 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Functional Data Analysis with Sequential Neural Networks: Advantages and Comparative Study
Nov 03, 2023Functional Data Analysis (FDA) is a statistical domain developed to handle functional data characterized by high dimensionality and complex data structures. Sequential Neural Networks (SNNs) are specialized neural networks capable of processing sequence data, a fundamental aspect of functional data. Despite their great flexibility in modeling functional data, SNNs have been inadequately employed in the FDA community. One notable advantage of SNNs is the ease of implementation, making them accessible to a broad audience beyond academia. Conversely, FDA-based methodologies present challenges, particularly for practitioners outside the field, due to their intricate complexity. In light of this, we propose utilizing SNNs in FDA applications and demonstrate their effectiveness through comparative analyses against popular FDA regression models based on numerical experiments and real-world data analysis. SNN architectures allow us to surpass the limitations of traditional FDA methods, offering scalability, flexibility, and improved analytical performance. Our findings highlight the potential of SNN-based methodologies as powerful tools for data applications involving functional data.
PeTailor: Improving Large Language Model by Tailored Chunk Scorer in Biomedical Triple Extraction
Oct 27, 2023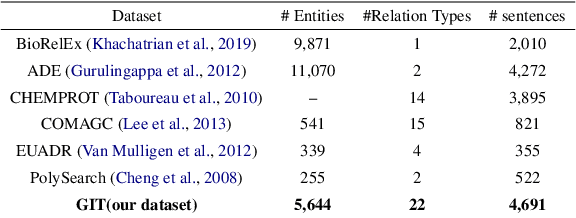



The automatic extraction of biomedical entities and their interaction from unstructured data remains a challenging task due to the limited availability of expert-labeled standard datasets. In this paper, we introduce PETAI-LOR, a retrieval-based language framework that is augmented by tailored chunk scorer. Unlike previous retrieval-augmented language models (LM) that retrieve relevant documents by calculating the similarity between the input sentence and the candidate document set, PETAILOR segments the sentence into chunks and retrieves the relevant chunk from our pre-computed chunk-based relational key-value memory. Moreover, in order to comprehend the specific requirements of the LM, PETAI-LOR adapt the tailored chunk scorer to the LM. We also introduce GM-CIHT, an expert annotated biomedical triple extraction dataset with more relation types. This dataset is centered on the non-drug treatment and general biomedical domain. Additionally, we investigate the efficacy of triple extraction models trained on general domains when applied to the biomedical domain. Our experiments reveal that PETAI-LOR achieves state-of-the-art performance on GM-CIHT
Online progressive instance-balanced sampling for weakly supervised object detection
Jun 21, 2022
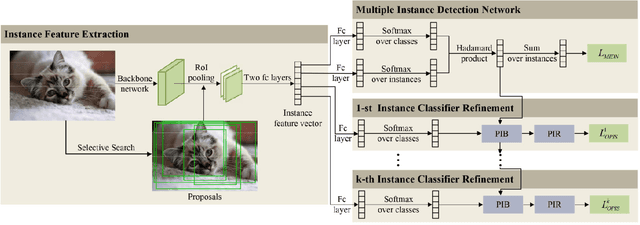
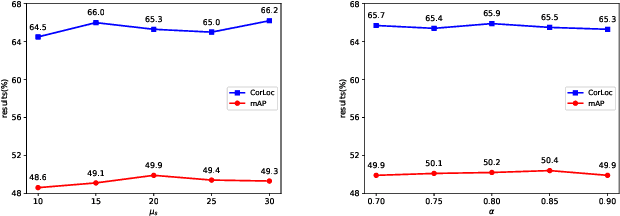
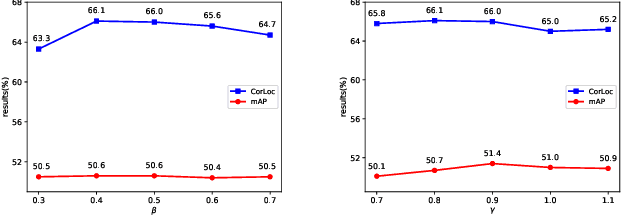
Based on multiple instance detection networks (MIDN), plenty of works have contributed tremendous efforts to weakly supervised object detection (WSOD). However, most methods neglect the fact that the overwhelming negative instances exist in each image during the training phase, which would mislead the training and make the network fall into local minima. To tackle this problem, an online progressive instance-balanced sampling (OPIS) algorithm based on hard sampling and soft sampling is proposed in this paper. The algorithm includes two modules: a progressive instance balance (PIB) module and a progressive instance reweighting (PIR) module. The PIB module combining random sampling and IoU-balanced sampling progressively mines hard negative instances while balancing positive instances and negative instances. The PIR module further utilizes classifier scores and IoUs of adjacent refinements to reweight the weights of positive instances for making the network focus on positive instances. Extensive experimental results on the PASCAL VOC 2007 and 2012 datasets demonstrate the proposed method can significantly improve the baseline, which is also comparable to many existing state-of-the-art results. In addition, compared to the baseline, the proposed method requires no extra network parameters and the supplementary training overheads are small, which could be easily integrated into other methods based on the instance classifier refinement paradigm.
