 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Similarity is a Spurious Measure of Comic Understanding: Lessons Learned from Hallucinations in a Benchmarking Experiment
Mar 02, 2026A system that enables blind or visually impaired users to access comics/manga would introduce a new medium of storytelling to this community. However, no such system currently exists. Generative vision-language models (VLMs) have shown promise in describing images and understanding comics, but most research on comic understanding is limited to panel-level analysis. To fully support blind and visually impaired users, greater attention must be paid to page-level understanding and interpretation. In this work, we present a preliminary benchmark of VLM performance on comic interpretation tasks. We identify and categorize hallucinations that emerge during this process, organizing them into generalized object-hallucination taxonomies. We conclude with guidance on future research, emphasizing hallucination mitigation and improved data curation for comic interpretation.
Multilingual Target-Stance Extraction
Oct 25, 2025Social media enables data-driven analysis of public opinion on contested issues. Target-Stance Extraction (TSE) is the task of identifying the target discussed in a document and the document's stance towards that target. Many works classify stance towards a given target in a multilingual setting, but all prior work in TSE is English-only. This work introduces the first multilingual TSE benchmark, spanning Catalan, Estonian, French, Italian, Mandarin, and Spanish corpora. It manages to extend the original TSE pipeline to a multilingual setting without requiring separate models for each language. Our model pipeline achieves a modest F1 score of 12.78, underscoring the increased difficulty of the multilingual task relative to English-only setups and highlighting target prediction as the primary bottleneck. We are also the first to demonstrate the sensitivity of TSE's F1 score to different target verbalizations. Together these serve as a much-needed baseline for resources, algorithms, and evaluation criteria in multilingual TSE.
AMREx: AMR for Explainable Fact Verification
Nov 02, 2024



With the advent of social media networks and the vast amount of information circulating through them, automatic fact verification is an essential component to prevent the spread of misinformation. It is even more useful to have fact verification systems that provide explanations along with their classifications to ensure accurate predictions. To address both of these requirements, we implement AMREx, an Abstract Meaning Representation (AMR)-based veracity prediction and explanation system for fact verification using a combination of Smatch, an AMR evaluation metric to measure meaning containment and textual similarity, and demonstrate its effectiveness in producing partially explainable justifications using two community standard fact verification datasets, FEVER and AVeriTeC. AMREx surpasses the AVeriTec baseline accuracy showing the effectiveness of our approach for real-world claim verification. It follows an interpretable pipeline and returns an explainable AMR node mapping to clarify the system's veracity predictions when applicable. We further demonstrate that AMREx output can be used to prompt LLMs to generate natural-language explanations using the AMR mappings as a guide to lessen the probability of hallucinations.
DAHRS: Divergence-Aware Hallucination-Remediated SRL Projection
Jul 12, 2024Semantic role labeling (SRL) enriches many downstream applications, e.g., machine translation, question answering, summarization, and stance/belief detection. However, building multilingual SRL models is challenging due to the scarcity of semantically annotated corpora for multiple languages. Moreover, state-of-the-art SRL projection (XSRL) based on large language models (LLMs) yields output that is riddled with spurious role labels. Remediation of such hallucinations is not straightforward due to the lack of explainability of LLMs. We show that hallucinated role labels are related to naturally occurring divergence types that interfere with initial alignments. We implement Divergence-Aware Hallucination-Remediated SRL projection (DAHRS), leveraging linguistically-informed alignment remediation followed by greedy First-Come First-Assign (FCFA) SRL projection. DAHRS improves the accuracy of SRL projection without additional transformer-based machinery, beating XSRL in both human and automatic comparisons, and advancing beyond headwords to accommodate phrase-level SRL projection (e.g., EN-FR, EN-ES). Using CoNLL-2009 as our ground truth, we achieve a higher word-level F1 over XSRL: 87.6% vs. 77.3% (EN-FR) and 89.0% vs. 82.7% (EN-ES). Human phrase-level assessments yield 89.1% (EN-FR) and 91.0% (EN-ES). We also define a divergence metric to adapt our approach to other language pairs (e.g., English-Tagalog).
