 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProject Imaging-X: A Survey of 1000+ Open-Access Medical Imaging Datasets for Foundation Model Development
Mar 29, 2026Foundation models have demonstrated remarkable success across diverse domains and tasks, primarily due to the thrive of large-scale, diverse, and high-quality datasets. However, in the field of medical imaging, the curation and assembling of such medical datasets are highly challenging due to the reliance on clinical expertise and strict ethical and privacy constraints, resulting in a scarcity of large-scale unified medical datasets and hindering the development of powerful medical foundation models. In this work, we present the largest survey to date of medical image datasets, covering over 1,000 open-access datasets with a systematic catalog of their modalities, tasks, anatomies, annotations, limitations, and potential for integration. Our analysis exposes a landscape that is modest in scale, fragmented across narrowly scoped tasks, and unevenly distributed across organs and modalities, which in turn limits the utility of existing medical image datasets for developing versatile and robust medical foundation models. To turn fragmentation into scale, we propose a metadata-driven fusion paradigm (MDFP) that integrates public datasets with shared modalities or tasks, thereby transforming multiple small data silos into larger, more coherent resources. Building on MDFP, we release an interactive discovery portal that enables end-to-end, automated medical image dataset integration, and compile all surveyed datasets into a unified, structured table that clearly summarizes their key characteristics and provides reference links, offering the community an accessible and comprehensive repository. By charting the current terrain and offering a principled path to dataset consolidation, our survey provides a practical roadmap for scaling medical imaging corpora, supporting faster data discovery, more principled dataset creation, and more capable medical foundation models.
MedFMC: A Real-world Dataset and Benchmark For Foundation Model Adaptation in Medical Image Classification
Jun 16, 2023Foundation models, often pre-trained with large-scale data, have achieved paramount success in jump-starting various vision and language applications. Recent advances further enable adapting foundation models in downstream tasks efficiently using only a few training samples, e.g., in-context learning. Yet, the application of such learning paradigms in medical image analysis remains scarce due to the shortage of publicly accessible data and benchmarks. In this paper, we aim at approaches adapting the foundation