 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Counterfactual Explanations Under Temporal Constraints
Mar 03, 2025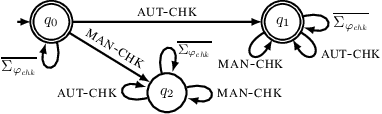


Counterfactual explanations are one of the prominent eXplainable Artificial Intelligence (XAI) techniques, and suggest changes to input data that could alter predictions, leading to more favourable outcomes. Existing counterfactual methods do not readily apply to temporal domains, such as that of process mining, where data take the form of traces of activities that must obey to temporal background knowledge expressing which dynamics are possible and which not. Specifically, counterfactuals generated off-the-shelf may violate the background knowledge, leading to inconsistent explanations. This work tackles this challenge by introducing a novel approach for generating temporally constrained counterfactuals, guaranteed to comply by design with background knowledge expressed in Linear Temporal Logic on process traces (LTLp). We do so by infusing automata-theoretic techniques for LTLp inside a genetic algorithm for counterfactual generation. The empirical evaluation shows that the generated counterfactuals are temporally meaningful and more interpretable for applications involving temporal dependencies.
Generating the Traces You Need: A Conditional Generative Model for Process Mining Data
Nov 04, 2024In recent years, trace generation has emerged as a significant challenge within the Process Mining community. Deep Learning (DL) models have demonstrated accuracy in reproducing the features of the selected processes. However, current DL generative models are limited in their ability to adapt the learned distributions to generate data samples based on specific conditions or attributes. This limitation is particularly significant because the ability to control the type of generated data can be beneficial in various contexts, enabling a focus on specific behaviours, exploration of infrequent patterns, or simulation of alternative 'what-if' scenarios. In this work, we address this challenge by introducing a conditional model for process data generation based on a conditional variational autoencoder (CVAE). Conditional models offer control over the generation process by tuning input conditional variables, enabling more targeted and controlled data generation. Unlike other domains, CVAE for process mining faces specific challenges due to the multiperspective nature of the data and the need to adhere to control-flow rules while ensuring data variability. Specifically, we focus on generating process executions conditioned on control flow and temporal features of the trace, allowing us to produce traces for specific, identified sub-processes. The generated traces are then evaluated using common metrics for generative model assessment, along with additional metrics to evaluate the quality of the conditional generation
Guiding the generation of counterfactual explanations through temporal background knowledge for Predictive Process Monitoring
Mar 18, 2024Counterfactual explanations suggest what should be different in the input instance to change the outcome of an AI system. When dealing with counterfactual explanations in the field of Predictive Process Monitoring, however, control flow relationships among events have to be carefully considered. A counterfactual, indeed, should not violate control flow relationships among activities (temporal background knowledege). Within the field of Explainability in Predictive Process Monitoring, there have been a series of works regarding counterfactual explanations for outcome-based predictions. However, none of them consider the inclusion of temporal background knowledge when generating these counterfactuals. In this work, we adapt state-of-the-art techniques for counterfactual generation in the domain of XAI that are based on genetic algorithms to consider a series of temporal constraints at runtime. We assume that this temporal background knowledge is given, and we adapt the fitness function, as well as the crossover and mutation operators, to maintain the satisfaction of the constraints. The proposed methods are evaluated with respect to state-of-the-art genetic algorithms for counterfactual generation and the results are presented. We showcase that the inclusion of temporal background knowledge allows the generation of counterfactuals more conformant to the temporal background knowledge, without however losing in terms of the counterfactual traditional quality metrics.
Explain, Adapt and Retrain: How to improve the accuracy of a PPM classifier through different explanation styles
Mar 27, 2023


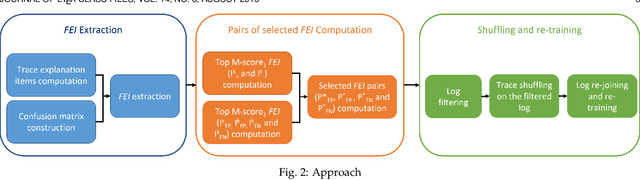
Recent papers have introduced a novel approach to explain why a Predictive Process Monitoring (PPM) model for outcome-oriented predictions provides wrong predictions. Moreover, they have shown how to exploit the explanations, obtained using state-of-the art post-hoc explainers, to identify the most common features that induce a predictor to make mistakes in a semi-automated way, and, in turn, to reduce the impact of those features and increase the accuracy of the predictive model. This work starts from the assumption that frequent control flow patterns in event logs may represent important features that characterize, and therefore explain, a certain prediction. Therefore, in this paper, we (i) employ a novel encoding able to leverage DECLARE constraints in Predictive Process Monitoring and compare the effectiveness of this encoding with Predictive Process Monitoring state-of-the art encodings, in particular for the task of outcome-oriented predictions; (ii) introduce a completely automated pipeline for the identification of the most common features inducing a predictor to make mistakes; and (iii) show the effectiveness of the proposed pipeline in increasing the accuracy of the predictive model by validating it on different real-life datasets.
