 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-time 3D Semantic Scene Perception for Egocentric Robots with Binocular Vision
Feb 19, 2024Perceiving a three-dimensional (3D) scene with multiple objects while moving indoors is essential for vision-based mobile cobots, especially for enhancing their manipulation tasks. In this work, we present an end-to-end pipeline with instance segmentation, feature matching, and point-set registration for egocentric robots with binocular vision, and demonstrate the robot's grasping capability through the proposed pipeline. First, we design an RGB image-based segmentation approach for single-view 3D semantic scene segmentation, leveraging common object classes in 2D datasets to encapsulate 3D points into point clouds of object instances through corresponding depth maps. Next, 3D correspondences of two consecutive segmented point clouds are extracted based on matched keypoints between objects of interest in RGB images from the prior step. In addition, to be aware of spatial changes in 3D feature distribution, we also weigh each 3D point pair based on the estimated distribution using kernel density estimation (KDE), which subsequently gives robustness with less central correspondences while solving for rigid transformations between point clouds. Finally, we test our proposed pipeline on the 7-DOF dual-arm Baxter robot with a mounted Intel RealSense D435i RGB-D camera. The result shows that our robot can segment objects of interest, register multiple views while moving, and grasp the target object. The source code is available at https://github.com/mkhangg/semantic_scene_perception.
Joint Spatio-Temporal Discretisation of Nonlinear Active Cochlear Models
Aug 12, 2021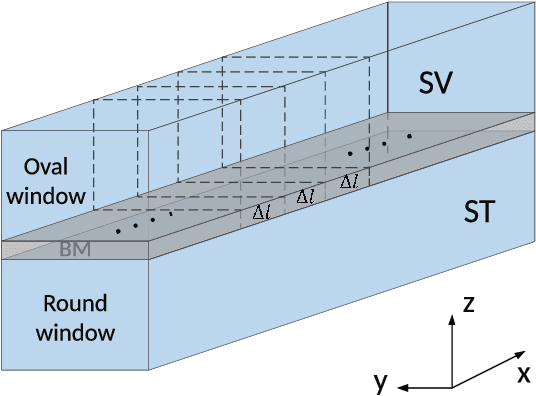
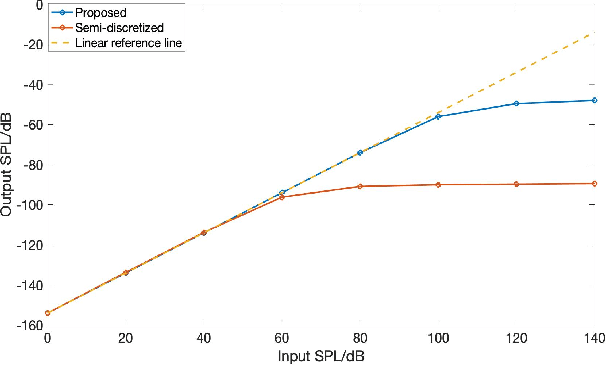
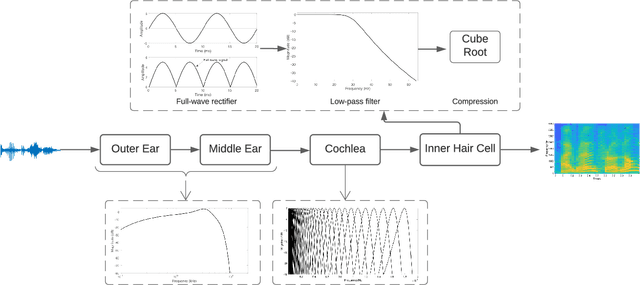
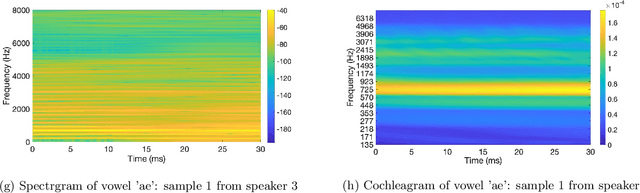
Biologically inspired auditory models play an important role in developing effective audio representations that can be tightly integrated into speech and audio processing systems. Current computational models of the cochlea are typically expressed in terms of systems of differential equations and do not directly lend themselves for use in computational speech processing systems. Specifically, these models are spatially discrete and temporally continuous. This paper presents a jointly discretised (spatially and temporally discrete) model of the cochlea which allows for processing at fixed time intervals suited to discrete time speech and audio processing systems. The proposed model takes into account the active feedback mechanism in the cochlea, a core characteristic lacking in traditional speech processing front-ends, which endows it with significant dynamic range compression capability. This model is derived by jointly discretising an established semi-discretised (spatially discrete and temporally continuous) cochlear model in a state space form. We then demonstrate that the proposed jointly discretised implementation matches the semi-discrete model in terms of its characteristics and finally present stability analyses of the proposed model.