 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Monocular 3D Vehicle Detection without 3D Bounding Box Labels
Oct 07, 2020


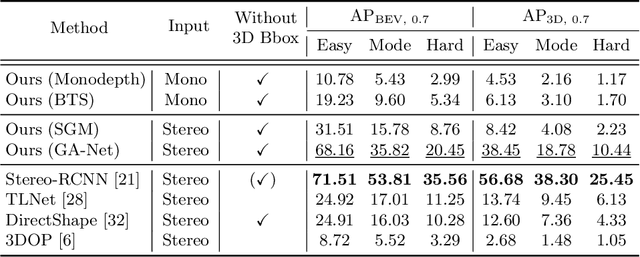
The training of deep-learning-based 3D object detectors requires large datasets with 3D bounding box labels for supervision that have to be generated by hand-labeling. We propose a network architecture and training procedure for learning monocular 3D object detection without 3D bounding box labels. By representing the objects as triangular meshes and employing differentiable shape rendering, we define loss functions based on depth maps, segmentation masks, and ego- and object-motion, which are generated by pre-trained, off-the-shelf networks. We evaluate the proposed algorithm on the real-world KITTI dataset and achieve promising performance in comparison to state-of-the-art methods requiring 3D bounding box labels for training and superior performance to conventional baseline methods.
Compression for Smooth Shape Analysis
Nov 29, 2017



Most 3D shape analysis methods use triangular meshes to discretize both the shape and functions on it as piecewise linear functions. With this representation, shape analysis requires fine meshes to represent smooth shapes and geometric operators like normals, curvatures, or Laplace-Beltrami eigenfunctions at large computational and memory costs. We avoid this bottleneck with a compression technique that represents a smooth shape as subdivision surfaces and exploits the subdivision scheme to parametrize smooth functions on that shape with a few control parameters. This compression does not affect the accuracy of the Laplace-Beltrami operator and its eigenfunctions and allow us to compute shape descriptors and shape matchings at an accuracy comparable to triangular meshes but a fraction of the computational cost. Our framework can also compress surfaces represented by point clouds to do shape analysis of 3D scanning data.