Recommending the optimal policy by learning to act from temporal data
Mar 16, 2023



Prescriptive Process Monitoring is a prominent problem in Process Mining, which consists in identifying a set of actions to be recommended with the goal of optimising a target measure of interest or Key Performance Indicator (KPI). One challenge that makes this problem difficult is the need to provide Prescriptive Process Monitoring techniques only based on temporally annotated (process) execution data, stored in, so-called execution logs, due to the lack of well crafted and human validated explicit models. In this paper we aim at proposing an AI based approach that learns, by means of Reinforcement Learning (RL), an optimal policy (almost) only from the observation of past executions and recommends the best activities to carry on for optimizing a KPI of interest. This is achieved first by learning a Markov Decision Process for the specific KPIs from data, and then by using RL training to learn the optimal policy. The approach is validated on real and synthetic datasets and compared with off-policy Deep RL approaches. The ability of our approach to compare with, and often overcome, Deep RL approaches provides a contribution towards the exploitation of white box RL techniques in scenarios where only temporal execution data are available.
Nirdizati: an Advanced Predictive Process Monitoring Toolkit
Oct 18, 2022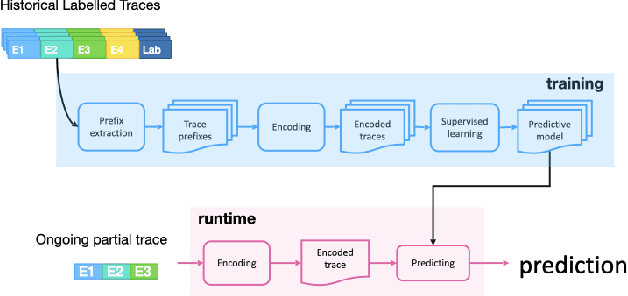

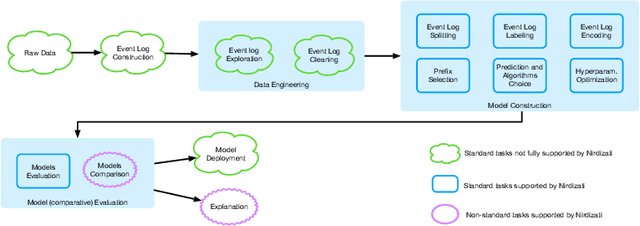
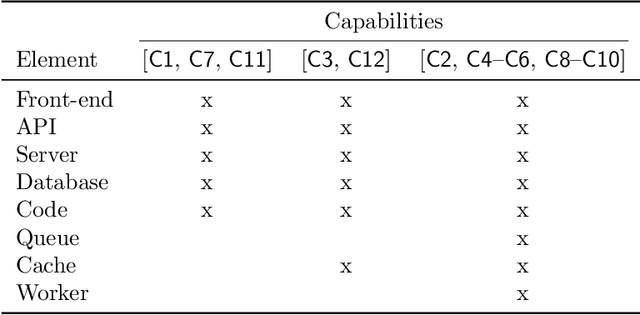
Predictive Process Monitoring is a field of Process Mining that aims at predicting how an ongoing execution of a business process will develop in the future using past process executions recorded in event logs. The recent stream of publications in this field shows the need for tools able to support researchers and users in analyzing, comparing and selecting the techniques that are the most suitable for them. Nirdizati is a dedicated tool for supporting users in building, comparing, analyzing, and explaining predictive models that can then be used to perform predictions on the future of an ongoing case. By providing a rich set of different state-of-the-art approaches, Nirdizati offers BPM researchers and practitioners a useful and flexible instrument for investigating and comparing Predictive Process Monitoring techniques. In this paper, we present the current version of Nirdizati, together with its architecture which has been developed to improve its modularity and scalability. The features of Nirdizati enrich its capability to support researchers and practitioners within the entire pipeline for constructing reliable Predictive Process Monitoring models.
