 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimulated Chats for Task-oriented Dialog: Learning to Generate Conversations from Instructions
Paper and Code
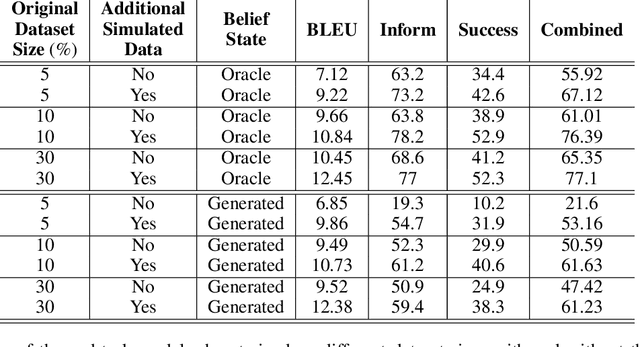
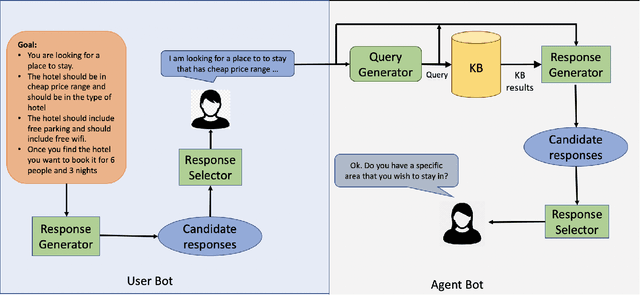
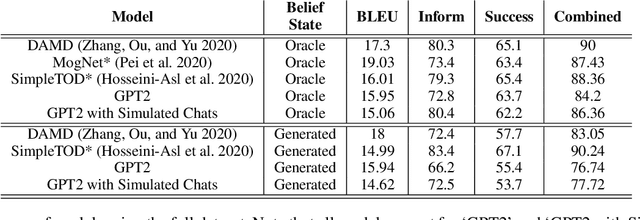

Popular task-oriented dialog data sets such as MultiWOZ (Budzianowski et al. 2018) are created by providing crowd-sourced workers a goal instruction, expressed in natural language, that describes the task to be accomplished. Crowd-sourced workers play the role of a user and an agent to generate dialogs to accomplish tasks involving booking restaurant tables, making train reservations, calling a taxi etc. However, creating large crowd-sourced datasets can be time consuming and expensive. To reduce the cost associated with generating such dialog datasets, recent work has explored methods to automatically create larger datasets from small samples.In this paper, we present a data creation strategy that uses the pre-trained language model, GPT2 (Radford et al. 2018), to simulate the interaction between crowd-sourced workers by creating a user bot and an agent bot. We train the simulators using a smaller percentage of actual crowd-generated conversations and their corresponding goal instructions. We demonstrate that by using the simulated data, we achieve significant improvements in both low-resource setting as well as in over-all task performance. To the best of our knowledge we are the first to present a model for generating entire conversations by simulating the crowd-sourced data collection process