 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTightly Coupled Learning Strategy for Weakly Supervised Hierarchical Place Recognition
Feb 14, 2022



Visual place recognition (VPR) is a key issue for robotics and autonomous systems. For the trade-off between time and performance, most of methods use the coarse-to-fine hierarchical architecture, which consists of retrieving top-N candidates using global features, and re-ranking top-N with local features. However, since the two types of features are usually processed independently, re-ranking may harm global retrieval, termed re-ranking confusion. Moreover, re-ranking is limited by global retrieval. In this paper, we propose a tightly coupled learning (TCL) strategy to train triplet models. Different from original triplet learning (OTL) strategy, it combines global and local descriptors for joint optimization. In addition, a bidirectional search dynamic time warping (BS-DTW) algorithm is also proposed to mine locally spatial information tailored to VPR in re-ranking. The experimental results on public benchmarks show that the models using TCL outperform the models using OTL, and TCL can be used as a general strategy to improve performance for weakly supervised ranking tasks. Further, our lightweight unified model is better than several state-of-the-art methods and has over an order of magnitude of computational efficiency to meet the real-time requirements of robots.
Topic Scene Graph Generation by Attention Distillation from Caption
Oct 12, 2021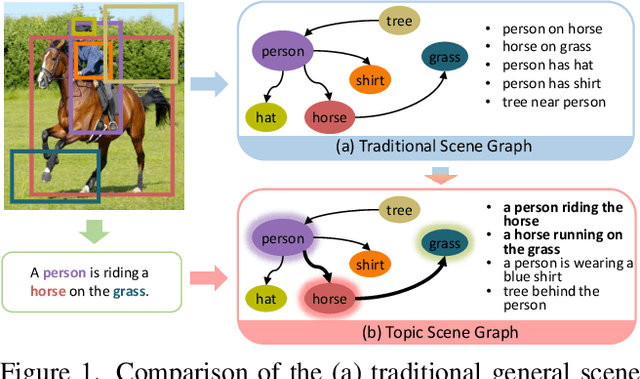
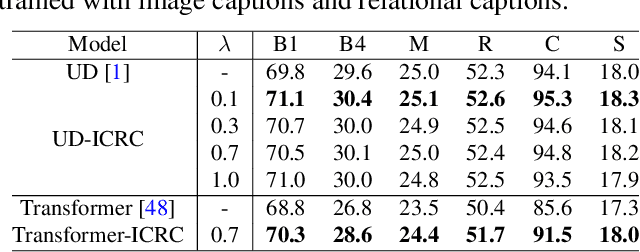
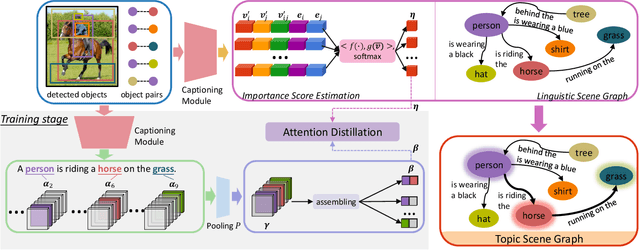
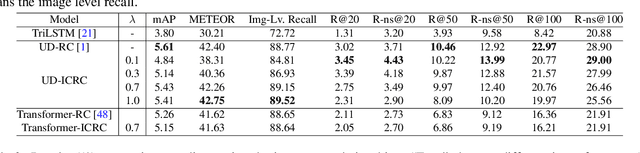
If an image tells a story, the image caption is the briefest narrator. Generally, a scene graph prefers to be an omniscient generalist, while the image caption is more willing to be a specialist, which outlines the gist. Lots of previous studies have found that a scene graph is not as practical as expected unless it can reduce the trivial contents and noises. In this respect, the image caption is a good tutor. To this end, we let the scene graph borrow the ability from the image caption so that it can be a specialist on the basis of remaining all-around, resulting in the so-called Topic Scene Graph. What an image caption pays attention to is distilled and passed to the scene graph for estimating the importance of partial objects, relationships, and events. Specifically, during the caption generation, the attention about individual objects in each time step is collected, pooled, and assembled to obtain the attention about relationships, which serves as weak supervision for regularizing the estimated importance scores of relationships. In addition, as this attention distillation process provides an opportunity for combining the generation of image caption and scene graph together, we further transform the scene graph into linguistic form with rich and free-form expressions by sharing a single generation model with image caption. Experiments show that attention distillation brings significant improvements in mining important relationships without strong supervision, and the topic scene graph shows great potential in subsequent applications.
Learning Monocular 3D Vehicle Detection without 3D Bounding Box Labels
Oct 07, 2020


