 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Extractive Summaries of Scientific Paradigms
Feb 04, 2014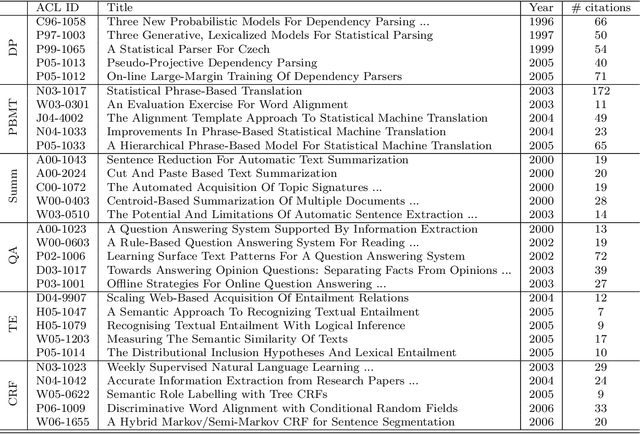
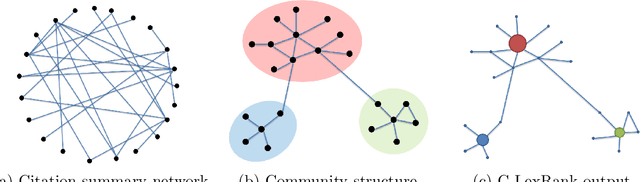

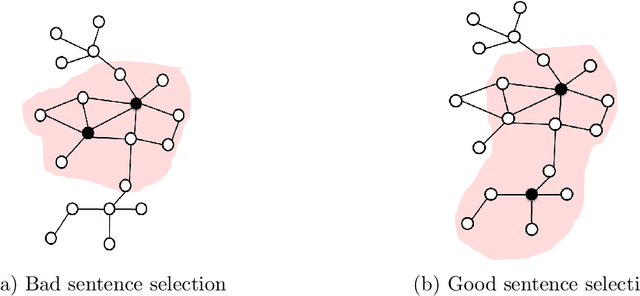
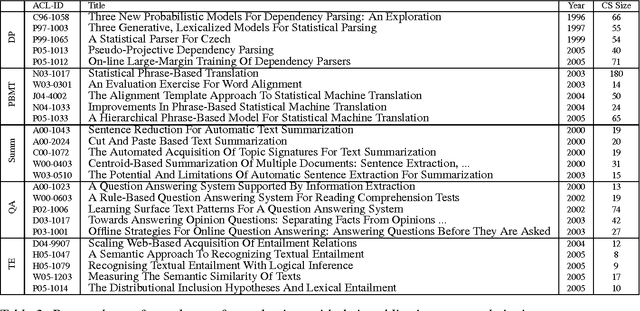
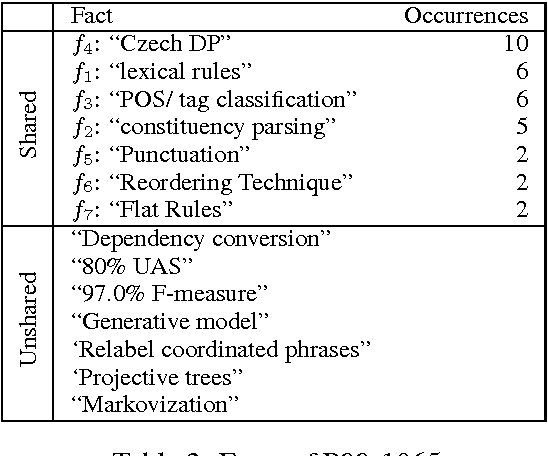
Researchers and scientists increasingly find themselves in the position of having to quickly understand large amounts of technical material. Our goal is to effectively serve this need by using bibliometric text mining and summarization techniques to generate summaries of scientific literature. We show how we can use citations to produce automatically generated, readily consumable, technical extractive summaries. We first propose C-LexRank, a model for summarizing single scientific articles based on citations, which employs community detection and extracts salient information-rich sentences. Next, we further extend our experiments to summarize a set of papers, which cover the same scientific topic. We generate extractive summaries of a set of Question Answering (QA) and Dependency Parsing (DP) papers, their abstracts, and their citation sentences and show that citations have unique information amenable to creating a summary.
