 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine Learning and Statistical Insights into Hospital Stay Durations: The Italian EHR Case
Apr 25, 2025



Length of hospital stay is a critical metric for assessing healthcare quality and optimizing hospital resource management. This study aims to identify factors influencing LoS within the Italian healthcare context, using a dataset of hospitalization records from over 60 healthcare facilities in the Piedmont region, spanning from 2020 to 2023. We explored a variety of features, including patient characteristics, comorbidities, admission details, and hospital-specific factors. Significant correlations were found between LoS and features such as age group, comorbidity score, admission type, and the month of admission. Machine learning models, specifically CatBoost and Random Forest, were used to predict LoS. The highest R2 score, 0.49, was achieved with CatBoost, demonstrating good predictive performance.
A Pattern to Align Them All: Integrating Different Modalities to Define Multi-Modal Entities
Oct 17, 2024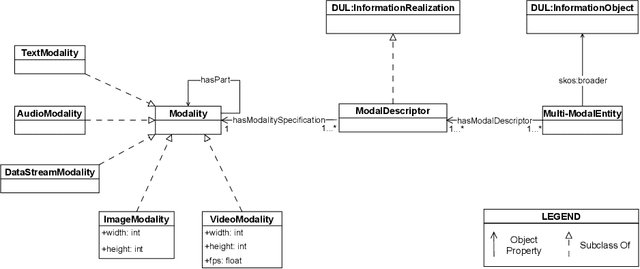

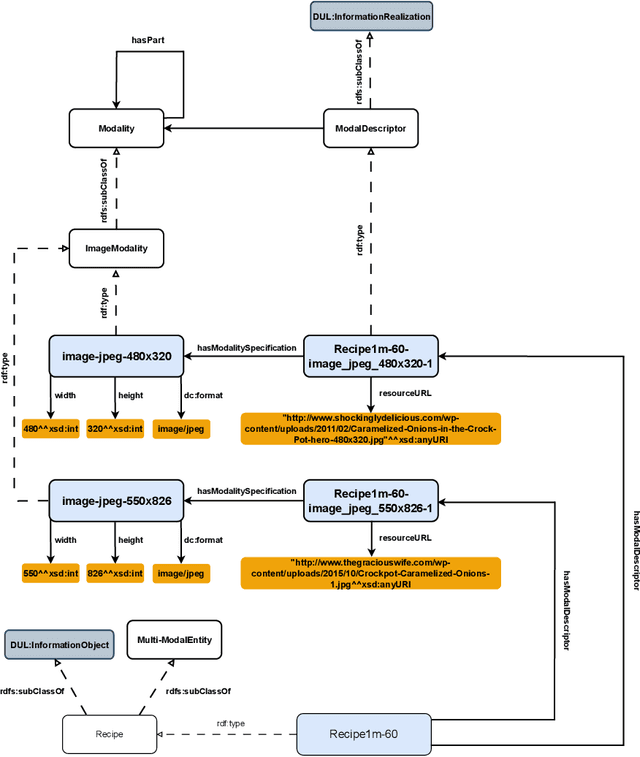
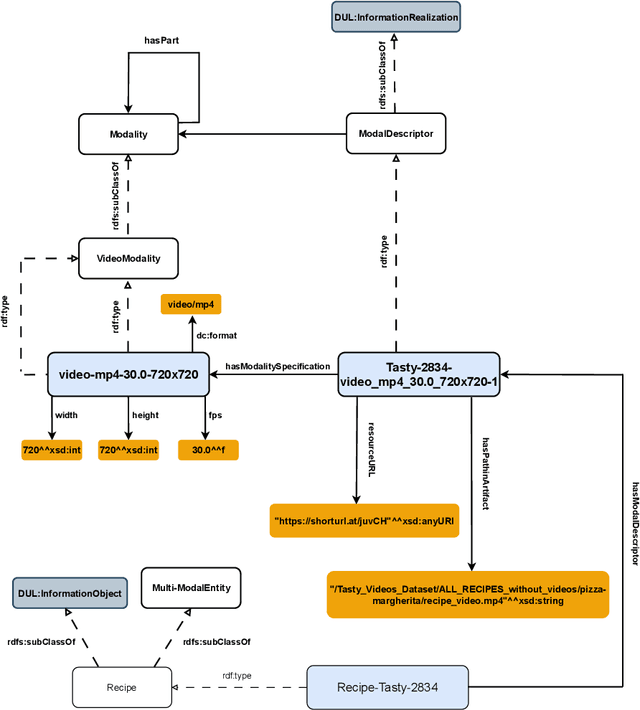
The ability to reason with and integrate different sensory inputs is the foundation underpinning human intelligence and it is the reason for the growing interest in modelling multi-modal information within Knowledge Graphs. Multi-Modal Knowledge Graphs extend traditional Knowledge Graphs by associating an entity with its possible modal representations, including text, images, audio, and videos, all of which are used to convey the semantics of the entity. Despite the increasing attention that Multi-Modal Knowledge Graphs have received, there is a lack of consensus about the definitions and modelling of modalities, whose definition is often determined by application domains. In this paper, we propose a novel ontology design pattern that captures the separation of concerns between an entity (and the information it conveys), whose semantics can have different manifestations across different media, and its realisation in terms of a physical information entity. By introducing this abstract model, we aim to facilitate the harmonisation and integration of different existing multi-modal ontologies which is crucial for many intelligent applications across different domains spanning from medicine to digital humanities.
