 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDAHRS: Divergence-Aware Hallucination-Remediated SRL Projection
Jul 12, 2024Semantic role labeling (SRL) enriches many downstream applications, e.g., machine translation, question answering, summarization, and stance/belief detection. However, building multilingual SRL models is challenging due to the scarcity of semantically annotated corpora for multiple languages. Moreover, state-of-the-art SRL projection (XSRL) based on large language models (LLMs) yields output that is riddled with spurious role labels. Remediation of such hallucinations is not straightforward due to the lack of explainability of LLMs. We show that hallucinated role labels are related to naturally occurring divergence types that interfere with initial alignments. We implement Divergence-Aware Hallucination-Remediated SRL projection (DAHRS), leveraging linguistically-informed alignment remediation followed by greedy First-Come First-Assign (FCFA) SRL projection. DAHRS improves the accuracy of SRL projection without additional transformer-based machinery, beating XSRL in both human and automatic comparisons, and advancing beyond headwords to accommodate phrase-level SRL projection (e.g., EN-FR, EN-ES). Using CoNLL-2009 as our ground truth, we achieve a higher word-level F1 over XSRL: 87.6% vs. 77.3% (EN-FR) and 89.0% vs. 82.7% (EN-ES). Human phrase-level assessments yield 89.1% (EN-FR) and 91.0% (EN-ES). We also define a divergence metric to adapt our approach to other language pairs (e.g., English-Tagalog).
From Stance to Concern: Adaptation of Propositional Analysis to New Tasks and Domains
Mar 20, 2022



We present a generalized paradigm for adaptation of propositional analysis (predicate-argument pairs) to new tasks and domains. We leverage an analogy between stances (belief-driven sentiment) and concerns (topical issues with moral dimensions/endorsements) to produce an explanatory representation. A key contribution is the combination of semi-automatic resource building for extraction of domain-dependent concern types (with 2-4 hours of human labor per domain) and an entirely automatic procedure for extraction of domain-independent moral dimensions and endorsement values. Prudent (automatic) selection of terms from propositional structures for lexical expansion (via semantic similarity) produces new moral dimension lexicons at three levels of granularity beyond a strong baseline lexicon. We develop a ground truth (GT) based on expert annotators and compare our concern detection output to GT, to yield 231% improvement in recall over baseline, with only a 10% loss in precision. F1 yields 66% improvement over baseline and 97.8% of human performance. Our lexically based approach yields large savings over approaches that employ costly human labor and model building. We provide to the community a newly expanded moral dimension/value lexicon, annotation guidelines, and GT.
Learning to Plan and Realize Separately for Open-Ended Dialogue Systems
Oct 04, 2020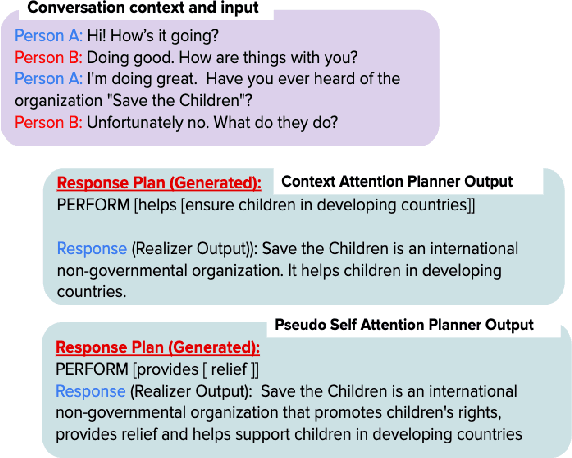

Achieving true human-like ability to conduct a conversation remains an elusive goal for open-ended dialogue systems. We posit this is because extant approaches towards natural language generation (NLG) are typically construed as end-to-end architectures that do not adequately model human generation processes. To investigate, we decouple generation into two separate phases: planning and realization. In the planning phase, we train two planners to generate plans for response utterances. The realization phase uses response plans to produce an appropriate response. Through rigorous evaluations, both automated and human, we demonstrate that decoupling the process into planning and realization performs better than an end-to-end approach.
