 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRome was built in 1776: A Case Study on Factual Correctness in Knowledge-Grounded Response Generation
Oct 11, 2021


Recently neural response generation models have leveraged large pre-trained transformer models and knowledge snippets to generate relevant and informative responses. However, this does not guarantee that generated responses are factually correct. In this paper, we examine factual correctness in knowledge-grounded neural response generation models. We present a human annotation setup to identify three different response types: responses that are factually consistent with respect to the input knowledge, responses that contain hallucinated knowledge, and non-verifiable chitchat style responses. We use this setup to annotate responses generated using different stateof-the-art models, knowledge snippets, and decoding strategies. In addition, to facilitate the development of a factual consistency detector, we automatically create a new corpus called Conv-FEVER that is adapted from the Wizard of Wikipedia dataset and includes factually consistent and inconsistent responses. We demonstrate the benefit of our Conv-FEVER dataset by showing that the models trained on this data perform reasonably well to detect factually inconsistent responses with respect to the provided knowledge through evaluation on our human annotated data. We will release the Conv-FEVER dataset and the human annotated responses.
The GEM Benchmark: Natural Language Generation, its Evaluation and Metrics
Feb 03, 2021
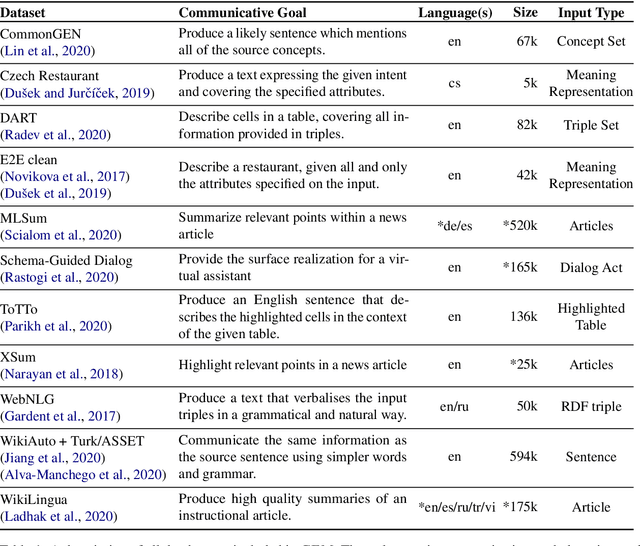
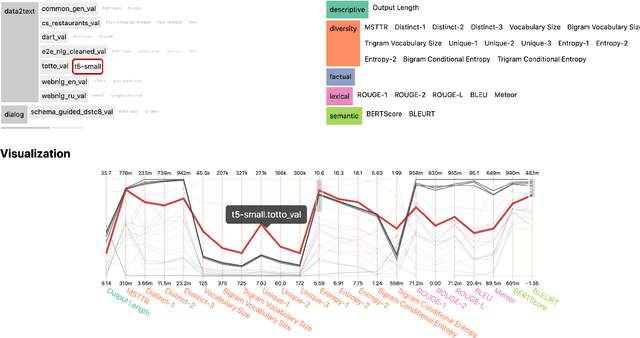
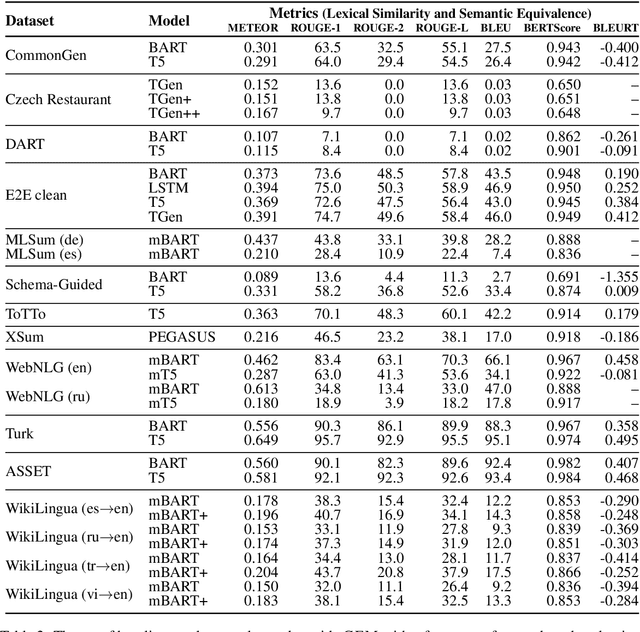
We introduce GEM, a living benchmark for natural language Generation (NLG), its Evaluation, and Metrics. Measuring progress in NLG relies on a constantly evolving ecosystem of automated metrics, datasets, and human evaluation standards. However, due to this moving target, new models often still evaluate on divergent anglo-centric corpora with well-established, but flawed, metrics. This disconnect makes it challenging to identify the limitations of current models and opportunities for progress. Addressing this limitation, GEM provides an environment in which models can easily be applied to a wide set of corpora and evaluation strategies can be tested. Regular updates to the benchmark will help NLG research become more multilingual and evolve the challenge alongside models. This paper serves as the description of the initial release for which we are organizing a shared task at our ACL 2021 Workshop and to which we invite the entire NLG community to participate.