models for medical image classification and present a novel dataset and benchmark for the evaluation, i.e., examining the overall performance of accommodating the large-scale foundation models downstream on a set of diverse real-world clinical tasks. We collect five sets of medical imaging data from multiple institutes targeting a variety of real-world clinical tasks (22,349 images in total), i.e., thoracic diseases screening in X-rays, pathological lesion tissue screening, lesion detection in endoscopy images, neonatal jaundice evaluation, and diabetic retinopathy grading. Results of multiple baseline methods are demonstrated using the proposed dataset from both accuracy and cost-effective perspectives.
Mixed Supervision Learning for Whole Slide Image Classification
Jul 05, 2021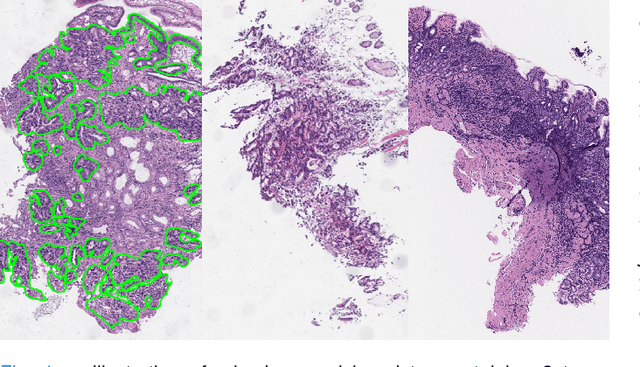
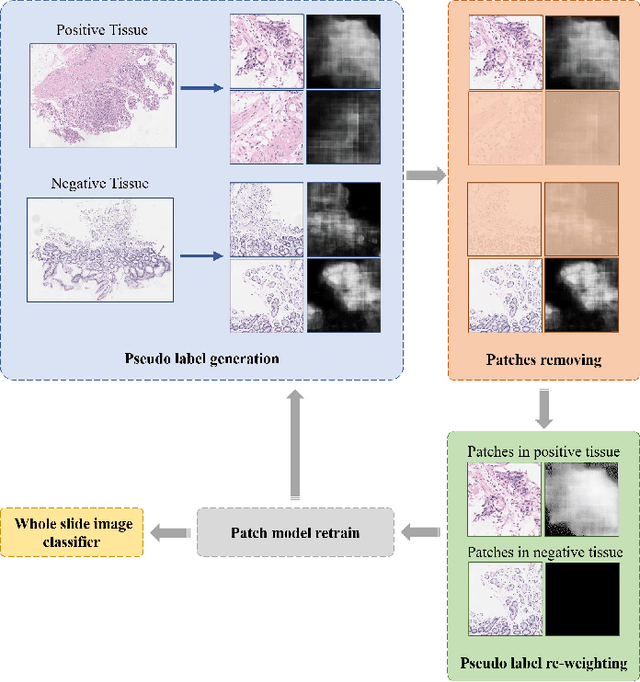
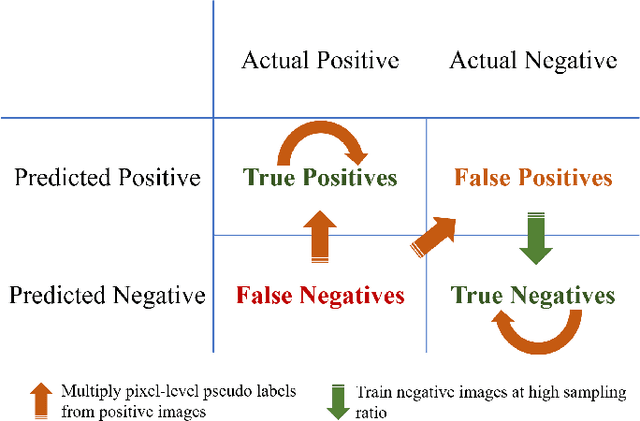
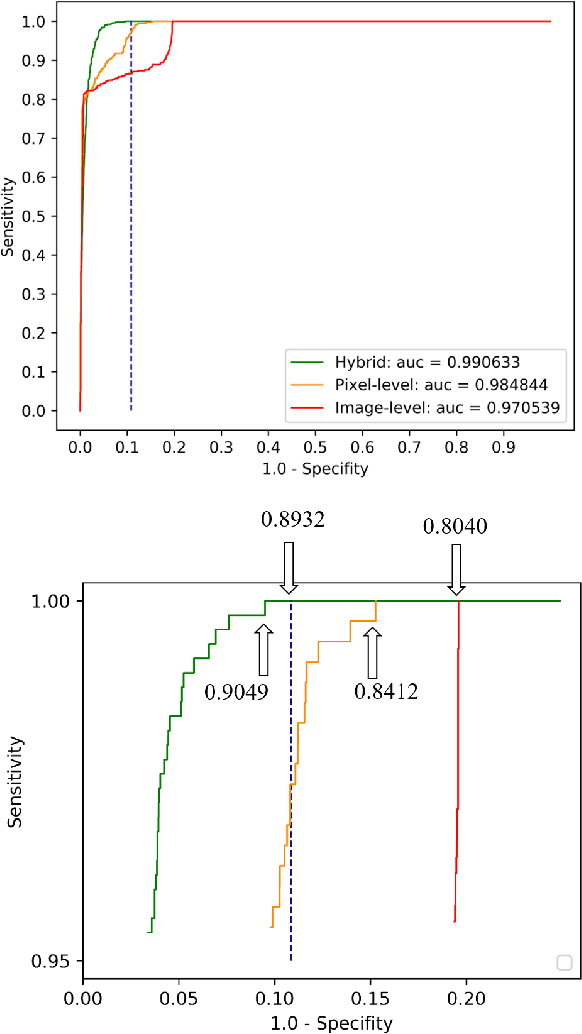
Weak supervision learning on classification labels has demonstrated high performance in various tasks. When a few pixel-level fine annotations are also affordable, it is natural to leverage both of the pixel-level (e.g., segmentation) and image level (e.g., classification) annotation to further improve the performance. In computational pathology, however, such weak or mixed supervision learning is still a challenging task, since the high resolution of whole slide images makes it unattainable to perform end-to-end training of classification models. An alternative approach is to analyze such data by patch-base model training, i.e., using self-supervised learning to generate pixel-level pseudo labels for patches. However, such methods usually have model drifting issues, i.e., hard to converge, because the noise accumulates during the self-training process. To handle those problems, we propose a mixed supervision learning framework for super high-resolution images to effectively utilize their various labels (e.g., sufficient image-level coarse annotations and a few pixel-level fine labels). During the patch training stage, this framework can make use of coarse image-level labels to refine self-supervised learning and generate high-quality pixel-level pseudo labels. A comprehensive strategy is proposed to suppress pixel-level false positives and false negatives. Three real-world datasets with very large number of images (i.e., more than 10,000 whole slide images) and various types of labels are used to evaluate the effectiveness of mixed supervision learning. We reduced the false positive rate by around one third compared to state of the art while retaining 100% sensitivity, in the task of image-level classification.
