 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePET: A new Dataset for Process Extraction from Natural Language Text
Paper and Code
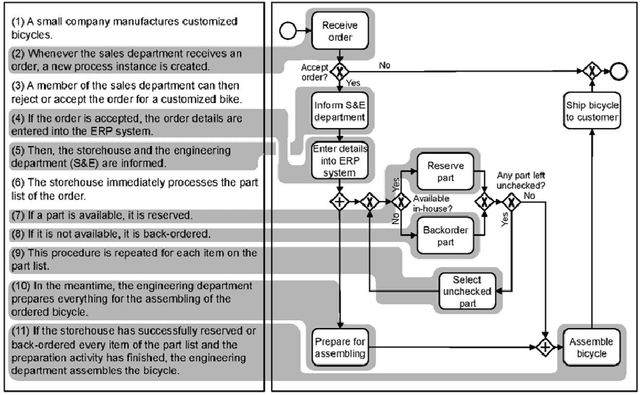
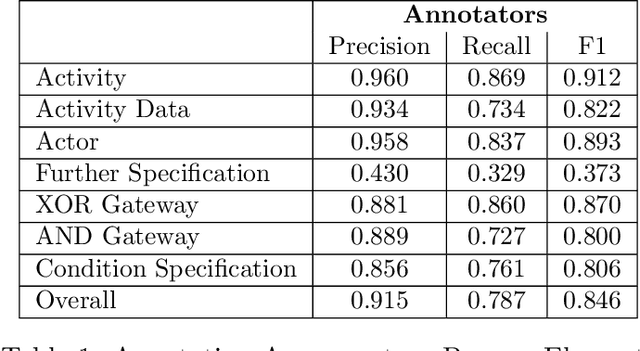
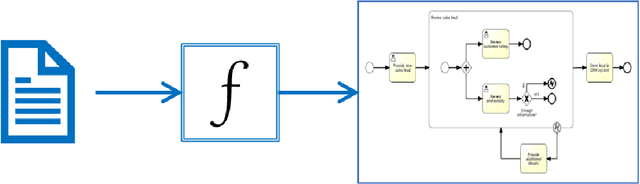

Although there is a long tradition of work in NLP on extracting entities and relations from text, to date there exists little work on the acquisition of business processes from unstructured data such as textual corpora of process descriptions. With this work we aim at filling this gap and establishing the first steps towards bridging data-driven information extraction methodologies from Natural Language Processing and the model-based formalization that is aimed from Business Process Management. For this, we develop the first corpus of business process descriptions annotated with activities, gateways, actors and flow information. We present our new resource, including a detailed overview of the annotation schema and guidelines, as well as a variety of baselines to benchmark the difficulty and challenges of business process extraction from text.