The Panacea Threat Intelligence and Active Defense Platform
Apr 20, 2020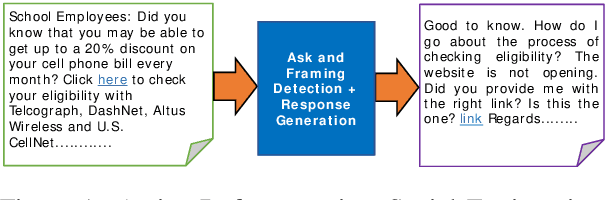
We describe Panacea, a system that supports natural language processing (NLP) components for active defenses against social engineering attacks. We deploy a pipeline of human language technology, including Ask and Framing Detection, Named Entity Recognition, Dialogue Engineering, and Stylometry. Panacea processes modern message formats through a plug-in architecture to accommodate innovative approaches for message analysis, knowledge representation and dialogue generation. The novelty of the Panacea system is that uses NLP for cyber defense and engages the attacker using bots to elicit evidence to attribute to the attacker and to waste the attacker's time and resources.
Adaptation of a Lexical Organization for Social Engineering Detection and Response Generation
Apr 20, 2020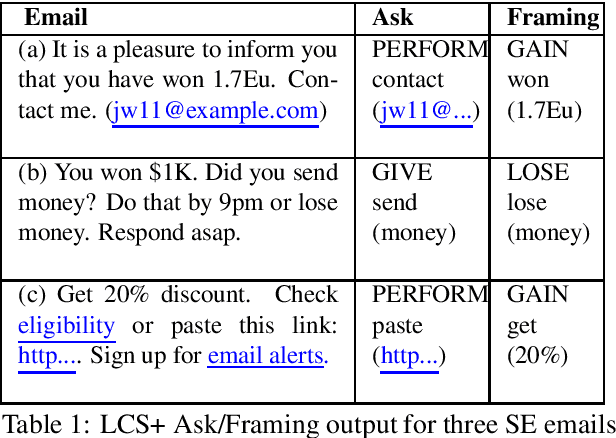

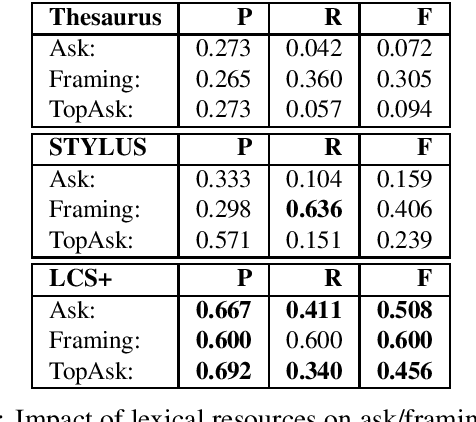
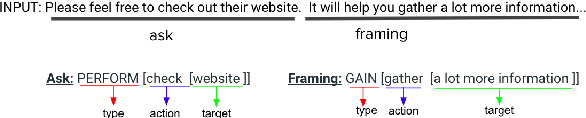
We present a paradigm for extensible lexicon development based on Lexical Conceptual Structure to support social engineering detection and response generation. We leverage the central notions of ask (elicitation of behaviors such as providing access to money) and framing (risk/reward implied by the ask). We demonstrate improvements in ask/framing detection through refinements to our lexical organization and show that response generation qualitatively improves as ask/framing detection performance improves. The paradigm presents a systematic and efficient approach to resource adaptation for improved task-specific performance.
