 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVertex nomination schemes for membership prediction
Paper and Code
Nov 17, 2015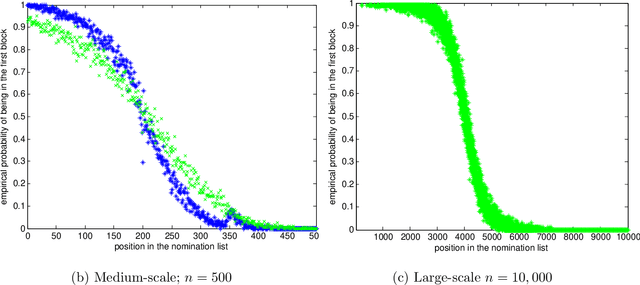

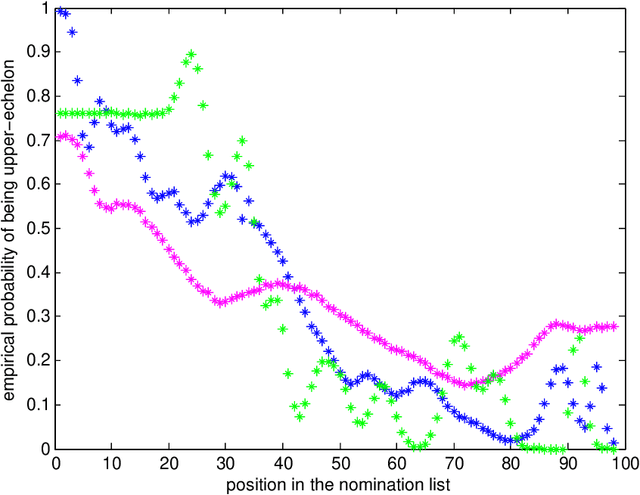

Suppose that a graph is realized from a stochastic block model where one of the blocks is of interest, but many or all of the vertices' block labels are unobserved. The task is to order the vertices with unobserved block labels into a ``nomination list'' such that, with high probability, vertices from the interesting block are concentrated near the list's beginning. We propose several vertex nomination schemes. Our basic - but principled - setting and development yields a best nomination scheme (which is a Bayes-Optimal analogue), and also a likelihood maximization nomination scheme that is practical to implement when there are a thousand vertices, and which is empirically near-optimal when the number of vertices is small enough to allow comparison to the best nomination scheme. We then illustrate the robustness of the likelihood maximization nomination scheme to the modeling challenges inherent in real data, using examples which include a social network involving human trafficking, the Enron Graph, a worm brain connectome and a political blog network.