 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplain, Adapt and Retrain: How to improve the accuracy of a PPM classifier through different explanation styles
Mar 27, 2023


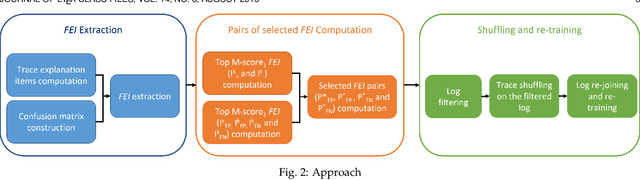
Recent papers have introduced a novel approach to explain why a Predictive Process Monitoring (PPM) model for outcome-oriented predictions provides wrong predictions. Moreover, they have shown how to exploit the explanations, obtained using state-of-the art post-hoc explainers, to identify the most common features that induce a predictor to make mistakes in a semi-automated way, and, in turn, to reduce the impact of those features and increase the accuracy of the predictive model. This work starts from the assumption that frequent control flow patterns in event logs may represent important features that characterize, and therefore explain, a certain prediction. Therefore, in this paper, we (i) employ a novel encoding able to leverage DECLARE constraints in Predictive Process Monitoring and compare the effectiveness of this encoding with Predictive Process Monitoring state-of-the art encodings, in particular for the task of outcome-oriented predictions; (ii) introduce a completely automated pipeline for the identification of the most common features inducing a predictor to make mistakes; and (iii) show the effectiveness of the proposed pipeline in increasing the accuracy of the predictive model by validating it on different real-life datasets.
Nirdizati: an Advanced Predictive Process Monitoring Toolkit
Oct 18, 2022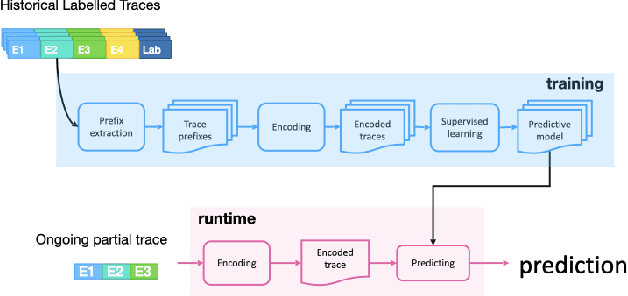