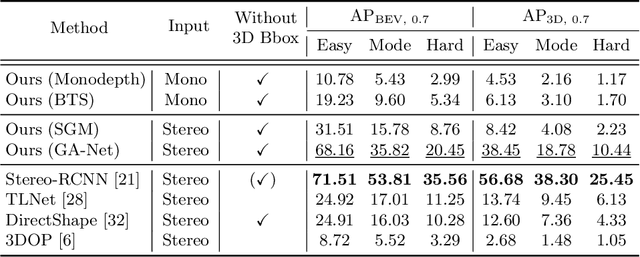
The training of deep-learning-based 3D object detectors requires large datasets with 3D bounding box labels for supervision that have to be generated by hand-labeling. We propose a network architecture and training procedure for learning monocular 3D object detection without 3D bounding box labels. By representing the objects as triangular meshes and employing differentiable shape rendering, we define loss functions based on depth maps, segmentation masks, and ego- and object-motion, which are generated by pre-trained, off-the-shelf networks. We evaluate the proposed algorithm on the real-world KITTI dataset and achieve promising performance in comparison to state-of-the-art methods requiring 3D bounding box labels for training and superior performance to conventional baseline methods.
Delay Learning Architectures for Memory and Classification
Feb 27, 2014
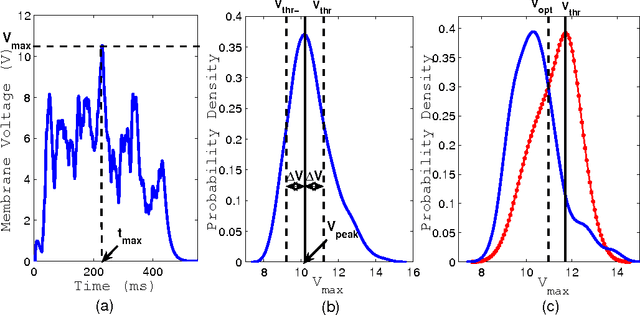
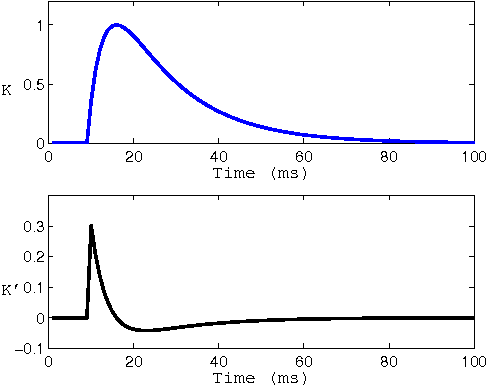

We present a neuromorphic spiking neural network, the DELTRON, that can remember and store patterns by changing the delays of every connection as opposed to modifying the weights. The advantage of this architecture over traditional weight based ones is simpler hardware implementation without multipliers or digital-analog converters (DACs) as well as being suited to time-based computing. The name is derived due to similarity in the learning rule with an earlier architecture called Tempotron. The DELTRON can remember more patterns than other delay-based networks by modifying a few delays to remember the most 'salient' or synchronous part of every spike pattern. We present simulations of memory capacity and classification ability of the DELTRON for different random spatio-temporal spike patterns. The memory capacity for noisy spike patterns and missing spikes are also shown. Finally, we present SPICE simulation results of the core circuits involved in a reconfigurable mixed signal implementation of this architecture.
Synthesis of neural networks for spatio-temporal spike pattern recognition and processing
Apr 26, 2013
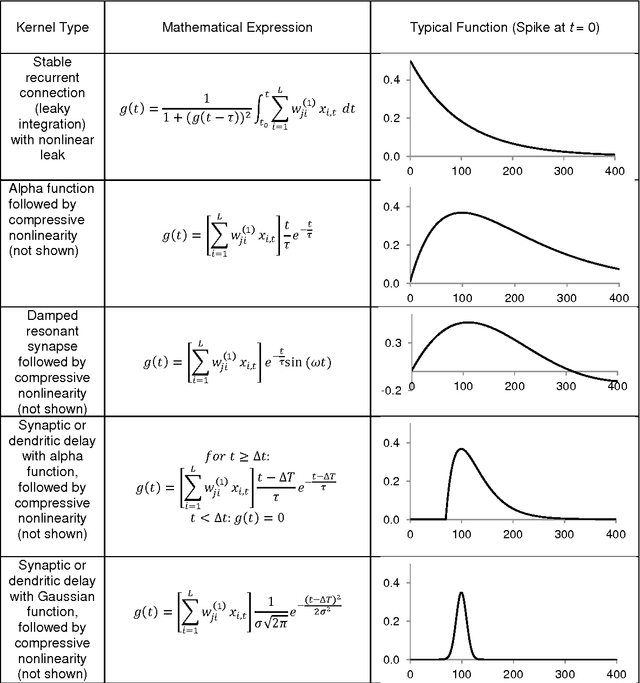
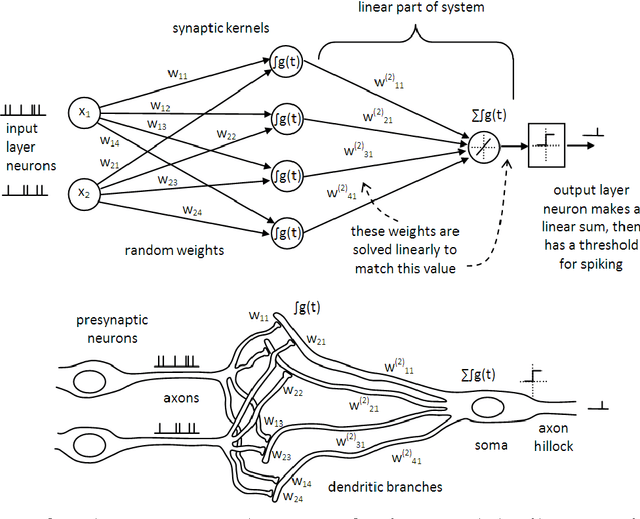

The advent of large scale neural computational platforms has highlighted the lack of algorithms for synthesis of neural structures to perform predefined cognitive tasks. The Neural Engineering Framework offers one such synthesis, but it is most effective for a spike rate representation of neural information, and it requires a large number of neurons to implement simple functions. We describe a neural network synthesis method that generates synaptic connectivity for neurons which process time-encoded neural signals, and which makes very sparse use of neurons. The method allows the user to specify, arbitrarily, neuronal characteristics such as axonal and dendritic delays, and synaptic transfer functions, and then solves for the optimal input-output relationship using computed dendritic weights. The method may be used for batch or online learning and has an extremely fast optimization process. We demonstrate its use in generating a network to recognize speech which is sparsely encoded as spike times.