 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Binary Moral Judgment: Modeling Ethical Pluralism in AI
May 27, 2026Critical decision-making in socially consequential spaces is increasingly involving AI systems at varying capacities. Yet, despite the ubiquity of autonomous systems, most approaches to handling autonomous moral decision-making resort to scalar or binary judgments. These methods are insufficient for acceptable moral reasoning, as they provide little explanation, leaving out imperative contextual and theoretical information that must be included to support accountability. For this, we propose a framework to model moral reasoning as a distribution over normative ethical theories or ethical pluralism. We introduce a normative ethics simplex that integrates these theories. A benchmark of 450 cases across 15 fine-grained subtheories was also prepared for the purposes of stacked ensemble learning. These cases describe ethical dilemmas in natural language and have associated extracted contextual features. The implementation of the simplex was achieved via a two-stream normative-semantic architecture. This is followed by the fusion of normative information and a sequential, stacking ensemble to learn the best fit of the three broad theories: consequentialism, virtue ethics, and deontology, and the 15 subcategories. Our experiments demonstrate that the integration of contextual and normative priors with the semantic embeddings significantly improves the performance of the classification, displaying an accuracy of 88.89%. We conducted ablation studies to show that structured ethical representations contribute beyond analogical reasoning, and the chosen stacking architecture gives the best results due to the gradual learning of granularity. Ethical pluralism is also analyzed through entropy, confidence, and visualization. Thus, modeling ethical pluralism as a probabilistic normative distribution supports human-like moral reasoning, ethical disagreement analysis, and future alignment in AI systems.
COREKG: Coreset-Guided Personalized Summarization of Knowledge Graphs
May 14, 2026Knowledge Graphs (KGs) are extensively used across different domains and in several applications. Often, these KGs are very large in size. Such KGs become unwieldy for tasks such as question answering and visualization. Summarization of KGs offers a viable alternative in such cases. Furthermore, personalized KG summarization is crucial in the current data-driven world as it captures the specific requirements of users based on their query patterns. Since it only maintains relevant information, the personalized summaries of KG are small, resulting in significantly smaller storage requirements and query runtime. In this work, we adapt the coreset theory to create personalized KG summaries. For a given dataset and a user-specific query workload, we present an approach that samples a relevant subset of triples using sensitivity-based importance sampling. We ensure that the subset approximates the characteristics of the full dataset with bounded approximation error. We define sensitivity scores that measure the importance of a triple with respect to a user's query workload, which are then used by our coreset construction algorithm. We explicitly focus on personalized knowledge graph summarization by constructing summaries independently for each user based on their query behaviour. Our evaluation on Freebase, WikiData, and DBpedia shows that COREKG delivers higher query-answering accuracy and structural coverage than the state-of-the-art methods, such as GLIMPSE, PPR, iSummary, PEGASUS and APEX$^2$ while requiring only a tiny fraction of the original graph.
ApplE: An Applied Ethics Ontology with Event Context
Feb 07, 2025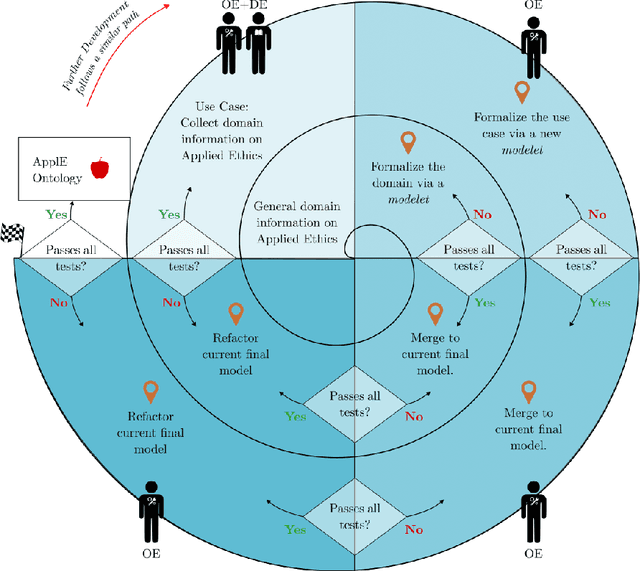



Applied ethics is ubiquitous in most domains, requiring much deliberation due to its philosophical nature. Varying views often lead to conflicting courses of action where ethical dilemmas become challenging to resolve. Although many factors contribute to such a decision, the major driving forces can be discretized and thus simplified to provide an indicative answer. Knowledge representation and reasoning offer a way to explicitly translate abstract ethical concepts into applicable principles within the context of an event. To achieve this, we propose ApplE, an Applied Ethics ontology that captures philosophical theory and event context to holistically describe the morality of an action. The development process adheres to a modified version of the Simplified Agile Methodology for Ontology Development (SAMOD) and utilizes standard design and publication practices. Using ApplE, we model a use case from the bioethics domain that demonstrates our ontology's social and scientific value. Apart from the ontological reasoning and quality checks, ApplE is also evaluated using the three-fold testing process of SAMOD. ApplE follows FAIR principles and aims to be a viable resource for applied ethicists and ontology engineers.
RConE: Rough Cone Embedding for Multi-Hop Logical Query Answering on Multi-Modal Knowledge Graphs
Aug 21, 2024