Learning to Plan and Realize Separately for Open-Ended Dialogue Systems
Oct 04, 2020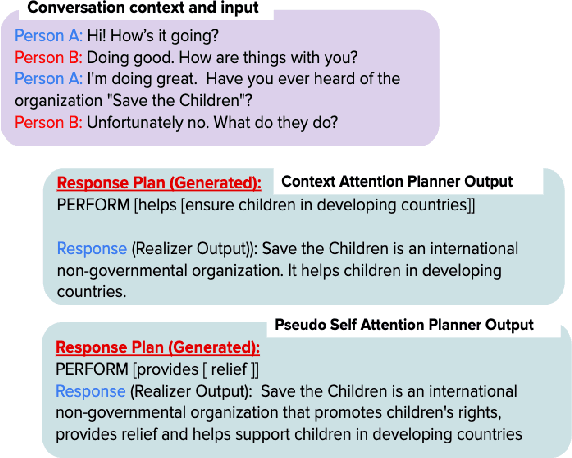
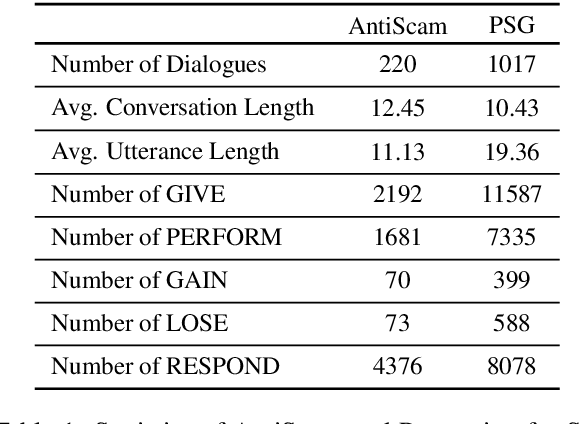
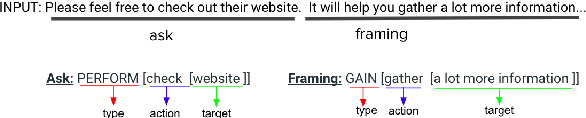

Achieving true human-like ability to conduct a conversation remains an elusive goal for open-ended dialogue systems. We posit this is because extant approaches towards natural language generation (NLG) are typically construed as end-to-end architectures that do not adequately model human generation processes. To investigate, we decouple generation into two separate phases: planning and realization. In the planning phase, we train two planners to generate plans for response utterances. The realization phase uses response plans to produce an appropriate response. Through rigorous evaluations, both automated and human, we demonstrate that decoupling the process into planning and realization performs better than an end-to-end approach.
Statistical modality tagging from rule-based annotations and crowdsourcing
Mar 04, 2015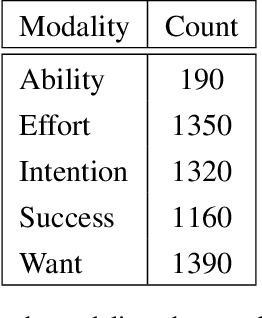
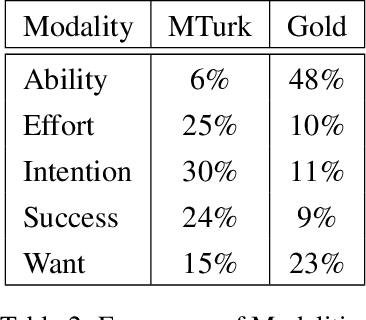
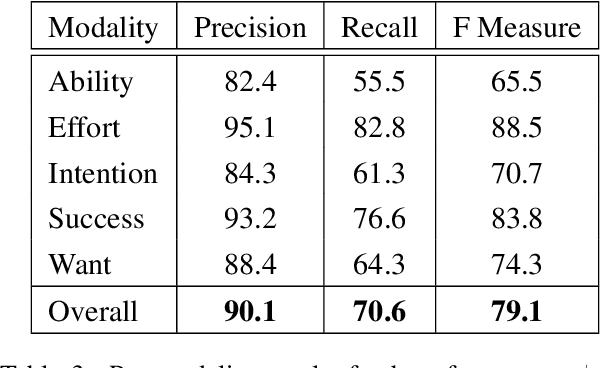
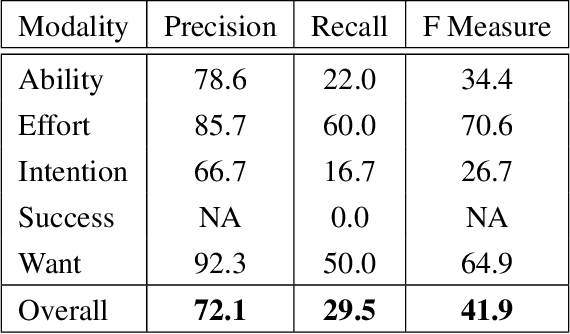
We explore training an automatic modality tagger. Modality is the attitude that a speaker might have toward an event or state. One of the main hurdles for training a linguistic tagger is gathering training data. This is particularly problematic for training a tagger for modality because modality triggers are sparse for the overwhelming majority of sentences. We investigate an approach to automatically training a modality tagger where we first gathered sentences based on a high-recall simple rule-based modality tagger and then provided these sentences to Mechanical Turk annotators for further annotation. We used the resulting set of training data to train a precise modality tagger using a multi-class SVM that delivers good performance.