Detecting Asks in SE attacks: Impact of Linguistic and Structural Knowledge
Feb 25, 2020
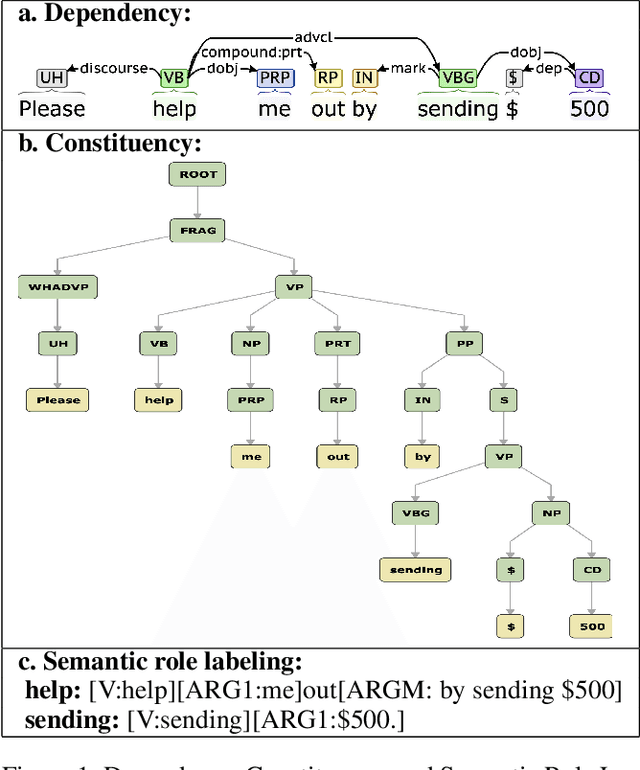
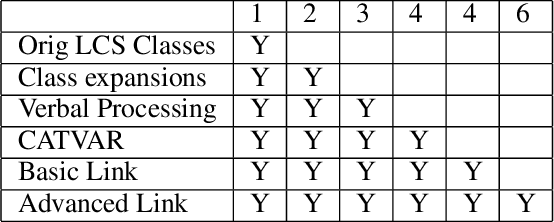
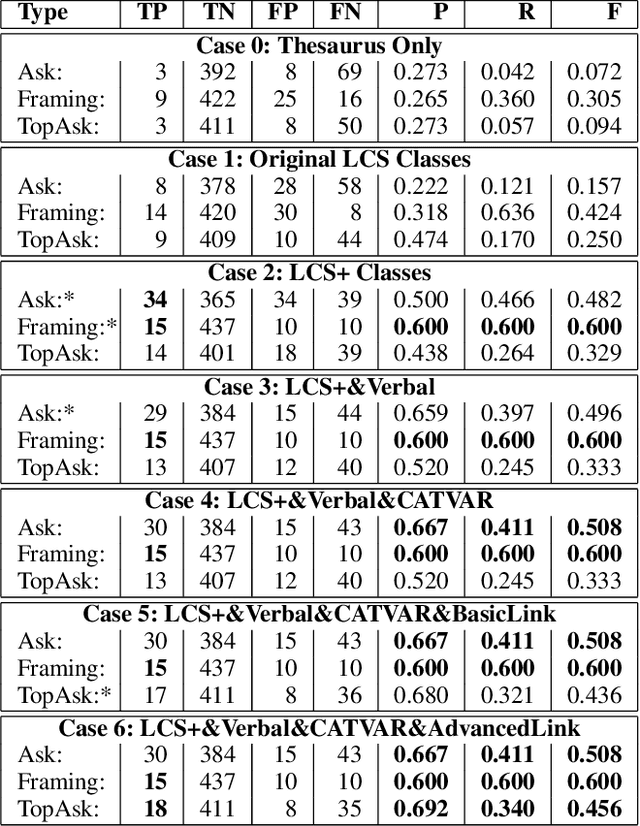
Social engineers attempt to manipulate users into undertaking actions such as downloading malware by clicking links or providing access to money or sensitive information. Natural language processing, computational sociolinguistics, and media-specific structural clues provide a means for detecting both the ask (e.g., buy gift card) and the risk/reward implied by the ask, which we call framing (e.g., lose your job, get a raise). We apply linguistic resources such as Lexical Conceptual Structure to tackle ask detection and also leverage structural clues such as links and their proximity to identified asks to improve confidence in our results. Our experiments indicate that the performance of ask detection, framing detection, and identification of the top ask is improved by linguistically motivated classes coupled with structural clues such as links. Our approach is implemented in a system that informs users about social engineering risk situations.