Local Knowledge Powered Conversational Agents
Oct 20, 2020
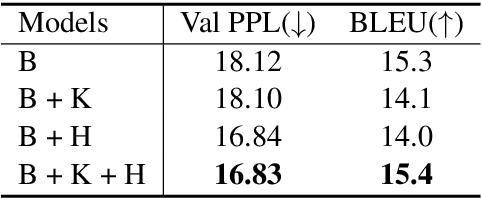
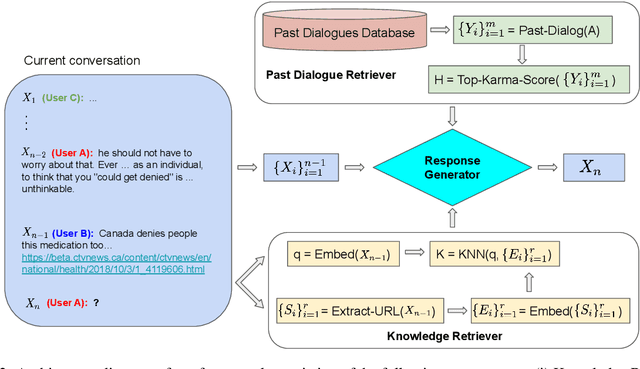

State-of-the-art conversational agents have advanced significantly in conjunction with the use of large transformer-based language models. However, even with these advancements, conversational agents still lack the ability to produce responses that are informative and coherent with the local context. In this work, we propose a dialog framework that incorporates both local knowledge as well as users' past dialogues to generate high quality conversations. We introduce an approach to build a dataset based on Reddit conversations, where outbound URL links are widely available in the conversations and the hyperlinked documents can be naturally included as local external knowledge. Using our framework and dataset, we demonstrate that incorporating local knowledge can largely improve informativeness, coherency and realisticness measures using human evaluations. In particular, our approach consistently outperforms the state-of-the-art conversational model on the Reddit dataset across all three measures. We also find that scaling the size of our models from 117M to 8.3B parameters yields consistent improvement of validation perplexity as well as human evaluated metrics. Our model with 8.3B parameters can generate human-like responses as rated by various human evaluations in a single-turn dialog setting.
Learning to Plan and Realize Separately for Open-Ended Dialogue Systems
Oct 04, 2020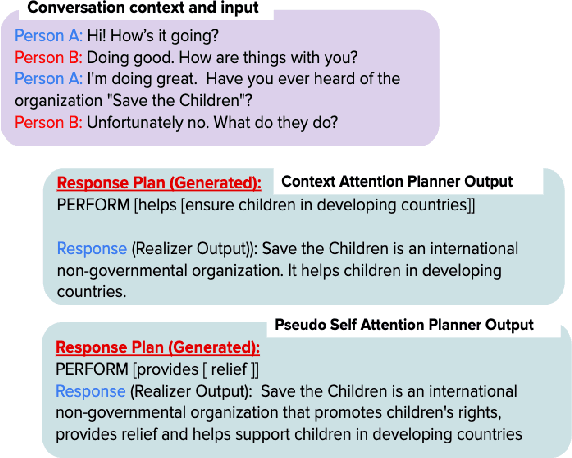

Achieving true human-like ability to conduct a conversation remains an elusive goal for open-ended dialogue systems. We posit this is because extant approaches towards natural language generation (NLG) are typically construed as end-to-end architectures that do not adequately model human generation processes. To investigate, we decouple generation into two separate phases: planning and realization. In the planning phase, we train two planners to generate plans for response utterances. The realization phase uses response plans to produce an appropriate response. Through rigorous evaluations, both automated and human, we demonstrate that decoupling the process into planning and realization performs better than an end-to-end approach.
