meshes. We apply DEN to the parametric non-selfadjoint Steklov eigenvalue problem and provide theoretical proofs for the Lipschitz continuity of the eigensubspace with respect to the parameters. In addition, we derive error bounds for the reconstruction of the eigenspace. Numerical experiments validate DEN's high accuracy and zero-shot generalization capabilities across different discretizations.
UMFA: A photorealistic style transfer method based on U-Net and multi-layer feature aggregation
Aug 13, 2021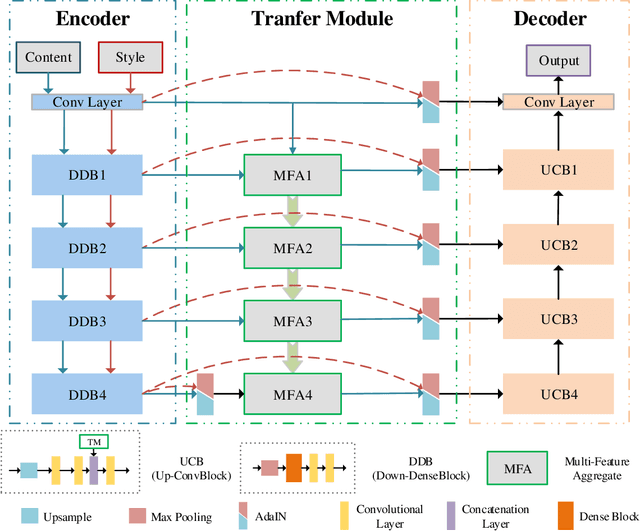

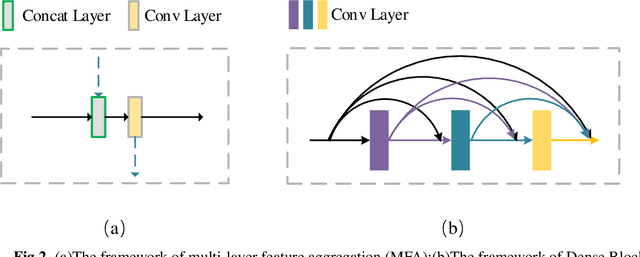

In this paper, we propose a photorealistic style transfer network to emphasize the natural effect of photorealistic image stylization. In general, distortion of the image content and lacking of details are two typical issues in the style transfer field. To this end, we design a novel framework employing the U-Net structure to maintain the rich spatial clues, with a multi-layer feature aggregation (MFA) method to simultaneously provide the details obtained by the shallow layers in the stylization processing. In particular, an encoder based on the dense block and a decoder form a symmetrical structure of U-Net are jointly staked to realize an effective feature extraction and image reconstruction. Besides, a transfer module based on MFA and "adaptive instance normalization" (AdaIN) is inserted in the skip connection positions to achieve the stylization. Accordingly, the stylized image possesses the texture of a real photo and preserves rich content details without introducing any mask or post-processing steps. The experimental results on public datasets demonstrate that our method achieves a more faithful structural similarity with a lower style loss, reflecting the effectiveness and merit of our approach.
Joint Spatio-Temporal Discretisation of Nonlinear Active Cochlear Models
Aug 12, 2021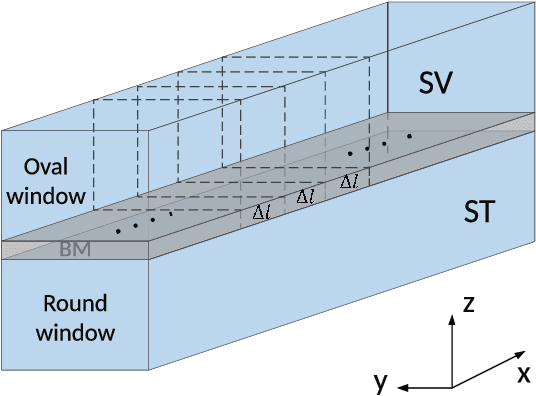
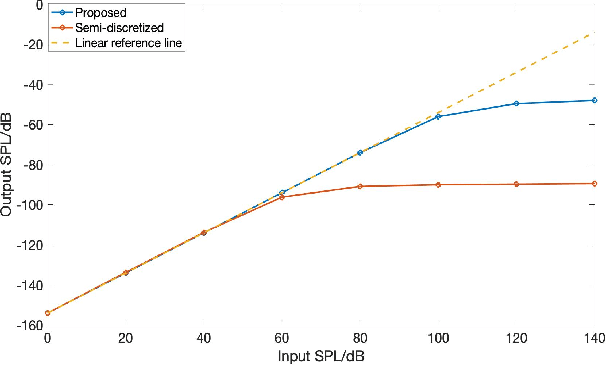
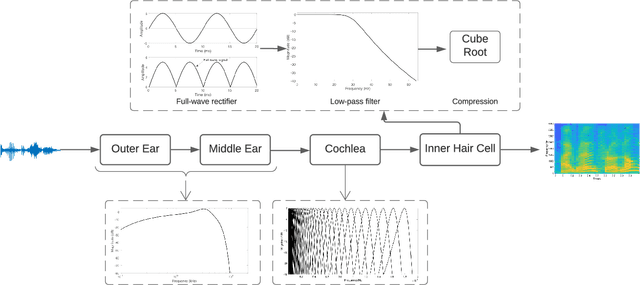
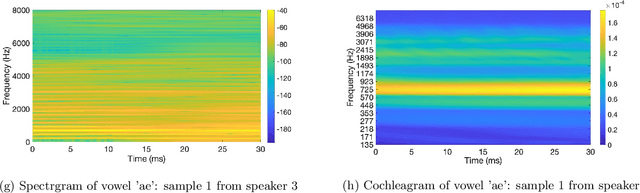