Leveraging pre-trained language models for conversational information seeking from text
Mar 31, 2022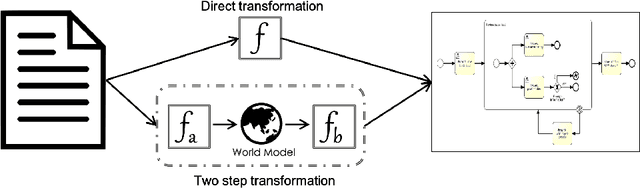
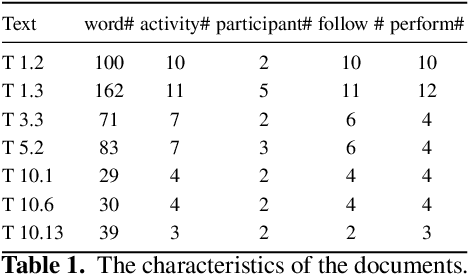
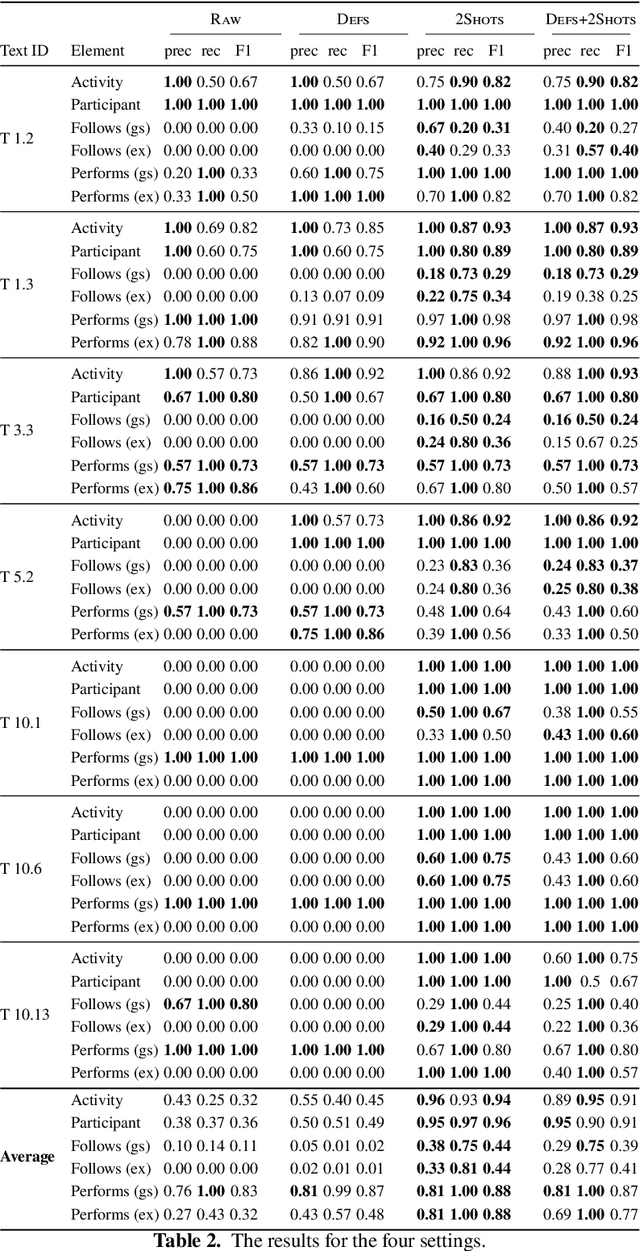
Recent advances in Natural Language Processing, and in particular on the construction of very large pre-trained language representation models, is opening up new perspectives on the construction of conversational information seeking (CIS) systems. In this paper we investigate the usage of in-context learning and pre-trained language representation models to address the problem of information extraction from process description documents, in an incremental question and answering oriented fashion. In particular we investigate the usage of the native GPT-3 (Generative Pre-trained Transformer 3) model, together with two in-context learning customizations that inject conceptual definitions and a limited number of samples in a few shot-learning fashion. The results highlight the potential of the approach and the usefulness of the in-context learning customizations, which can substantially contribute to address the "training data challenge" of deep learning based NLP techniques the BPM field. It also highlight the challenge posed by control flow relations for which further training needs to be devised.
