 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Machine Mental Imagery for Representing Common Ground in Situated Dialogue
Apr 22, 2026Situated dialogue requires speakers to maintain a reliable representation of shared context rather than reasoning only over isolated utterances. Current conversational agents often struggle with this requirement, especially when the common ground must be preserved beyond the immediate context window. In such settings, fine-grained distinctions are frequently compressed into purely textual representations, leading to a critical failure mode we call \emph{representational blur}, in which similar but distinct entities collapse into interchangeable descriptions. This semantic flattening creates an illusion of grounding, where agents appear locally coherent but fail to track shared context persistently over time. Inspired by the role of mental imagery in human reasoning, and based on the increased availability of multimodal models, we explore whether conversational agents can be given an analogous ability to construct some depictive intermediate representations during dialogue to address these limitations. Thus, we introduce an active visual scaffolding framework that incrementally converts dialogue state into a persistent visual history that can later be retrieved for grounded response generation. Evaluation on the IndiRef benchmark shows that incremental externalization itself improves over full-dialog reasoning, while visual scaffolding provides additional gains by reducing representational blur and enforcing concrete scene commitments. At the same time, textual representations remain advantageous for non-depictable information, and a hybrid multimodal setting yields the best overall performance. Together, these findings suggest that conversational agents benefit from an explicitly multimodal representation of common ground that integrates depictive and propositional information.
SpeechMapper: Speech-to-text Embedding Projector for LLMs
Jan 28, 2026Current speech LLMs bridge speech foundation models to LLMs using projection layers, training all of these components on speech instruction data. This strategy is computationally intensive and susceptible to task and prompt overfitting. We present SpeechMapper, a cost-efficient speech-to-LLM-embedding training approach that mitigates overfitting, enabling more robust and generalizable models. Our model is first pretrained without the LLM on inexpensive hardware, and then efficiently attached to the target LLM via a brief 1K-step instruction tuning (IT) stage. Through experiments on speech translation and spoken question answering, we demonstrate the versatility of SpeechMapper's pretrained block, presenting results for both task-agnostic IT, an ASR-based adaptation strategy that does not train in the target task, and task-specific IT. In task-agnostic settings, Speechmapper rivals the best instruction-following speech LLM from IWSLT25, despite never being trained on these tasks, while in task-specific settings, it outperforms this model across many datasets, despite requiring less data and compute. Overall, SpeechMapper offers a practical and scalable approach for efficient, generalizable speech-LLM integration without large-scale IT.
Frame of Reference: Addressing the Challenges of Common Ground Representation in Situational Dialogs
Jan 14, 2026Common ground plays a critical role in situated spoken dialogues, where interlocutors must establish and maintain shared references to entities, events, and relations to sustain coherent interaction. For dialog systems, the ability to correctly ground conversational content in order to refer back to it later is particularly important. Prior studies have demonstrated that LLMs are capable of performing grounding acts such as requesting clarification or producing acknowledgments, yet relatively little work has investigated how common ground can be explicitly represented and stored for later use. Without such mechanisms, it remains unclear whether acknowledgment or clarification behaviors truly reflect a grounded understanding. In this work, we evaluate a model's ability to establish and exploit common ground through relational references to entities within the shared context in a situational dialogue. We test multiple methods for representing common ground in situated dialogues and further propose approaches to improve both the establishment of common ground and its subsequent use in the conversation.
Conversational Grounding: Annotation and Analysis of Grounding Acts and Grounding Units
Mar 25, 2024


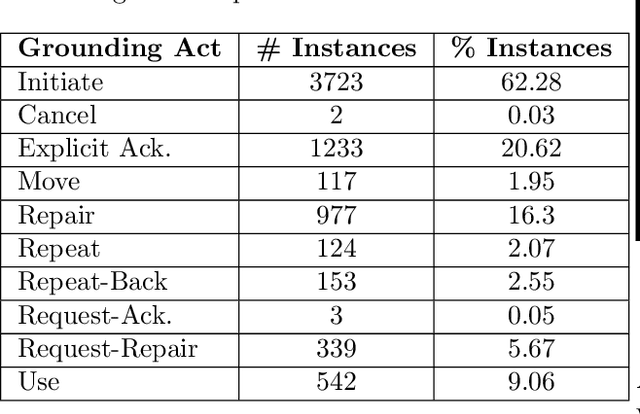
Successful conversations often rest on common understanding, where all parties are on the same page about the information being shared. This process, known as conversational grounding, is crucial for building trustworthy dialog systems that can accurately keep track of and recall the shared information. The proficiencies of an agent in grounding the conveyed information significantly contribute to building a reliable dialog system. Despite recent advancements in dialog systems, there exists a noticeable deficit in their grounding capabilities. Traum provided a framework for conversational grounding introducing Grounding Acts and Grounding Units, but substantial progress, especially in the realm of Large Language Models, remains lacking. To bridge this gap, we present the annotation of two dialog corpora employing Grounding Acts, Grounding Units, and a measure of their degree of grounding. We discuss our key findings during the annotation and also provide a baseline model to test the performance of current Language Models in categorizing the grounding acts of the dialogs. Our work aims to provide a useful resource for further research in making conversations with machines better understood and more reliable in natural day-to-day collaborative dialogs.