A Computational Analysis of Collective Discourse
Apr 17, 2012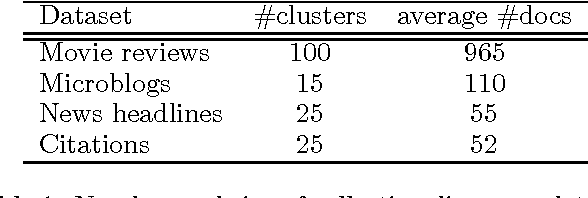
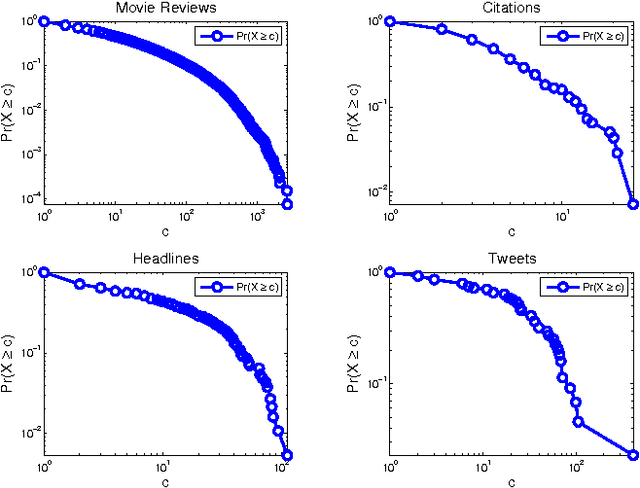
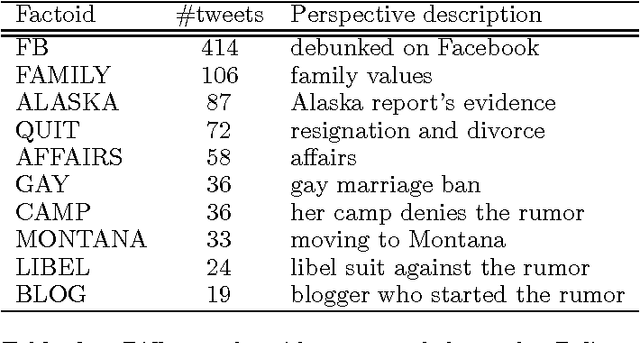
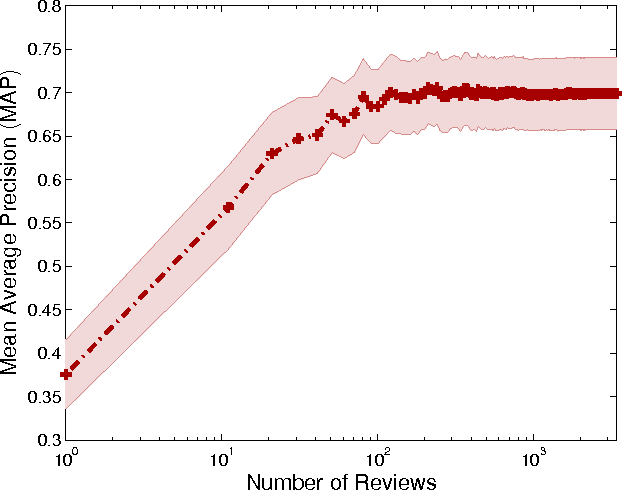
This paper is focused on the computational analysis of collective discourse, a collective behavior seen in non-expert content contributions in online social media. We collect and analyze a wide range of real-world collective discourse datasets from movie user reviews to microblogs and news headlines to scientific citations. We show that all these datasets exhibit diversity of perspective, a property seen in other collective systems and a criterion in wise crowds. Our experiments also confirm that the network of different perspective co-occurrences exhibits the small-world property with high clustering of different perspectives. Finally, we show that non-expert contributions in collective discourse can be used to answer simple questions that are otherwise hard to answer.
Scientific Paper Summarization Using Citation Summary Networks
Jul 10, 2008
Quickly moving to a new area of research is painful for researchers due to the vast amount of scientific literature in each field of study. One possible way to overcome this problem is to summarize a scientific topic. In this paper, we propose a model of summarizing a single article, which can be further used to summarize an entire topic. Our model is based on analyzing others' viewpoint of the target article's contributions and the study of its citation summary network using a clustering approach.