Learning to act: a Reinforcement Learning approach to recommend the best next activities
Mar 29, 2022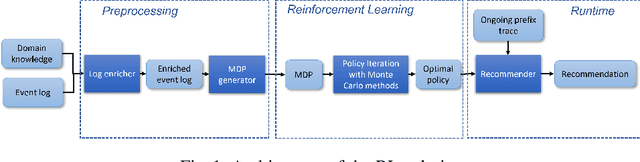

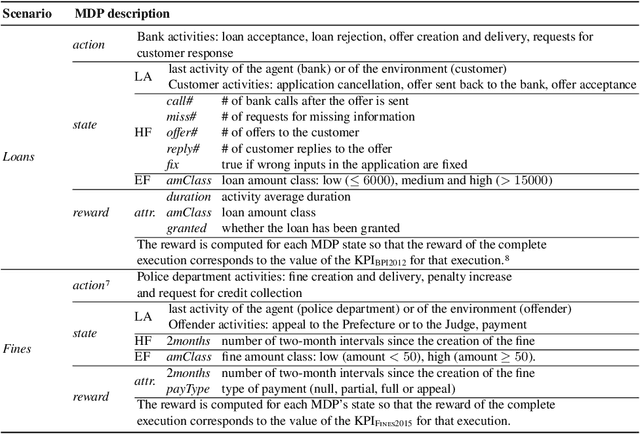
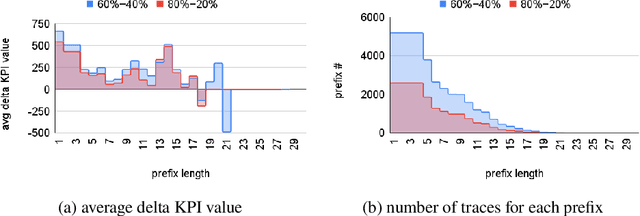
The rise of process data availability has led in the last decade to the development of several data-driven learning approaches. However, most of these approaches limit themselves to use the learned model to predict the future of ongoing process executions. The goal of this paper is moving a step forward and leveraging data with the purpose of learning to act by supporting users with recommendations for the best strategy to follow, in order to optimize a measure of performance. In this paper, we take the (optimization) perspective of one process actor and we recommend the best activities to execute next, in response to what happens in a complex external environment, where there is no control on exogenous factors. To this aim, we investigate an approach that learns, by means of Reinforcement Learning, an optimal policy from the observation of past executions and recommends the best activities to carry on for optimizing a Key Performance Indicator of interest. The potentiality of the approach has been demonstrated on two scenarios taken from real-life data.
PET: A new Dataset for Process Extraction from Natural Language Text
Mar 09, 2022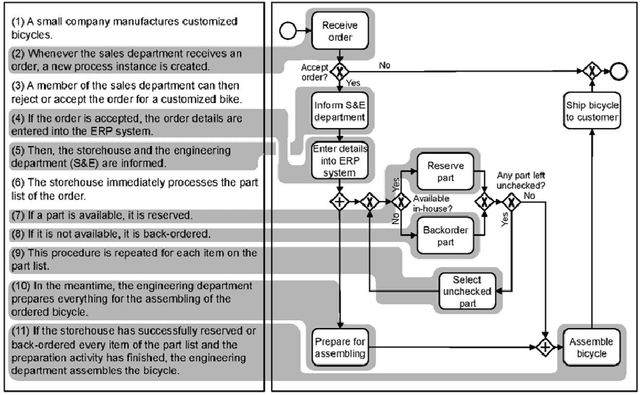
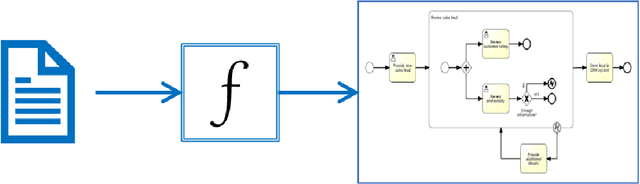

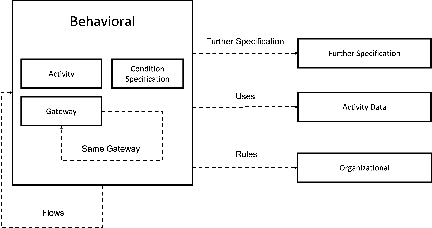
Although there is a long tradition of work in NLP on extracting entities and relations from text, to date there exists little work on the acquisition of business processes from unstructured data such as textual corpora of process descriptions. With this work we aim at filling this gap and establishing the first steps towards bridging data-driven information extraction methodologies from Natural Language Processing and the model-based formalization that is aimed from Business Process Management. For this, we develop the first corpus of business process descriptions annotated with activities, gateways, actors and flow information. We present our new resource, including a detailed overview of the annotation schema and guidelines, as well as a variety of baselines to benchmark the difficulty and challenges of business process extraction from text.
