 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRelating Word Embedding Gender Biases to Gender Gaps: A Cross-Cultural Analysis
Jan 23, 2026Modern models for common NLP tasks often employ machine learning techniques and train on journalistic, social media, or other culturally-derived text. These have recently been scrutinized for racial and gender biases, rooting from inherent bias in their training text. These biases are often sub-optimal and recent work poses methods to rectify them; however, these biases may shed light on actual racial or gender gaps in the culture(s) that produced the training text, thereby helping us understand cultural context through big data. This paper presents an approach for quantifying gender bias in word embeddings, and then using them to characterize statistical gender gaps in education, politics, economics, and health. We validate these metrics on 2018 Twitter data spanning 51 U.S. regions and 99 countries. We correlate state and country word embedding biases with 18 international and 5 U.S.-based statistical gender gaps, characterizing regularities and predictive strength.
* 7 pages, 5 figures. Presented at the First Workshop on Gender Bias in Natural Language Processing (GeBNLP 2019)
Bottom-Up and Top-Down Analysis of Values, Agendas, and Observations in Corpora and LLMs
Nov 06, 2024Large language models (LLMs) generate diverse, situated, persuasive texts from a plurality of potential perspectives, influenced heavily by their prompts and training data. As part of LLM adoption, we seek to characterize - and ideally, manage - the socio-cultural values that they express, for reasons of safety, accuracy, inclusion, and cultural fidelity. We present a validated approach to automatically (1) extracting heterogeneous latent value propositions from texts, (2) assessing resonance and conflict of values with texts, and (3) combining these operations to characterize the pluralistic value alignment of human-sourced and LLM-sourced textual data.
Provenance-Based Assessment of Plans in Context
Nov 03, 2020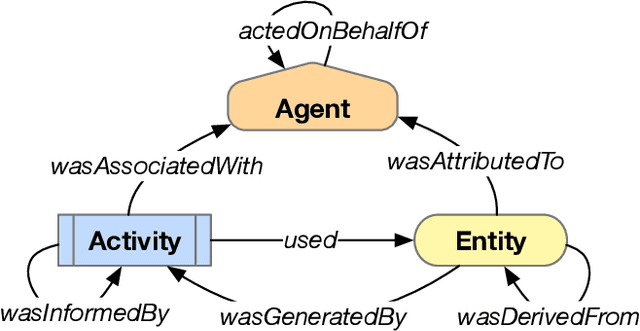
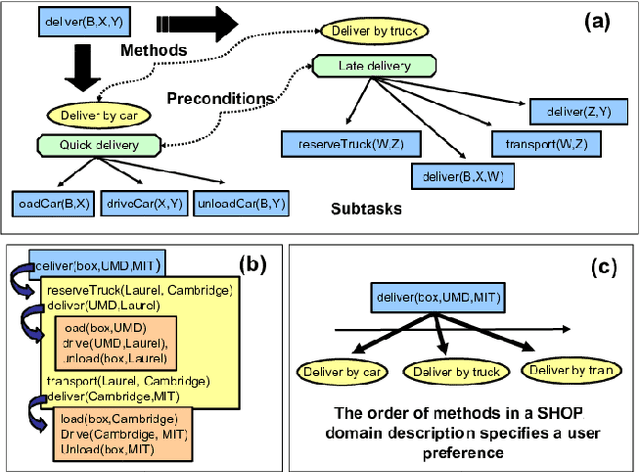
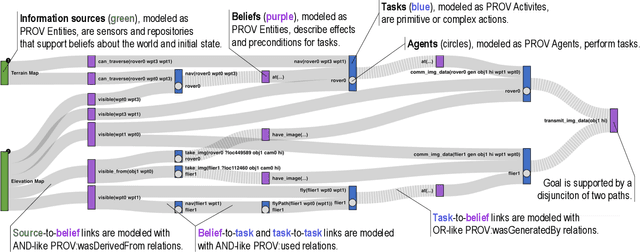
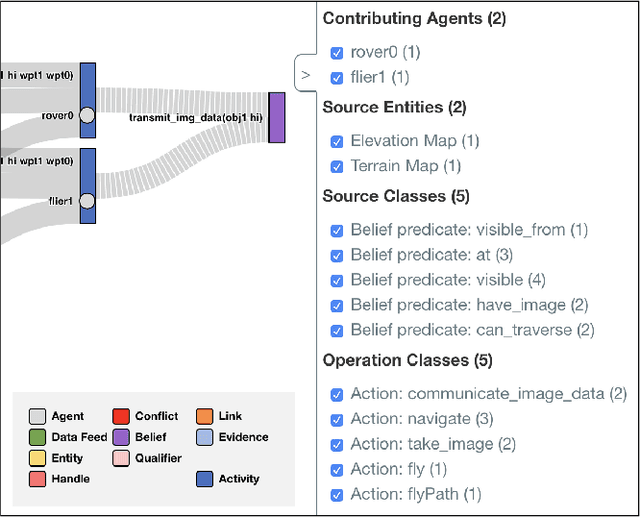
Many real-world planning domains involve diverse information sources, external entities, and variable-reliability agents, all of which may impact the confidence, risk, and sensitivity of plans. Humans reviewing a plan may lack context about these factors; however, this information is available during the domain generation, which means it can also be interwoven into the planner and its resulting plans. This paper presents a provenance-based approach to explaining automated plans. Our approach (1) extends the SHOP3 HTN planner to generate dependency information, (2) transforms the dependency information into an established PROV-O representation, and (3) uses graph propagation and TMS-inspired algorithms to support dynamic and counter-factual assessment of information flow, confidence, and support. We qualified our approach's explanatory scope with respect to explanation targets from the automated planning literature and the information analysis literature, and we demonstrate its ability to assess a plan's pertinence, sensitivity, risk, assumption support, diversity, and relative confidence.
* 9 pages, 7 figures, including in Proceedings of the 2020 ICAPS Workshop on Explainable AI Planning (XAIP)