Smart Anomaly Detection in Sensor Systems: A Multi-Perspective Review
Oct 31, 2020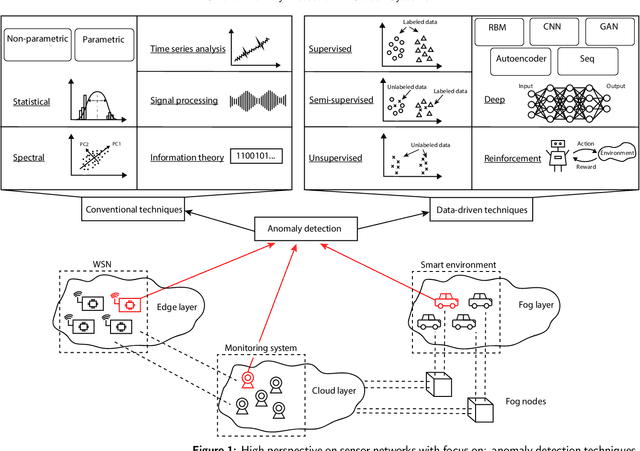
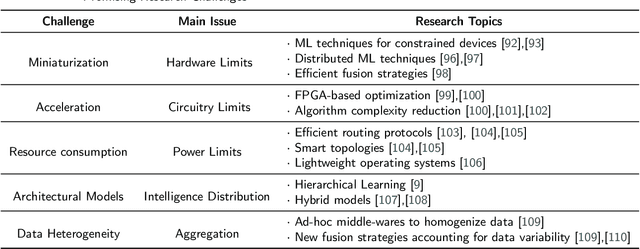
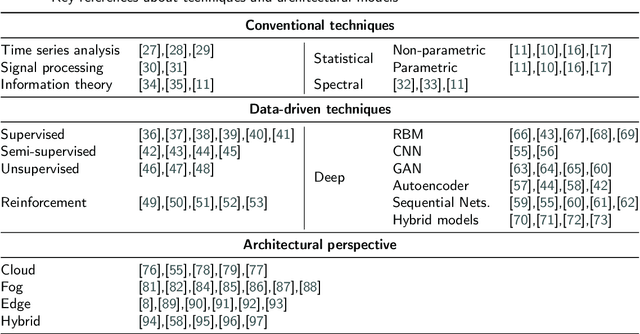
Anomaly detection is concerned with identifying data patterns that deviate remarkably from the expected behaviour. This is an important research problem, due to its broad set of application domains, from data analysis to e-health, cybersecurity, predictive maintenance, fault prevention, and industrial automation. Herein, we review state-of-the-art methods that may be employed to detect anomalies in the specific area of sensor systems, which poses hard challenges in terms of information fusion, data volumes, data speed, and network/energy efficiency, to mention but the most pressing ones. In this context, anomaly detection is a particularly hard problem, given the need to find computing-energy accuracy trade-offs in a constrained environment. We taxonomize methods ranging from conventional techniques (statistical methods, time-series analysis, signal processing, etc.) to data-driven techniques (supervised learning, reinforcement learning, deep learning, etc.). We also look at the impact that different architectural environments (Cloud, Fog, Edge) can have on the sensors ecosystem. The review points to the most promising intelligent-sensing methods, and pinpoints a set of interesting open issues and challenges.