Computing unsatisfiable cores for LTLf specifications
Mar 09, 2022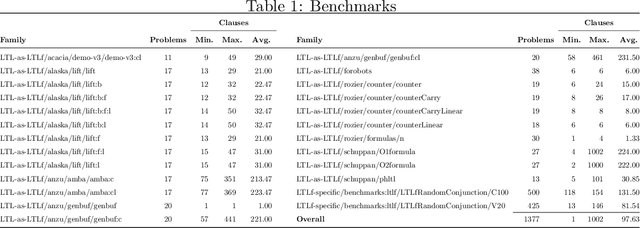
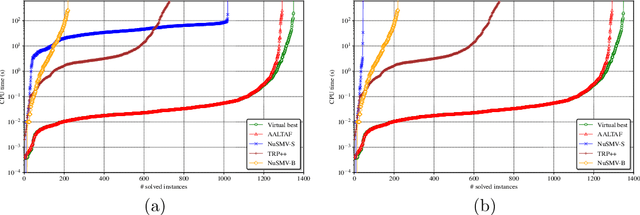
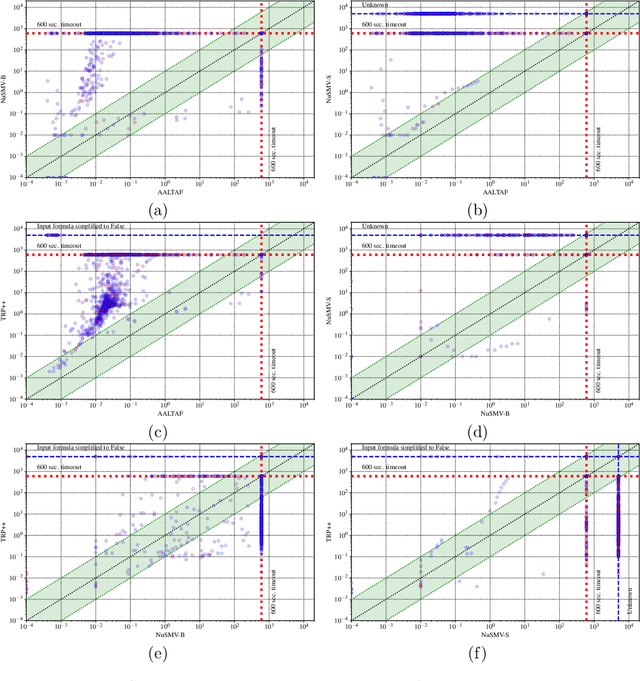
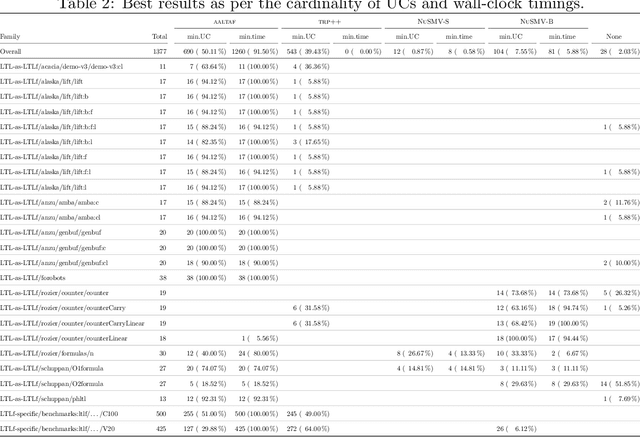
Linear-time temporal logic on finite traces (LTLf) is rapidly becoming a de-facto standard to produce specifications in many application domains (e.g., planning, business process management, run-time monitoring, reactive synthesis). Several studies approached the respective satisfiability problem. In this paper, we investigate the problem of extracting the unsatisfiable core in LTLf specifications. We provide four algorithms for extracting an unsatisfiable core leveraging the adaptation of state-of-the-art approaches to LTLf satisfiability checking. We implement the different approaches within the respective tools and carry out an experimental evaluation on a set of reference benchmarks, restricting to the unsatisfiable ones. The results show the feasibility, effectiveness, and complementarities of the different algorithms and tools.