The Panacea Threat Intelligence and Active Defense Platform
Apr 20, 2020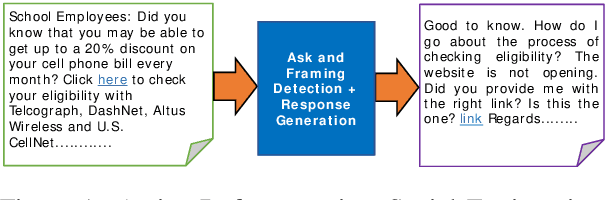
We describe Panacea, a system that supports natural language processing (NLP) components for active defenses against social engineering attacks. We deploy a pipeline of human language technology, including Ask and Framing Detection, Named Entity Recognition, Dialogue Engineering, and Stylometry. Panacea processes modern message formats through a plug-in architecture to accommodate innovative approaches for message analysis, knowledge representation and dialogue generation. The novelty of the Panacea system is that uses NLP for cyber defense and engages the attacker using bots to elicit evidence to attribute to the attacker and to waste the attacker's time and resources.
Adaptation of a Lexical Organization for Social Engineering Detection and Response Generation
Apr 20, 2020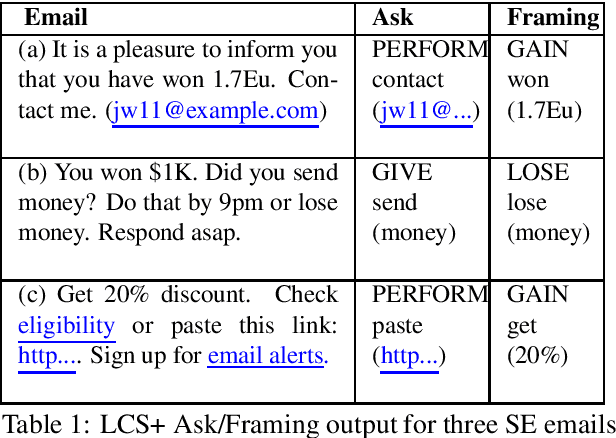

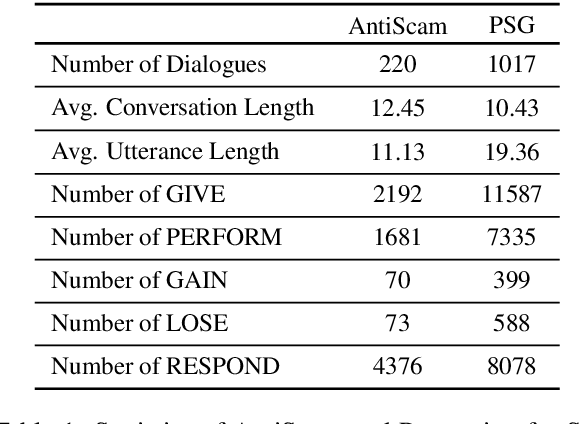
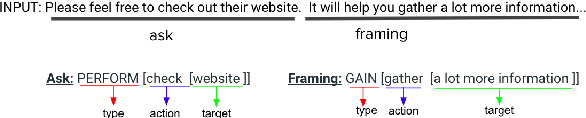
We present a paradigm for extensible lexicon development based on Lexical Conceptual Structure to support social engineering detection and response generation. We leverage the central notions of ask (elicitation of behaviors such as providing access to money) and framing (risk/reward implied by the ask). We demonstrate improvements in ask/framing detection through refinements to our lexical organization and show that response generation qualitatively improves as ask/framing detection performance improves. The paradigm presents a systematic and efficient approach to resource adaptation for improved task-specific performance.