Why Settle for Just One? Extending EL++ Ontology Embeddings with Many-to-Many Relationships
Oct 20, 2021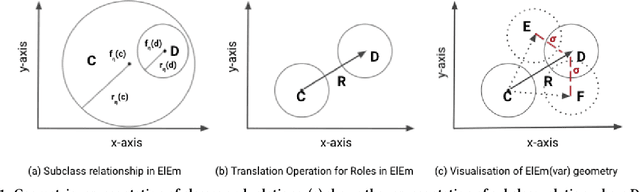
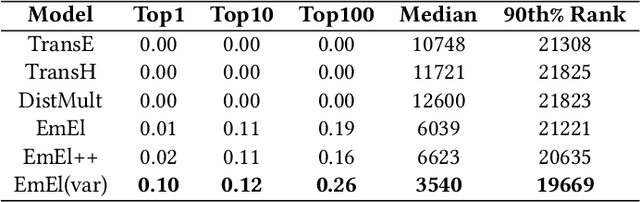
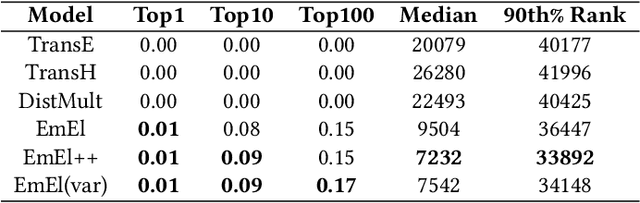
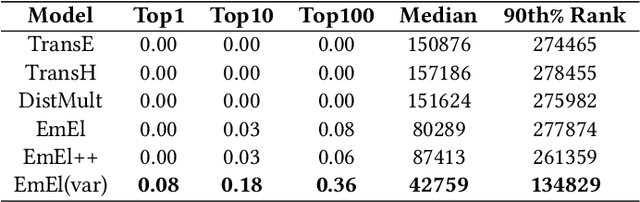
Knowledge Graph (KG) embeddings provide a low-dimensional representation of entities and relations of a Knowledge Graph and are used successfully for various applications such as question answering and search, reasoning, inference, and missing link prediction. However, most of the existing KG embeddings only consider the network structure of the graph and ignore the semantics and the characteristics of the underlying ontology that provides crucial information about relationships between entities in the KG. Recent efforts in this direction involve learning embeddings for a Description Logic (logical underpinning for ontologies) named EL++. However, such methods consider all the relations defined in the ontology to be one-to-one which severely limits their performance and applications. We provide a simple and effective solution to overcome this shortcoming that allows such methods to consider many-to-many relationships while learning embedding representations. Experiments conducted using three different EL++ ontologies show substantial performance improvement over five baselines. Our proposed solution also paves the way for learning embedding representations for even more expressive description logics such as SROIQ.
Simulated Chats for Task-oriented Dialog: Learning to Generate Conversations from Instructions
Oct 20, 2020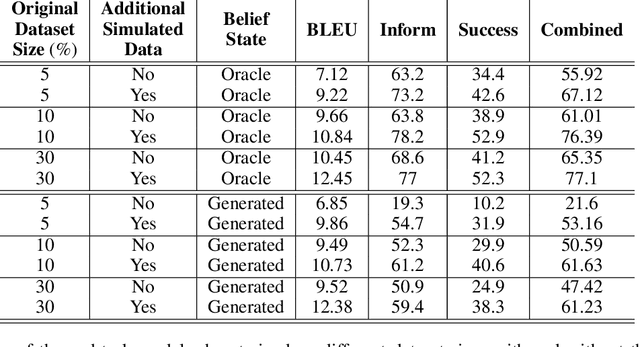
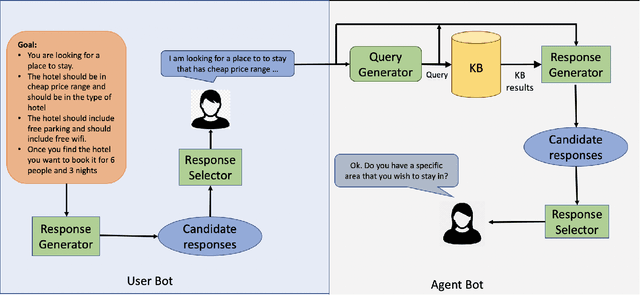
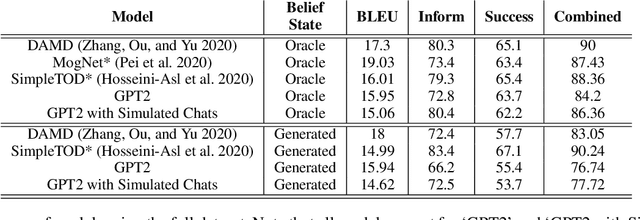

Popular task-oriented dialog data sets such as MultiWOZ (Budzianowski et al. 2018) are created by providing crowd-sourced workers a goal instruction, expressed in natural language, that describes the task to be accomplished. Crowd-sourced workers play the role of a user and an agent to generate dialogs to accomplish tasks involving booking restaurant tables, making train reservations, calling a taxi etc. However, creating large crowd-sourced datasets can be time consuming and expensive. To reduce the cost associated with generating such dialog datasets, recent work has explored methods to automatically create larger datasets from small samples.In this paper, we present a data creation strategy that uses the pre-trained language model, GPT2 (Radford et al. 2018), to simulate the interaction between crowd-sourced workers by creating a user bot and an agent bot. We train the simulators using a smaller percentage of actual crowd-generated conversations and their corresponding goal instructions. We demonstrate that by using the simulated data, we achieve significant improvements in both low-resource setting as well as in over-all task performance. To the best of our knowledge we are the first to present a model for generating entire conversations by simulating the crowd-sourced data collection process