 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBottom-Up and Top-Down Analysis of Values, Agendas, and Observations in Corpora and LLMs
Nov 06, 2024Large language models (LLMs) generate diverse, situated, persuasive texts from a plurality of potential perspectives, influenced heavily by their prompts and training data. As part of LLM adoption, we seek to characterize - and ideally, manage - the socio-cultural values that they express, for reasons of safety, accuracy, inclusion, and cultural fidelity. We present a validated approach to automatically (1) extracting heterogeneous latent value propositions from texts, (2) assessing resonance and conflict of values with texts, and (3) combining these operations to characterize the pluralistic value alignment of human-sourced and LLM-sourced textual data.
A Symbolic Representation of Human Posture for Interpretable Learning and Reasoning
Oct 17, 2022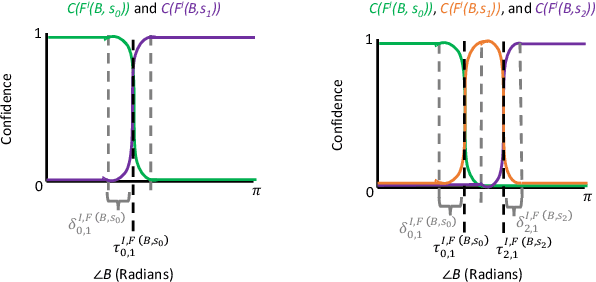
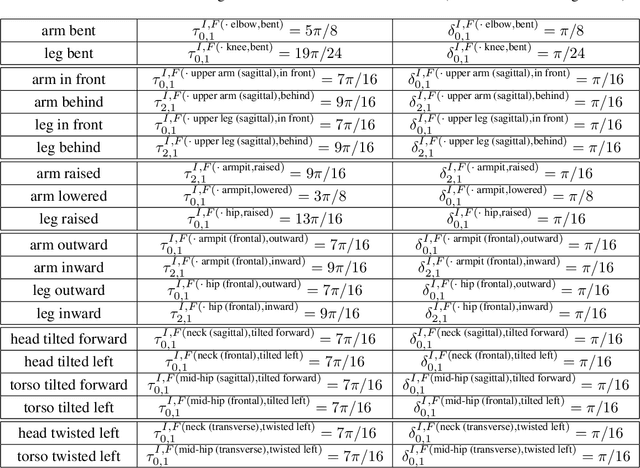
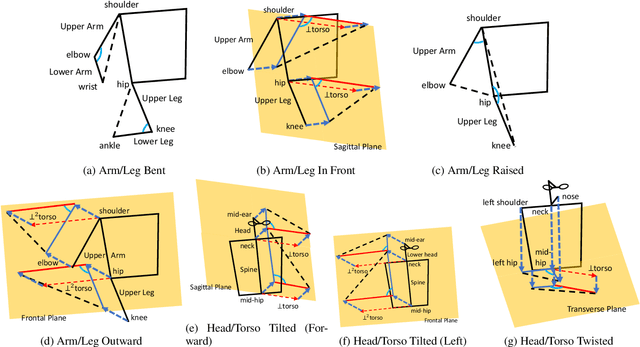

Robots that interact with humans in a physical space or application need to think about the person's posture, which typically comes from visual sensors like cameras and infra-red. Artificial intelligence and machine learning algorithms use information from these sensors either directly or after some level of symbolic abstraction, and the latter usually partitions the range of observed values to discretize the continuous signal data. Although these representations have been effective in a variety of algorithms with respect to accuracy and task completion, the underlying models are rarely interpretable, which also makes their outputs more difficult to explain to people who request them. Instead of focusing on the possible sensor values that are familiar to a machine, we introduce a qualitative spatial reasoning approach that describes the human posture in terms that are more familiar to people. This paper explores the derivation of our symbolic representation at two levels of detail and its preliminary use as features for interpretable activity recognition.