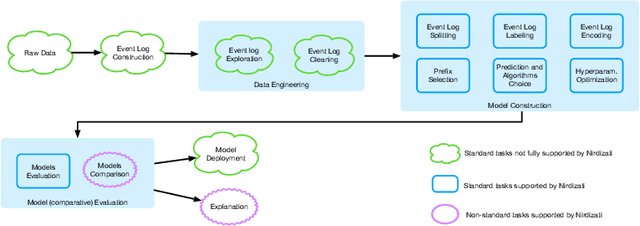
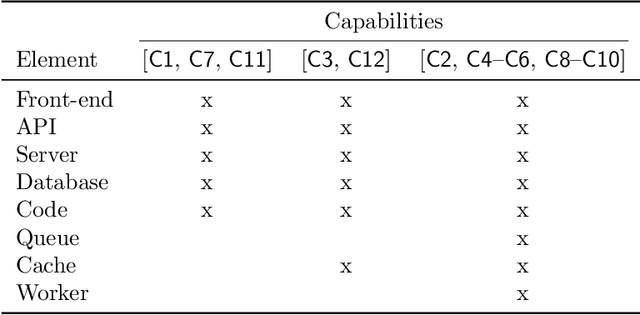
Predictive Process Monitoring is a field of Process Mining that aims at predicting how an ongoing execution of a business process will develop in the future using past process executions recorded in event logs. The recent stream of publications in this field shows the need for tools able to support researchers and users in analyzing, comparing and selecting the techniques that are the most suitable for them. Nirdizati is a dedicated tool for supporting users in building, comparing, analyzing, and explaining predictive models that can then be used to perform predictions on the future of an ongoing case. By providing a rich set of different state-of-the-art approaches, Nirdizati offers BPM researchers and practitioners a useful and flexible instrument for investigating and comparing Predictive Process Monitoring techniques. In this paper, we present the current version of Nirdizati, together with its architecture which has been developed to improve its modularity and scalability. The features of Nirdizati enrich its capability to support researchers and practitioners within the entire pipeline for constructing reliable Predictive Process Monitoring models.
Explainable Predictive Process Monitoring: A User Evaluation
Feb 15, 2022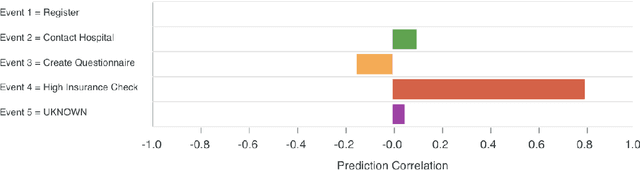
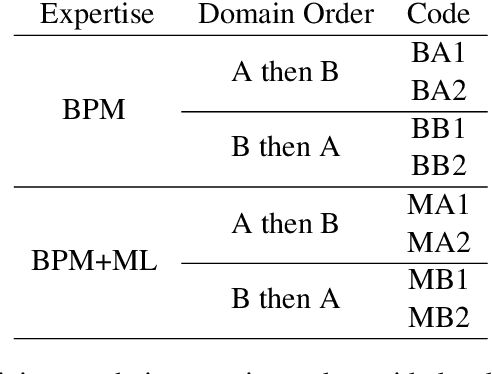
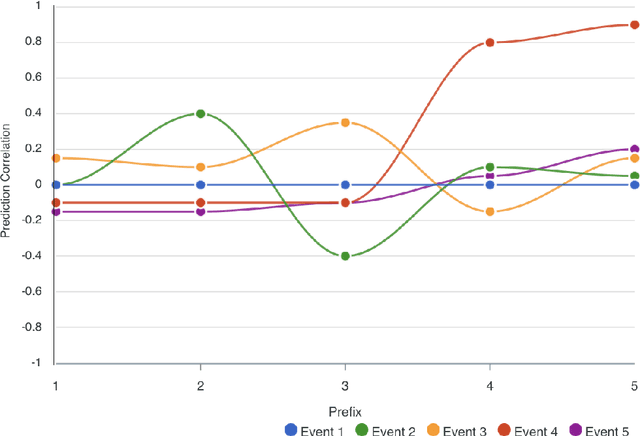
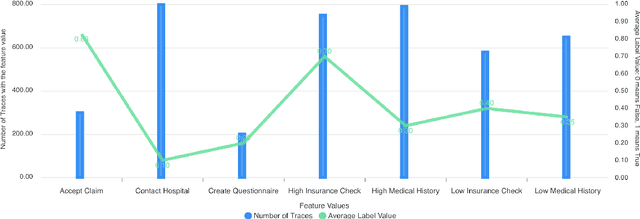
Explainability is motivated by the lack of transparency of black-box Machine Learning approaches, which do not foster trust and acceptance of Machine Learning algorithms. This also happens in the Predictive Process Monitoring field, where predictions, obtained by applying Machine Learning techniques, need to be explained to users, so as to gain their trust and acceptance. In this work, we carry on a user evaluation on explanation approaches for Predictive Process Monitoring aiming at investigating whether and how the explanations provided (i) are understandable; (ii) are useful in decision making tasks;(iii) can be further improved for process analysts, with different Machine Learning expertise levels. The results of the user evaluation show that, although explanation plots are overall understandable and useful for decision making tasks for Business Process Management users -- with and without experience in Machine Learning -- differences exist in the comprehension and usage of different plots, as well as in the way users with different Machine Learning expertise understand and use them.
Incremental Predictive Process Monitoring: How to Deal with the Variability of Real Environments
Apr 11, 2018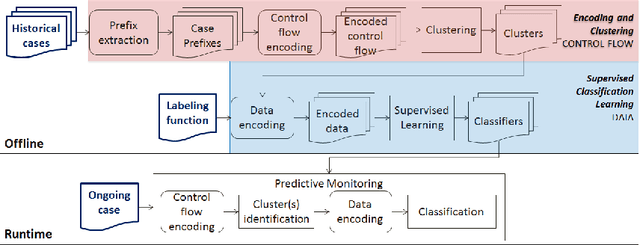


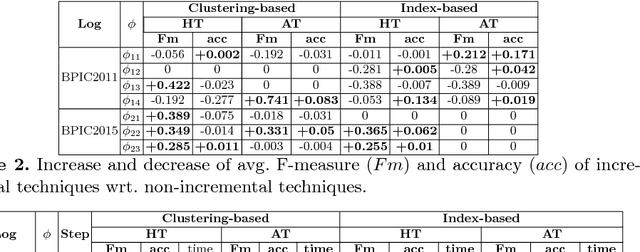
A characteristic of existing predictive process monitoring techniques is to first construct a predictive model based on past process executions, and then use it to predict the future of new ongoing cases, without the possibility of updating it with new cases when they complete their execution. This can make predictive process monitoring too rigid to deal with the variability of processes working in real environments that continuously evolve and/or exhibit new variant behaviors over time. As a solution to this problem, we propose the use of algorithms that allow the incremental construction of the predictive model. These incremental learning algorithms update the model whenever new cases become available so that the predictive model evolves over time to fit the current circumstances. The algorithms have been implemented using different case encoding strategies and evaluated on a number of real and synthetic datasets. The results provide a first evidence of the potential of incremental learning strategies for predicting process monitoring in real environments, and of the impact of different case encoding strategies in this setting.