Studying the Effects of Cognitive Biases in Evaluation of Conversational Agents
Feb 26, 2020
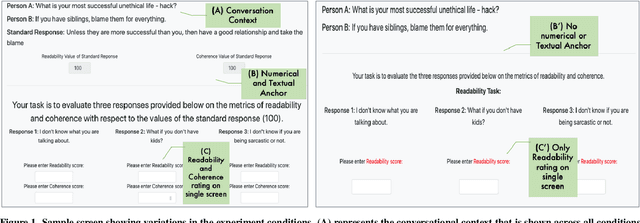


Humans quite frequently interact with conversational agents. The rapid advancement in generative language modeling through neural networks has helped advance the creation of intelligent conversational agents. Researchers typically evaluate the output of their models through crowdsourced judgments, but there are no established best practices for conducting such studies. Moreover, it is unclear if cognitive biases in decision-making are affecting crowdsourced workers' judgments when they undertake these tasks. To investigate, we conducted a between-subjects study with 77 crowdsourced workers to understand the role of cognitive biases, specifically anchoring bias, when humans are asked to evaluate the output of conversational agents. Our results provide insight into how best to evaluate conversational agents. We find increased consistency in ratings across two experimental conditions may be a result of anchoring bias. We also determine that external factors such as time and prior experience in similar tasks have effects on inter-rater consistency.
Detecting Asks in SE attacks: Impact of Linguistic and Structural Knowledge
Feb 25, 2020
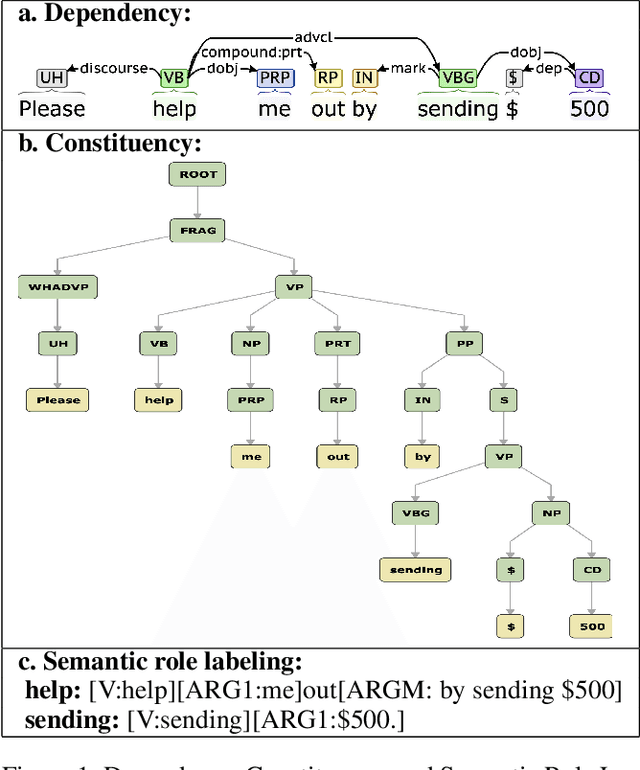
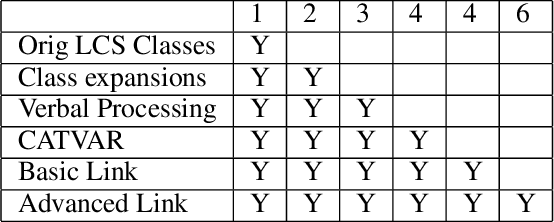
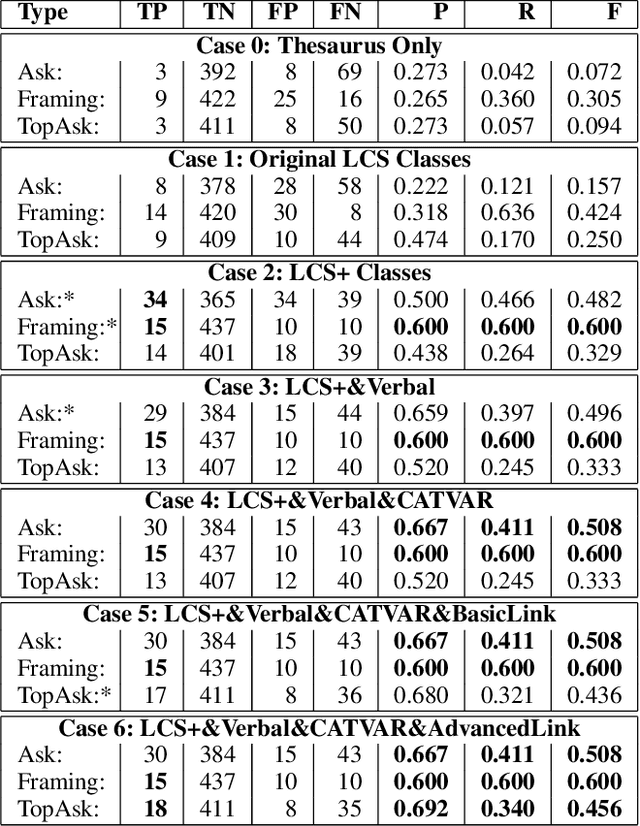
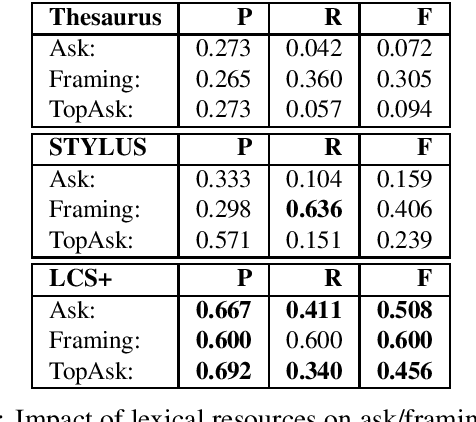
Social engineers attempt to manipulate users into undertaking actions such as downloading malware by clicking links or providing access to money or sensitive information. Natural language processing, computational sociolinguistics, and media-specific structural clues provide a means for detecting both the ask (e.g., buy gift card) and the risk/reward implied by the ask, which we call framing (e.g., lose your job, get a raise). We apply linguistic resources such as Lexical Conceptual Structure to tackle ask detection and also leverage structural clues such as links and their proximity to identified asks to improve confidence