 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging pre-trained language models for conversational information seeking from text
Mar 31, 2022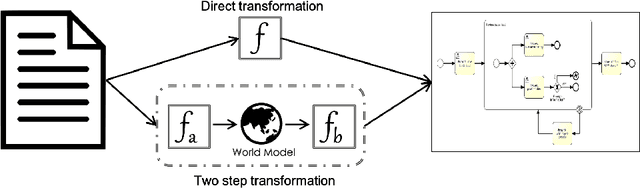
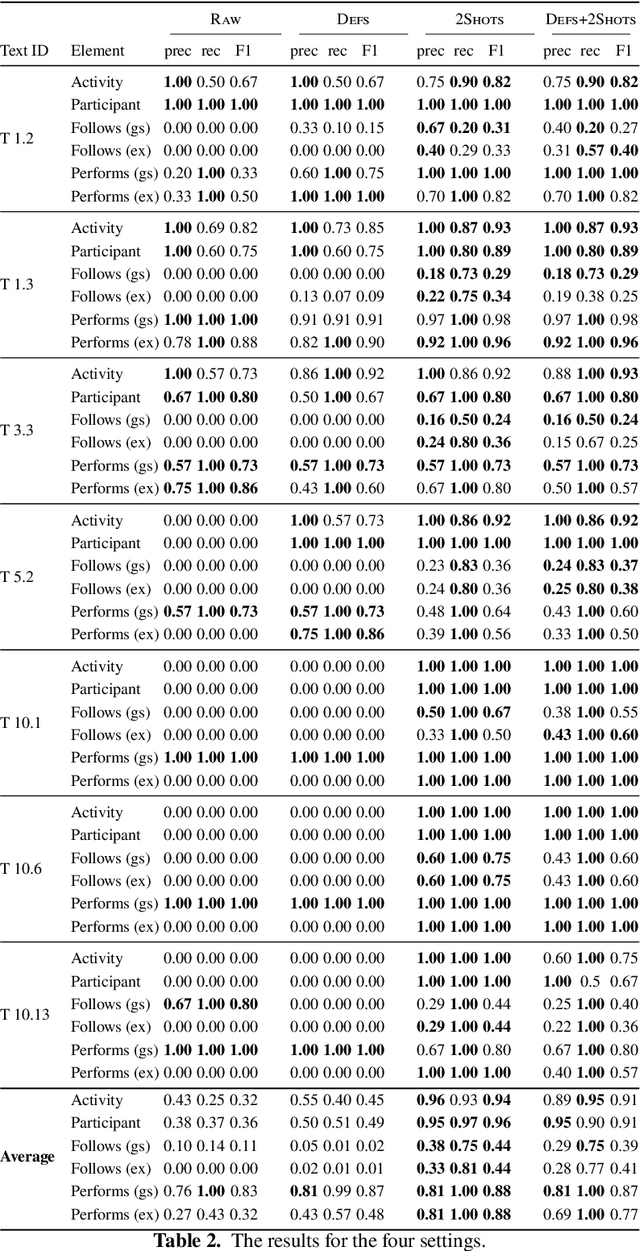
Recent advances in Natural Language Processing, and in particular on the construction of very large pre-trained language representation models, is opening up new perspectives on the construction of conversational information seeking (CIS) systems. In this paper we investigate the usage of in-context learning and pre-trained language representation models to address the problem of information extraction from process description documents, in an incremental question and answering oriented fashion. In particular we investigate the usage of the native GPT-3 (Generative Pre-trained Transformer 3) model, together with two in-context learning customizations that inject conceptual definitions and a limited number of samples in a few shot-learning fashion. The results highlight the potential of the approach and the usefulness of the in-context learning customizations, which can substantially contribute to address the "training data challenge" of deep learning based NLP techniques the BPM field. It also highlight the challenge posed by control flow relations for which further training needs to be devised.
