 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgeflow-based clustering and spectral clustering: a comparison
Jun 20, 2022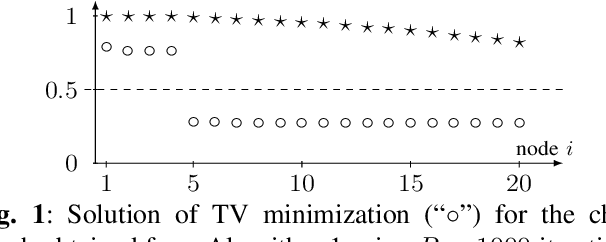
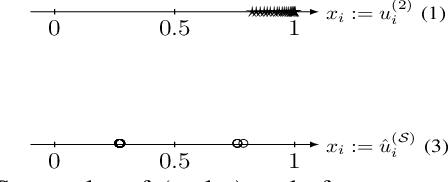
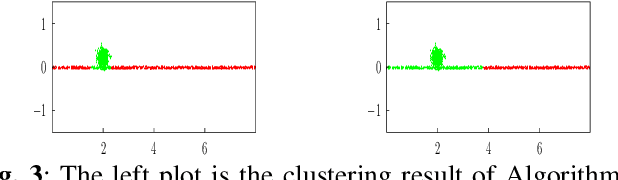

We propose and study a novel graph clustering method for data with an intrinsic network structure. Similar to spectral clustering, we exploit an intrinsic network structure of data to construct Euclidean feature vectors. These feature vectors can then be fed into basic clustering methods such as k-means or Gaussian mixture model (GMM) based soft clustering. What sets our approach apart from spectral clustering is that we do not use the eigenvectors of a graph Laplacian to construct the feature vectors. Instead, we use the solutions of total variation minimization problems to construct feature vectors that reflect connectivity between data points. Our motivation is that the solutions of total variation minimization are piece-wise constant around a given set of seed nodes. These seed nodes can be obtained from domain knowledge or by simple heuristics that are based on the network structure of data. Our results indicate that our clustering methods can cope with certain graph structures that are challenging for spectral clustering methods.
Deep Learning based Pedestrian Detection at Distance in Smart Cities
Nov 18, 2018


Generative adversarial networks (GANs) have been promising for many computer vision problems due to their powerful capabilities to enhance the data for training and test. In this paper, we leveraged GANs and proposed a new architecture with a cascded Single Shot Detector (SSD) for pedestrian detection at distance, which is yet a challenge due to the varied sizes of pedestrians in videos at distance. To overcome the low-resolution issues in pedestrian detection at distance, DCGAN is employed to improve the resolution first to reconstruct more discrinative feaures for a SSD to detect objects in images or videos. A crucial advantage of our method is that it learns a multi-scale metric to distinguish multiple objects at different distances under one image, while DCGAN serves as an encoder-decoder platform to generate parts of an image that contain better discriminative information. To measure the effectiveness of our proposed method, experiments were carried out on the Canadian Institute for Advanced Research (CIFAR) dataset, and it was demonstrated that the proposed new architecture achieved a much better detection rate, particularly on vehicles and pedestrians at distance, making it highly suitable for smart cities applications that need to discover key objects or pedestrians at distance.
Describing Human Aesthetic Perception by Deeply-learned Attributes from Flickr
May 25, 2016



Many aesthetic models in computer vision suffer from two shortcomings: 1) the low descriptiveness and interpretability of those hand-crafted aesthetic criteria (i.e., nonindicative of region-level aesthetics), and 2) the difficulty of engineering aesthetic features adaptively and automatically toward different image sets. To remedy these problems, we develop a deep architecture to learn aesthetically-relevant visual attributes from Flickr1, which are localized by multiple textual attributes in a weakly-supervised setting. More specifically, using a bag-ofwords (BoW) representation of the frequent Flickr image tags, a sparsity-constrained subspace algorithm discovers a compact set of textual attributes (e.g., landscape and sunset) for each image. Then, a weakly-supervised learning algorithm projects the textual attributes at image-level to the highly-responsive image patches at pixel-level. These patches indicate where humans look at appealing regions with respect to each textual attribute, which are employed to learn the visual attributes. Psychological and anatomical studies have shown that humans perceive visual concepts hierarchically. Hence, we normalize these patches and feed them into a five-layer convolutional neural network (CNN) to mimick the hierarchy of human perceiving the visual attributes. We apply the learned deep features on image retargeting, aesthetics ranking, and retrieval. Both subjective and objective experimental results thoroughly demonstrate the competitiveness of our approach.