 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Imitation: A Life-long Policy Learning Framework for Path Tracking Control of Autonomous Driving
Apr 26, 2024Model-free learning-based control methods have recently shown significant advantages over traditional control methods in avoiding complex vehicle characteristic estimation and parameter tuning. As a primary policy learning method, imitation learning (IL) is capable of learning control policies directly from expert demonstrations. However, the performance of IL policies is highly dependent on the data sufficiency and quality of the demonstrations. To alleviate the above problems of IL-based policies, a lifelong policy learning (LLPL) framework is proposed in this paper, which extends the IL scheme with lifelong learning (LLL). First, a novel IL-based model-free control policy learning method for path tracking is introduced. Even with imperfect demonstration, the optimal control policy can be learned directly from historical driving data. Second, by using the LLL method, the pre-trained IL policy can be safely updated and fine-tuned with incremental execution knowledge. Third, a knowledge evaluation method for policy learning is introduced to avoid learning redundant or inferior knowledge, thus ensuring the performance improvement of online policy learning. Experiments are conducted using a high-fidelity vehicle dynamic model in various scenarios to evaluate the performance of the proposed method. The results show that the proposed LLPL framework can continuously improve the policy performance with collected incremental driving data, and achieves the best accuracy and control smoothness compared to other baseline methods after evolving on a 7 km curved road. Through learning and evaluation with noisy real-life data collected in an off-road environment, the proposed LLPL framework also demonstrates its applicability in learning and evolving in real-life scenarios.
Generative Adversarial Networks for Scintillation Signal Simulation in EXO-200
Mar 11, 2023Generative Adversarial Networks trained on samples of simulated or actual events have been proposed as a way of generating large simulated datasets at a reduced computational cost. In this work, a novel approach to perform the simulation of photodetector signals from the time projection chamber of the EXO-200 experiment is demonstrated. The method is based on a Wasserstein Generative Adversarial Network - a deep learning technique allowing for implicit non-parametric estimation of the population distribution for a given set of objects. Our network is trained on real calibration data using raw scintillation waveforms as input. We find that it is able to produce high-quality simulated waveforms an order of magnitude faster than the traditional simulation approach and, importantly, generalize from the training sample and discern salient high-level features of the data. In particular, the network correctly deduces position dependency of scintillation light response in the detector and correctly recognizes dead photodetector channels. The network output is then integrated into the EXO-200 analysis framework to show that the standard EXO-200 reconstruction routine processes the simulated waveforms to produce energy distributions comparable to that of real waveforms. Finally, the remaining discrepancies and potential ways to improve the approach further are highlighted.
Online progressive instance-balanced sampling for weakly supervised object detection
Jun 21, 2022
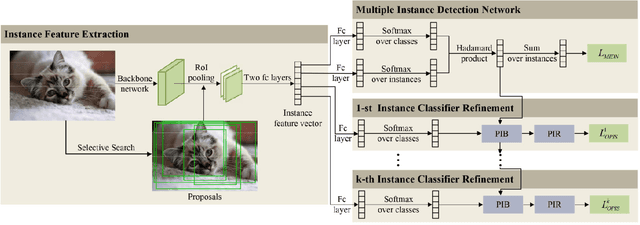
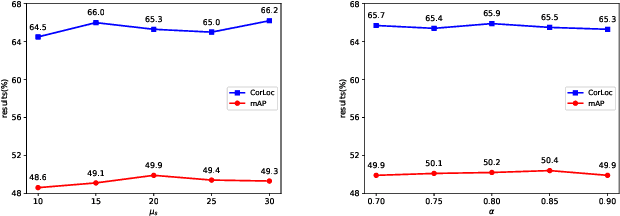
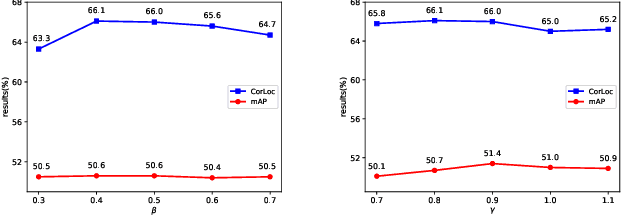
Based on multiple instance detection networks (MIDN), plenty of works have contributed tremendous efforts to weakly supervised object detection (WSOD). However, most methods neglect the fact that the overwhelming negative instances exist in each image during the training phase, which would mislead the training and make the network fall into local minima. To tackle this problem, an online progressive instance-balanced sampling (OPIS) algorithm based on hard sampling and soft sampling is proposed in this paper. The algorithm includes two modules: a progressive instance balance (PIB) module and a progressive instance reweighting (PIR) module. The PIB module combining random sampling and IoU-balanced sampling progressively mines hard negative instances while balancing positive instances and negative instances. The PIR module further utilizes classifier scores and IoUs of adjacent refinements to reweight the weights of positive instances for making the network focus on positive instances. Extensive experimental results on the PASCAL VOC 2007 and 2012 datasets demonstrate the proposed method can significantly improve the baseline, which is also comparable to many existing state-of-the-art results. In addition, compared to the baseline, the proposed method requires no extra network parameters and the supplementary training overheads are small, which could be easily integrated into other methods based on the instance classifier refinement paradigm.