PET: A new Dataset for Process Extraction from Natural Language Text
Mar 09, 2022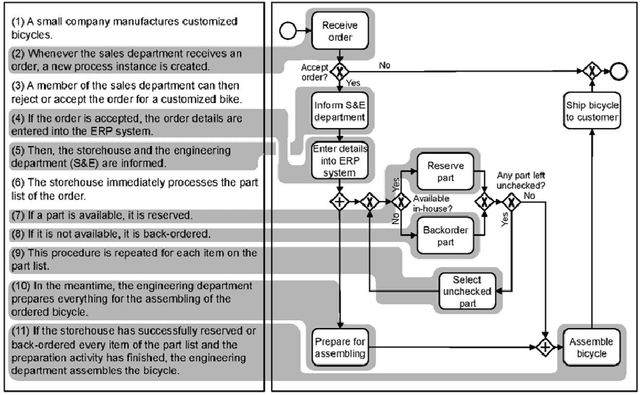
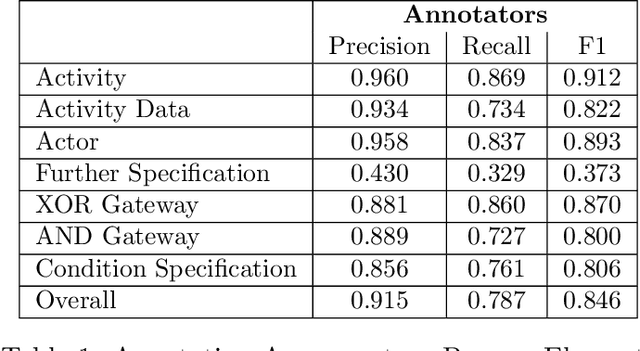

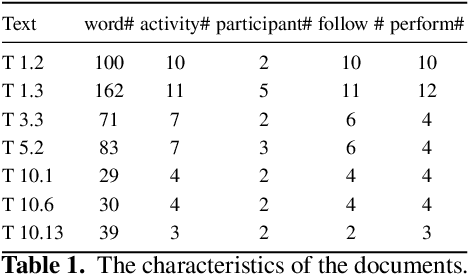
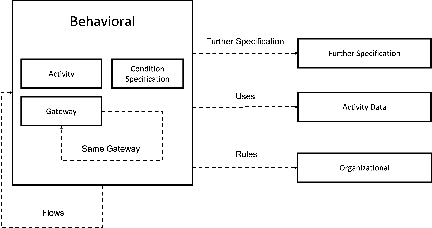
Although there is a long tradition of work in NLP on extracting entities and relations from text, to date there exists little work on the acquisition of business processes from unstructured data such as textual corpora of process descriptions. With this work we aim at filling this gap and establishing the first steps towards bridging data-driven information extraction methodologies from Natural Language Processing and the model-based formalization that is aimed from Business Process Management. For this, we develop the first corpus of business process descriptions annotated with activities, gateways, actors and flow information. We present our new resource, including a detailed overview of the annotation schema and guidelines, as well as a variety of baselines to benchmark the difficulty and challenges of business process extraction from text.
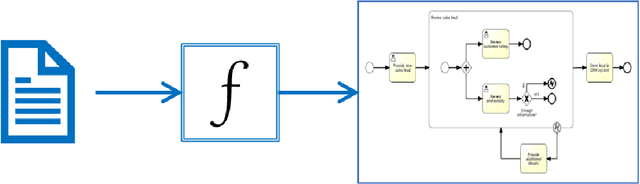
Process Extraction from Text: state of the art and challenges for the future
Oct 07, 2021
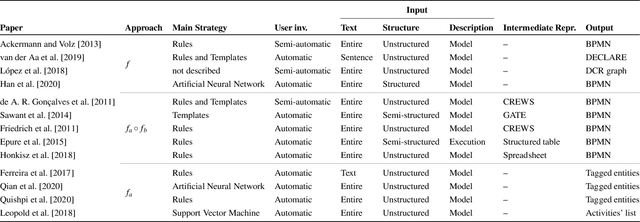
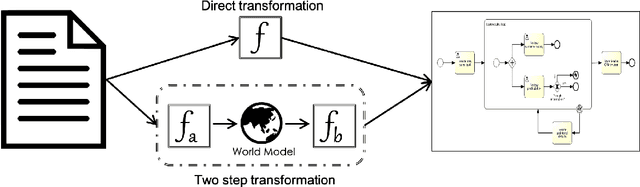
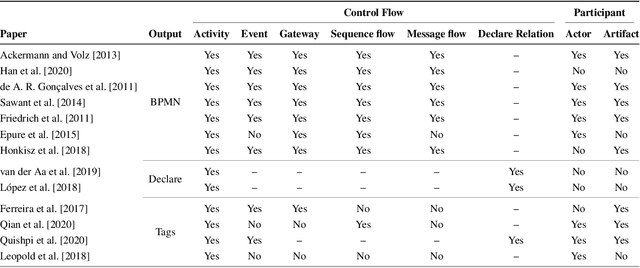
Automatic Process Discovery aims at developing algorithmic methodologies for the extraction and elicitation of process models as described in data. While Process Discovery from event-log data is a well established area, that has already moved from research to concrete adoption in a mature manner, Process Discovery from text is still a research area at an early stage of development, which rarely scales to real world documents. In this paper we analyze, in a comparative manner, reference state-of-the-art literature, especially for what concerns the techniques used, the process elements extracted and the evaluations performed. As a result of the analysis we discuss important limitations that hamper the exploitation of recent Natural Language Processing techniques in this field and we discuss fundamental limitations and challenges for the future concerning the datasets, the techniques, the experimental evaluations, and the pipelines currently adopted and to be developed in the future.