* 8 pages, 6 tables; appeared in Proceedings of the Workshop on Extra-Propositional Aspects of Meaning in Computational Linguistics, July 2012; In Proceedings of the Workshop on Extra-Propositional Aspects of Meaning in Computational Linguistics, pages 57-64, Jeju, Republic of Korea, July 2012. Association for Computational Linguistics
Generating Extractive Summaries of Scientific Paradigms
Feb 04, 2014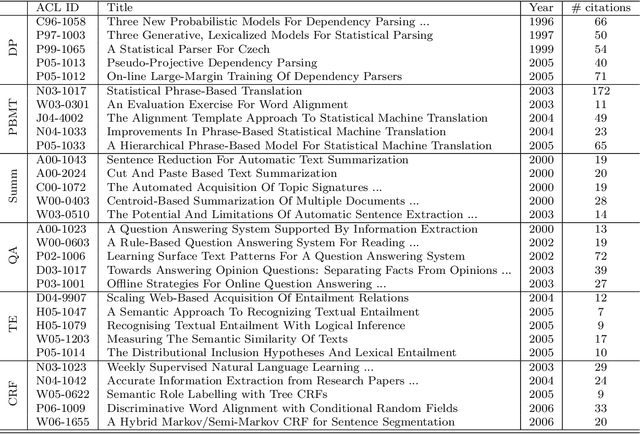
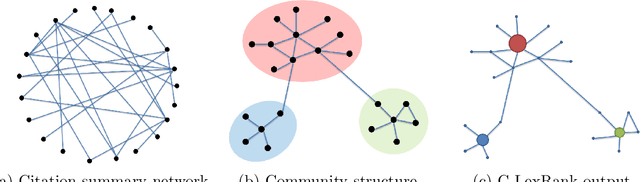

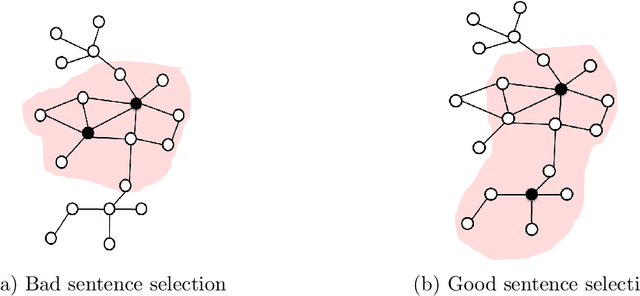
Researchers and scientists increasingly find themselves in the position of having to quickly understand large amounts of technical material. Our goal is to effectively serve this need by using bibliometric text mining and summarization techniques to generate summaries of scientific literature. We show how we can use citations to produce automatically generated, readily consumable, technical extractive summaries. We first propose C-LexRank, a model for summarizing single scientific articles based on citations, which employs community detection and extracts salient information-rich sentences. Next, we further extend our experiments to summarize a set of papers, which cover the same scientific topic. We generate extractive summaries of a set of Question Answering (QA) and Dependency Parsing (DP) papers, their abstracts, and their citation sentences and show that citations have unique information amenable to creating a summary.