The Panacea Threat Intelligence and Active Defense Platform
Apr 20, 2020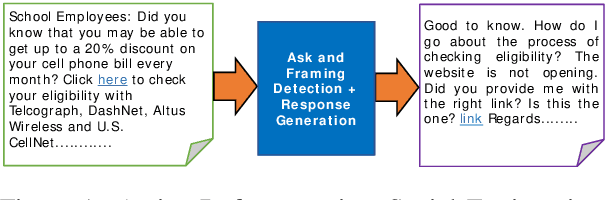
We describe Panacea, a system that supports natural language processing (NLP) components for active defenses against social engineering attacks. We deploy a pipeline of human language technology, including Ask and Framing Detection, Named Entity Recognition, Dialogue Engineering, and Stylometry. Panacea processes modern message formats through a plug-in architecture to accommodate innovative approaches for message analysis, knowledge representation and dialogue generation. The novelty of the Panacea system is that uses NLP for cyber defense and engages the attacker using bots to elicit evidence to attribute to the attacker and to waste the attacker's time and resources.
Large-scale Gastric Cancer Screening and Localization Using Multi-task Deep Neural Network
Oct 12, 2019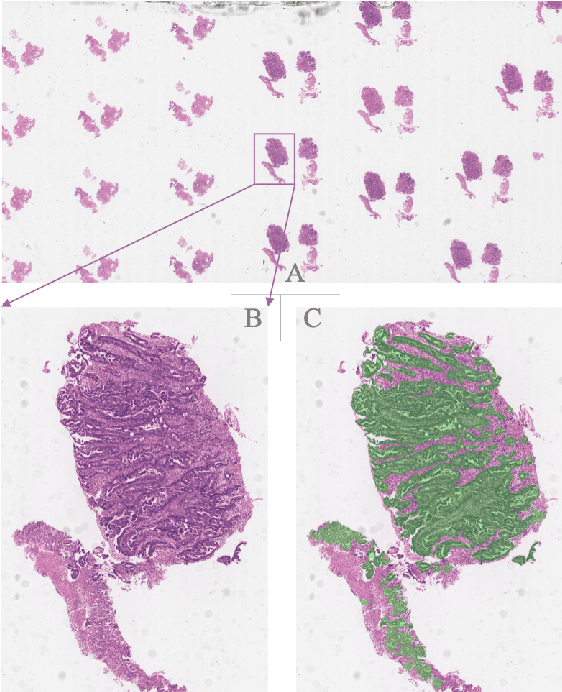
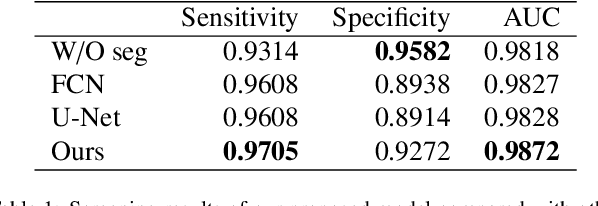
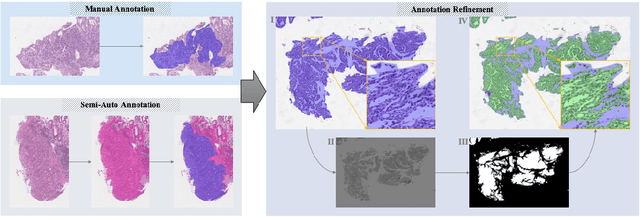
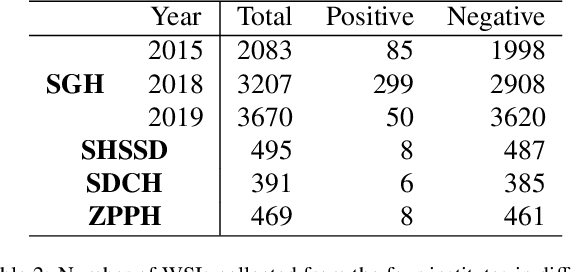
Gastric cancer is one of the most common cancers, which ranks third among the leading causes of cancer death. Biopsy of gastric mucosal is a standard procedure in gastric cancer screening test. However, manual pathological inspection is labor-intensive and time-consuming. Besides, it is challenging for an automated algorithm to locate the small lesion regions in the gigapixel whole-slide image and make the decision correctly. To tackle these issues, we collected large-scale whole-slide image dataset with detailed lesion region annotation and designed a whole-slide image analyzing framework consisting of 3 networks which could not only determine the screen result but also present the suspicious areas to the pathologist for reference. Experiments demonstrated that our proposed framework achieves sensitivity of 97.05% and specificity of 92.72% in screening task and Dice coefficient of 0.8331 in segmentation task. Furthermore, we tested our best model in real-world scenario on 10, 316 whole-slide images collected from 4 medical centers.