in our results. Our experiments indicate that the performance of ask detection, framing detection, and identification of the top ask is improved by linguistically motivated classes coupled with structural clues such as links. Our approach is implemented in a system that informs users about social engineering risk situations.
Natural Language Generation Using Reinforcement Learning with External Rewards
Nov 26, 2019
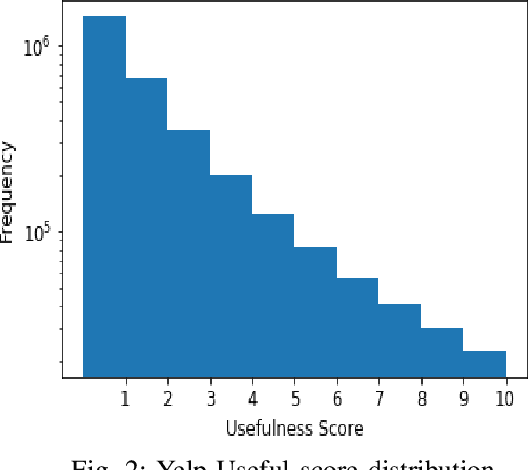


We propose an approach towards natural language generation using a bidirectional encoder-decoder which incorporates external rewards through reinforcement learning (RL). We use attention mechanism and maximum mutual information as an initial objective function using RL. Using a two-part training scheme, we train an external reward analyzer to predict the external rewards and then use the predicted rewards to maximize the expected rewards (both internal and external). We evaluate the system on two standard dialogue corpora - Cornell Movie Dialog Corpus and Yelp Restaurant Review Corpus. We report standard evaluation metrics including BLEU, ROUGE-L, and perplexity as well as human evaluation to validate our approach.
Emotional Neural Language Generation Grounded in Situational Contexts
Nov 25, 2019



Emotional language generation is one of the keys to human-like artificial intelligence. Humans use different type of emotions depending on the situation of the conversation. Emotions also play an important role in mediating the engagement level with conversational partners. However, current conversational agents do not effectively account for emotional content in the language generation process. To address this problem, we develop a language modeling approach that generates affective content when the dialogue is situated in a given context. We use the recently released Empathetic-Dialogues corpus to build our models. Through detailed experiments, we find that our approach outperforms the state-of-the-art method on the perplexity metric by about 5 points and achieves a higher BLEU metric score.