Multi-hop query answering over a Knowledge Graph (KG) involves traversing one or more hops from the start node to answer a query. Path-based and logic-based methods are state-of-the-art for multi-hop question answering. The former is used in link prediction tasks. The latter is for answering complex logical queries. The logical multi-hop querying technique embeds the KG and queries in the same embedding space. The existing work incorporates First Order Logic (FOL) operators, such as conjunction ($\wedge$), disjunction ($\vee$), and negation ($\neg$), in queries. Though current models have most of the building blocks to execute the FOL queries, they cannot use the dense information of multi-modal entities in the case of Multi-Modal Knowledge Graphs (MMKGs). We propose RConE, an embedding method to capture the multi-modal information needed to answer a query. The model first shortlists candidate (multi-modal) entities containing the answer. It then finds the solution (sub-entities) within those entities. Several existing works tackle path-based question-answering in MMKGs. However, to our knowledge, we are the first to introduce logical constructs in querying MMKGs and to answer queries that involve sub-entities of multi-modal entities as the answer. Extensive evaluation of four publicly available MMKGs indicates that RConE outperforms the current state-of-the-art.
Knowledge-Driven Cross-Document Relation Extraction
May 22, 2024Relation extraction (RE) is a well-known NLP application often treated as a sentence- or document-level task. However, a handful of recent efforts explore it across documents or in the cross-document setting (CrossDocRE). This is distinct from the single document case because different documents often focus on disparate themes, while text within a document tends to have a single goal. Linking findings from disparate documents to identify new relationships is at the core of the popular literature-based knowledge discovery paradigm in biomedicine and other domains. Current CrossDocRE efforts do not consider domain knowledge, which are often assumed to be known to the reader when documents are authored. Here, we propose a novel approach, KXDocRE, that embed domain knowledge of entities with input text for cross-document RE. Our proposed framework has three main benefits over baselines: 1) it incorporates domain knowledge of entities along with documents' text; 2) it offers interpretability by producing explanatory text for predicted relations between entities 3) it improves performance over the prior methods.
Revisiting Document-Level Relation Extraction with Context-Guided Link Prediction
Jan 22, 2024Document-level relation extraction (DocRE) poses the challenge of identifying relationships between entities within a document as opposed to the traditional RE setting where a single sentence is input. Existing approaches rely on logical reasoning or contextual cues from entities. This paper reframes document-level RE as link prediction over a knowledge graph with distinct benefits: 1) Our approach combines entity context with document-derived logical reasoning, enhancing link prediction quality. 2) Predicted links between entities offer interpretability, elucidating employed reasoning. We evaluate our approach on three benchmark datasets: DocRED, ReDocRED, and DWIE. The results indicate that our proposed method outperforms the state-of-the-art models and suggests that incorporating context-based link prediction techniques can enhance the performance of document-level relation extraction models.
ReOnto: A Neuro-Symbolic Approach for Biomedical Relation Extraction
Sep 04, 2023Relation Extraction (RE) is the task of extracting semantic relationships between entities in a sentence and aligning them to relations defined in a vocabulary, which is generally in the form of a Knowledge Graph (KG) or an ontology. Various approaches have been proposed so far to address this task. However, applying these techniques to biomedical text often yields unsatisfactory results because it is hard to infer relations directly from sentences due to the nature of the biomedical relations. To address these issues, we present a novel technique called ReOnto, that makes use of neuro symbolic knowledge for the RE task. ReOnto employs a graph neural network to acquire the sentence representation and leverages publicly accessible ontologies as prior knowledge to identify the sentential relation between two entities. The approach involves extracting the relation path between the two entities from the ontology. We evaluate the effect of using symbolic knowledge from ontologies with graph neural networks. Experimental results on two public biomedical datasets, BioRel and ADE, show that our method outperforms all the baselines (approximately by 3\%).
Neuro-Symbolic RDF and Description Logic Reasoners: The State-Of-The-Art and Challenges
Aug 09, 2023