Signet Ring Cell Detection With a Semi-supervised Learning Framework
Jul 09, 2019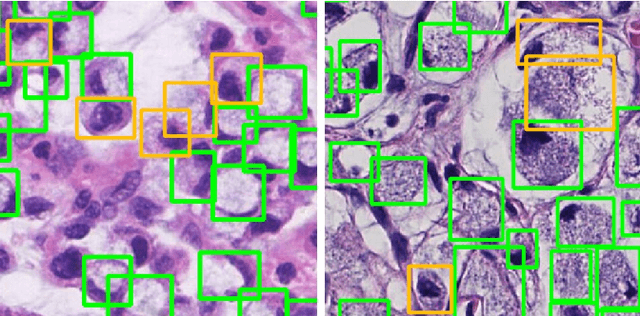
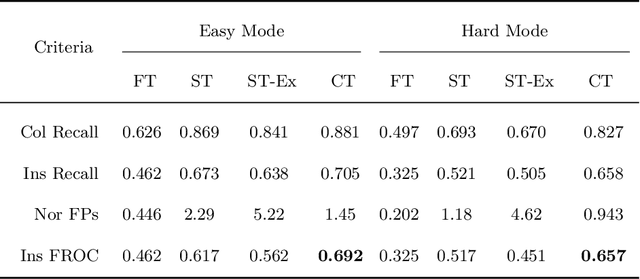
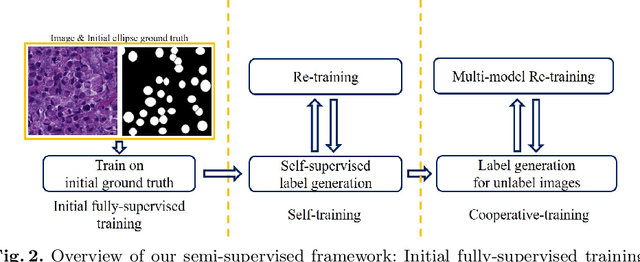
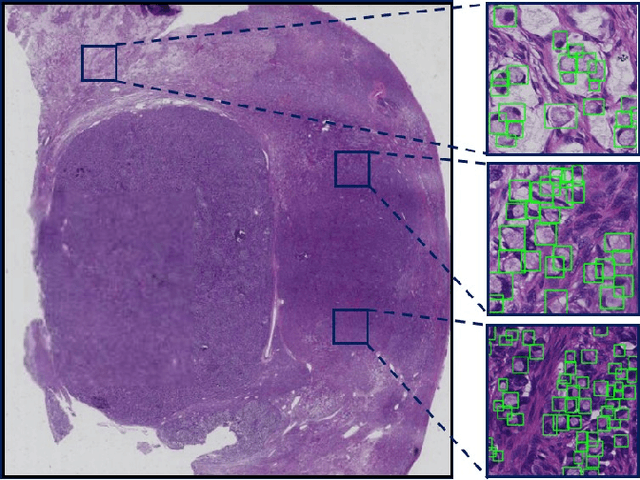
Signet ring cell carcinoma is a type of rare adenocarcinoma with poor prognosis. Early detection leads to huge improvement of patients' survival rate. However, pathologists can only visually detect signet ring cells under the microscope. This procedure is not only laborious but also prone to omission. An automatic and accurate signet ring cell detection solution is thus important but has not been investigated before. In this paper, we take the first step to present a semi-supervised learning framework for the signet ring cell detection problem. Self-training is proposed to deal with the challenge of incomplete annotations, and cooperative-training is adapted to explore the unlabeled regions. Combining the two techniques, our semi-supervised learning framework can make better use of both labeled and unlabeled data. Experiments on large real clinical data demonstrate the effectiveness of our design. Our framework achieves accurate signet ring cell detection and can be readily applied in the clinical trails. The dataset will be released soon to facilitate the development of the area.