Biologically inspired auditory models play an important role in developing effective audio representations that can be tightly integrated into speech and audio processing systems. Current computational models of the cochlea are typically expressed in terms of systems of differential equations and do not directly lend themselves for use in computational speech processing systems. Specifically, these models are spatially discrete and temporally continuous. This paper presents a jointly discretised (spatially and temporally discrete) model of the cochlea which allows for processing at fixed time intervals suited to discrete time speech and audio processing systems. The proposed model takes into account the active feedback mechanism in the cochlea, a core characteristic lacking in traditional speech processing front-ends, which endows it with significant dynamic range compression capability. This model is derived by jointly discretising an established semi-discretised (spatially discrete and temporally continuous) cochlear model in a state space form. We then demonstrate that the proposed jointly discretised implementation matches the semi-discrete model in terms of its characteristics and finally present stability analyses of the proposed model.
S$^{2}$OMGAN: Shortcut from Remote Sensing Images to Online Maps
Jan 21, 2020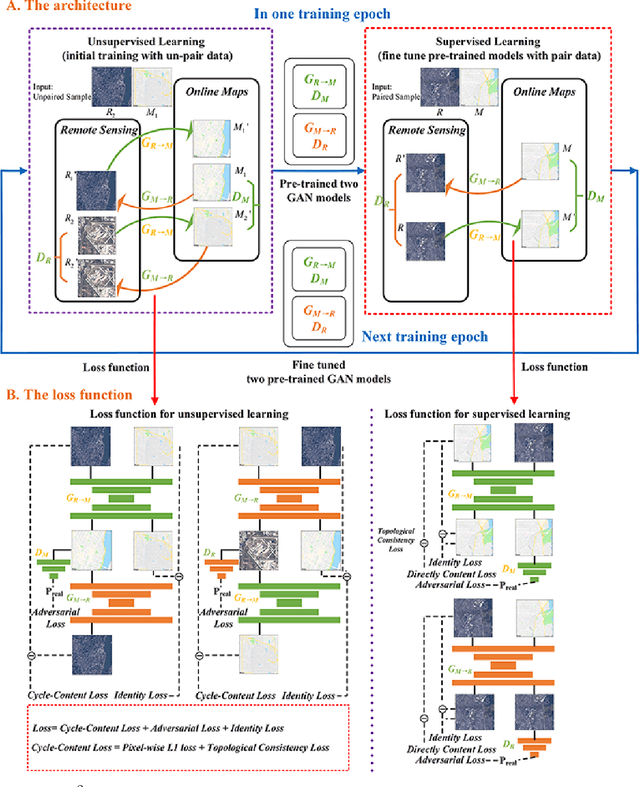
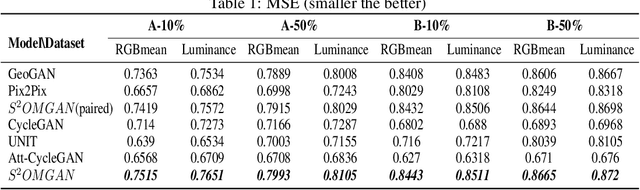
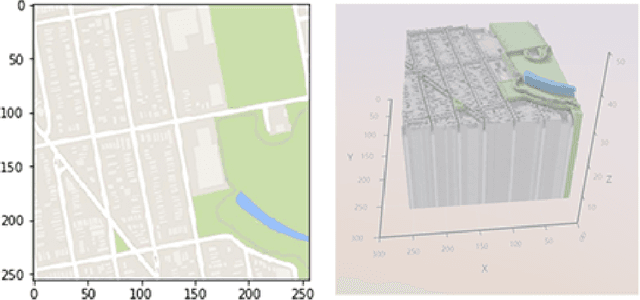
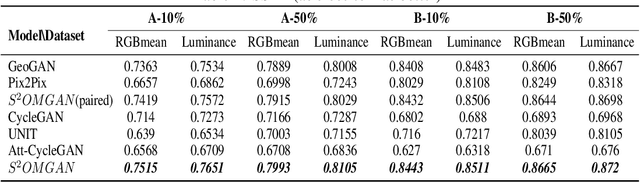
Traditional online maps, widely used on Internet such as Google map and Baidu map, are rendered from vector data. Timely updating online maps from vector data, of which the generating is time-consuming, is a difficult mission. It is a shortcut to generate online maps in time from remote sensing images, which can be acquired timely without vector data. However, this mission used to be challenging or even impossible. Inspired by image-to-image translation (img2img) techniques based on generative adversarial network (GAN), we propose a semi-supervised structure-augmented online map GAN (S$^{2}$OMGAN) model to generate online maps directly from remote sensing images. In this model, we designed a semi-supervised learning strategy to pre-train S$^{2}$OMGAN on rich unpaired samples and finetune it on limited paired samples in reality. We also designed image gradient L1 loss and image gradient structure loss to generate an