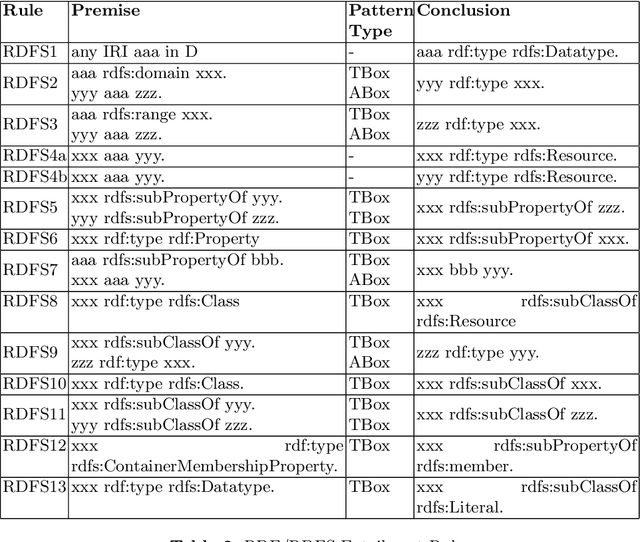

Ontologies are used in various domains, with RDF and OWL being prominent standards for ontology development. RDF is favored for its simplicity and flexibility, while OWL enables detailed domain knowledge representation. However, as ontologies grow larger and more expressive, reasoning complexity increases, and traditional reasoners struggle to perform efficiently. Despite optimization efforts, scalability remains an issue. Additionally, advancements in automated knowledge base construction have created large and expressive ontologies that are often noisy and inconsistent, posing further challenges for conventional reasoners. To address these challenges, researchers have explored neuro-symbolic approaches that combine neural networks' learning capabilities with symbolic systems' reasoning abilities. In this chapter,we provide an overview of the existing literature in the field of neuro-symbolic deductive reasoning supported by RDF(S), the description logics EL and ALC, and OWL 2 RL, discussing the techniques employed, the tasks they address, and other relevant efforts in this area.
A Planning Ontology to Represent and Exploit Planning Knowledge for Performance Efficiency
Jul 25, 2023Ontologies are known for their ability to organize rich metadata, support the identification of novel insights via semantic queries, and promote reuse. In this paper, we consider the problem of automated planning, where the objective is to find a sequence of actions that will move an agent from an initial state of the world to a desired goal state. We hypothesize that given a large number of available planners and diverse planning domains; they carry essential information that can be leveraged to identify suitable planners and improve their performance for a domain. We use data on planning domains and planners from the International Planning Competition (IPC) to construct a planning ontology and demonstrate via experiments in two use cases that the ontology can lead to the selection of promising planners and improving their performance using macros - a form of action ordering constraints extracted from planning ontology. We also make the planning ontology and associated resources available to the community to promote further research.
OntoSeer -- A Recommendation System to Improve the Quality of Ontologies
Feb 04, 2022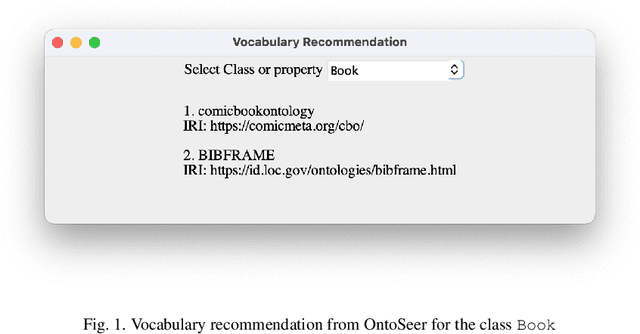

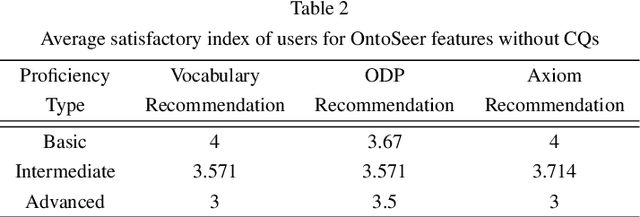
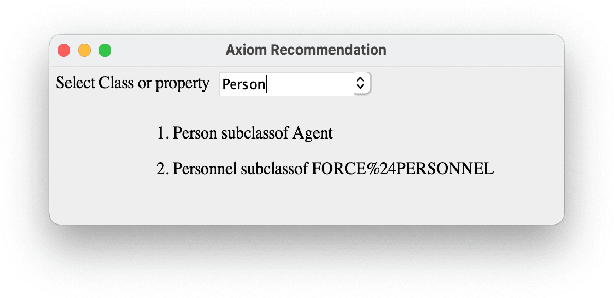
Building an ontology is not only a time-consuming process, but it is also confusing, especially for beginners and the inexperienced. Although ontology developers can take the help of domain experts in building an ontology, they are not readily available in several cases for a variety of reasons. Ontology developers have to grapple with several questions related to the choice of classes, properties, and the axioms that should be included. Apart from this, there are aspects such as modularity and reusability that should be taken care of. From among the thousands of publicly available ontologies and vocabularies in repositories such as Linked Open Vocabularies (LOV) and BioPortal, it is hard to know the terms (classes and properties) that can be reused in the development of an ontology. A similar problem exists in implementing the right set of ontology design patterns (ODPs) from among the several available. Generally, ontology developers make use of their experience in handling these issues, and the inexperienced ones have a hard time. In order to bridge this gap, we propose a tool named OntoSeer, that monitors the ontology development process and provides suggestions in real-time to improve the quality of the ontology under development. It can provide suggestions on the naming conventions to follow, vocabulary to reuse, ODPs to implement, and axioms to be added to the ontology. OntoSeer has been implemented as a Prot\'eg\'e plug-in.