Measuring Visual Complexity of Cluster-Based Visualizations
Feb 23, 2013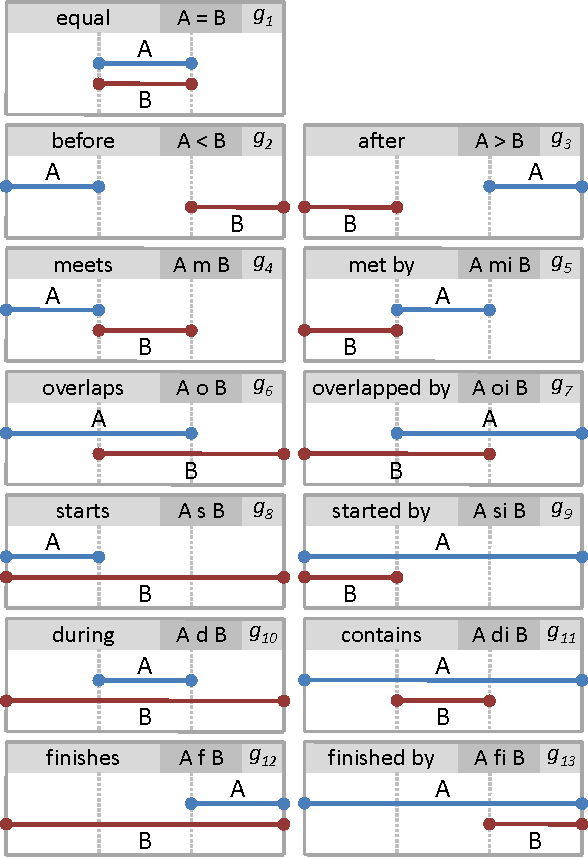
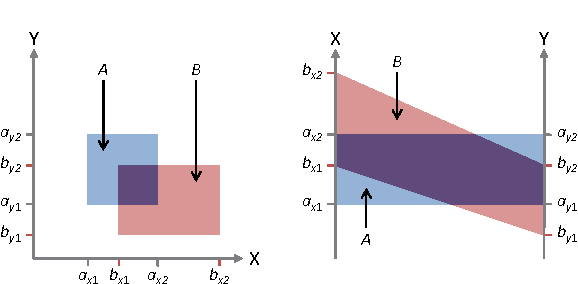
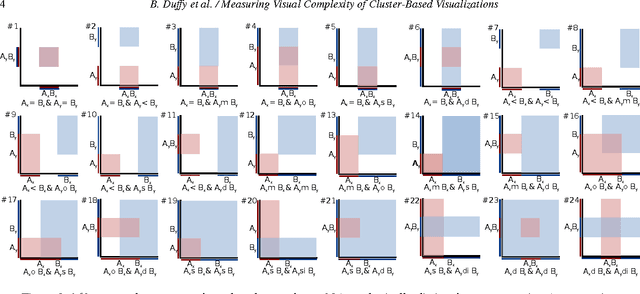

Handling visual complexity is a challenging problem in visualization owing to the subjectiveness of its definition and the difficulty in devising generalizable quantitative metrics. In this paper we address this challenge by measuring the visual complexity of two common forms of cluster-based visualizations: scatter plots and parallel coordinatess. We conceptualize visual complexity as a form of visual uncertainty, which is a measure of the degree of difficulty for humans to interpret a visual representation correctly. We propose an algorithm for estimating visual complexity for the aforementioned visualizations using Allen's interval algebra. We first establish a set of primitive 2-cluster cases in scatter plots and another set for parallel coordinatess based on symmetric isomorphism. We confirm that both are the minimal sets and verify the correctness of their members computationally. We score the uncertainty of each primitive case based on its topological properties, including the existence of overlapping regions, splitting regions and meeting points or edges. We compare a few optional scoring schemes against a set of subjective scores by humans, and identify the one that is the most consistent with the subjective scores. Finally, we extend the 2-cluster measure to k-cluster measure as a general purpose estimator of visual complexity for these two forms of cluster-based visualization.