 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline progressive instance-balanced sampling for weakly supervised object detection
Jun 21, 2022
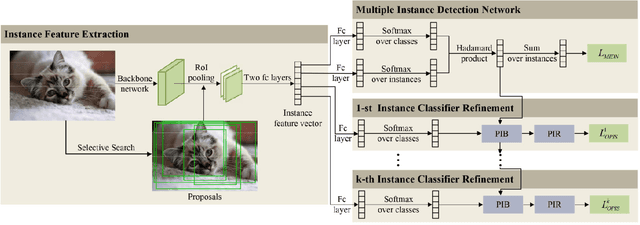
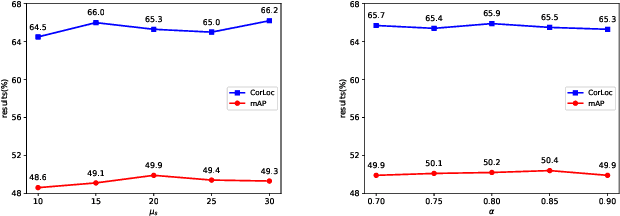
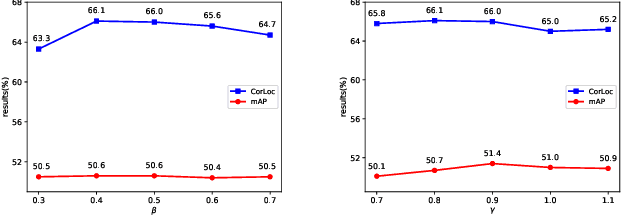
Based on multiple instance detection networks (MIDN), plenty of works have contributed tremendous efforts to weakly supervised object detection (WSOD). However, most methods neglect the fact that the overwhelming negative instances exist in each image during the training phase, which would mislead the training and make the network fall into local minima. To tackle this problem, an online progressive instance-balanced sampling (OPIS) algorithm based on hard sampling and soft sampling is proposed in this paper. The algorithm includes two modules: a progressive instance balance (PIB) module and a progressive instance reweighting (PIR) module. The PIB module combining random sampling and IoU-balanced sampling progressively mines hard negative instances while balancing positive instances and negative instances. The PIR module further utilizes classifier scores and IoUs of adjacent refinements to reweight the weights of positive instances for making the network focus on positive instances. Extensive experimental results on the PASCAL VOC 2007 and 2012 datasets demonstrate the proposed method can significantly improve the baseline, which is also comparable to many existing state-of-the-art results. In addition, compared to the baseline, the proposed method requires no extra network parameters and the supplementary training overheads are small, which could be easily integrated into other methods based on the instance classifier refinement paradigm.
flow-based clustering and spectral clustering: a comparison
Jun 20, 2022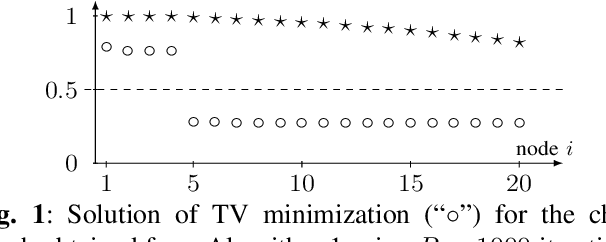
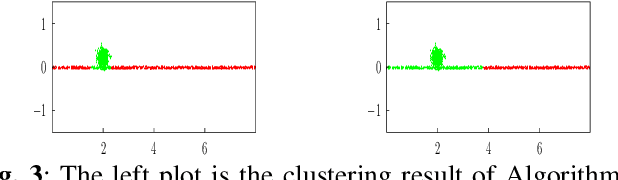

We propose and study a novel graph clustering method for data with an intrinsic network structure. Similar to spectral clustering, we exploit an intrinsic network structure of data to construct Euclidean feature vectors. These feature vectors can then be fed into basic clustering methods such as k-means or Gaussian mixture model (GMM) based soft clustering. What sets our approach apart from spectral clustering is that we do not use the eigenvectors of a graph Laplacian to construct the feature vectors. Instead, we use the solutions of total variation minimization problems to construct feature vectors that reflect connectivity between data points. Our motivation is that the solutions of total variation minimization are piece-wise constant around a given set of seed nodes. These seed nodes can be obtained from domain knowledge or by simple heuristics that are based on the network structure of data. Our results indicate that our clustering methods can cope with certain graph structures that are challenging for spectral clustering methods.