online map with global topological relationship and detailed edge curves of objects, which are important in cartography. Moreover, we propose edge structural similarity index (ESSI) as a metric to evaluate the quality of topological consistency between generated online maps and ground truths. Experimental results present that S$^{2}$OMGAN outperforms state-of-the-art (SOTA) works according to mean squared error, structural similarity index and ESSI. Also, S$^{2}$OMGAN wins more approval than SOTA in the human perceptual test on visual realism of cartography. Our work shows that S$^{2}$OMGAN is potentially a new paradigm to produce online maps. Our implementation of the S$^{2}$OMGAN is available at \url{https://github.com/imcsq/S2OMGAN}.
Effectiveness of Scaled Exponentially-Regularized Linear Units (SERLUs)
Jul 27, 2018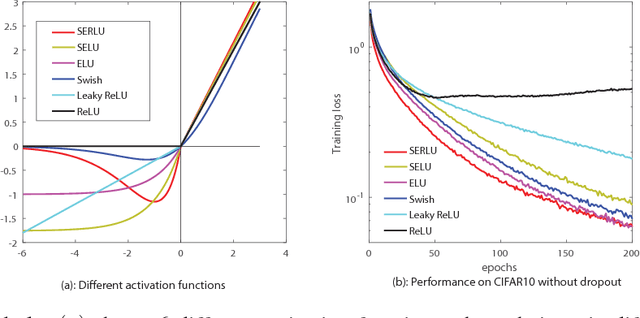
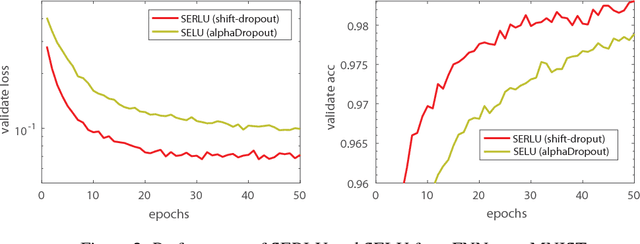

Recently, self-normalizing neural networks (SNNs) have been proposed with the intention to avoid batch or weight normalization. The key step in SNNs is to properly scale the exponential linear unit (referred to as SELU) to inherently incorporate normalization based on central limit theory. SELU is a monotonically increasing function, where it has an approximately constant negative output for large negative input. In this work, we propose a new activation function to break the monotonicity property of SELU while still preserving the self-normalizing property. Differently from SELU, the new function introduces a bump-shaped function in the region of negative input by regularizing a linear function with a scaled exponential function, which is referred to as a scaled exponentially-regularized linear unit (SERLU). The bump-shaped function has approximately zero response to large negative input while being able to push the output of SERLU towards zero mean statistically. To effectively combat over-fitting, we develop a so-called shift-dropout for SERLU, which includes standard dropout as a special case. Experimental results on MNIST, CIFAR10 and CIFAR100 show that SERLU-based neural networks provide consistently promising results in comparison to other 5 activation functions including ELU, SELU, Swish, Leakly ReLU and ReLU.