Large Language Models and Knowledge Graphs: Opportunities and Challenges
Aug 11, 2023Large Language Models (LLMs) have taken Knowledge Representation -- and the world -- by storm. This inflection point marks a shift from explicit knowledge representation to a renewed focus on the hybrid representation of both explicit knowledge and parametric knowledge. In this position paper, we will discuss some of the common debate points within the community on LLMs (parametric knowledge) and Knowledge Graphs (explicit knowledge) and speculate on opportunities and visions that the renewed focus brings, as well as related research topics and challenges.
Leveraging pre-trained language models for conversational information seeking from text
Mar 31, 2022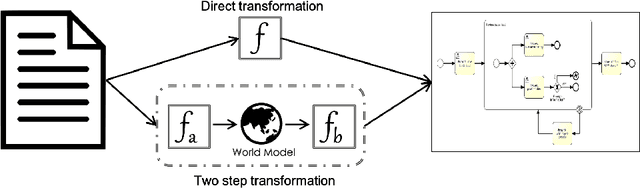
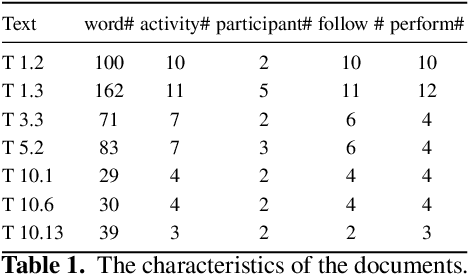
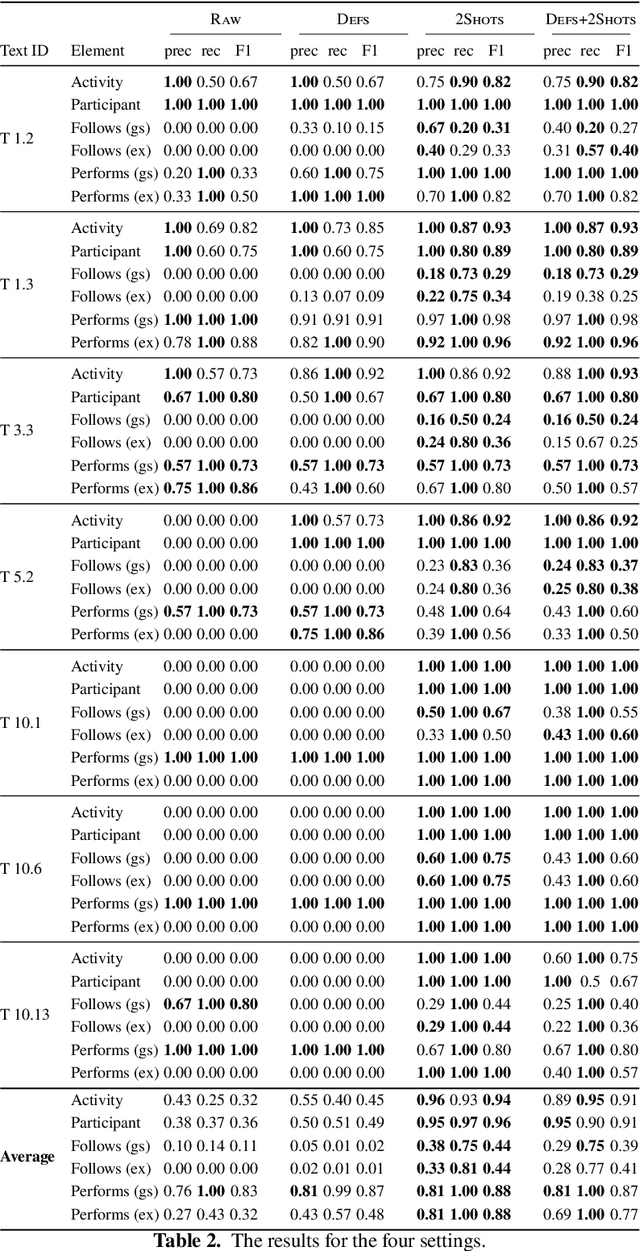
Recent advances in Natural Language Processing, and in particular on the construction of very large pre-trained language representation models, is opening up new perspectives on the construction of conversational information seeking (CIS) systems. In this paper we investigate the usage of in-context learning and pre-trained language representation models to address the problem of information extraction from process description documents, in an incremental question and answering oriented fashion. In particular we investigate the usage of the native GPT-3 (Generative Pre-trained Transformer 3) model, together with two in-context learning customizations that inject conceptual definitions and a limited number of samples in a few shot-learning fashion. The results highlight the potential of the approach and the usefulness of the in-context learning customizations, which can substantially contribute to address the "training data challenge" of deep learning based NLP techniques the BPM field. It also highlight the challenge posed by control flow relations for which further training needs to be devised.
PET: A new Dataset for Process Extraction from Natural Language Text
Mar 09, 2022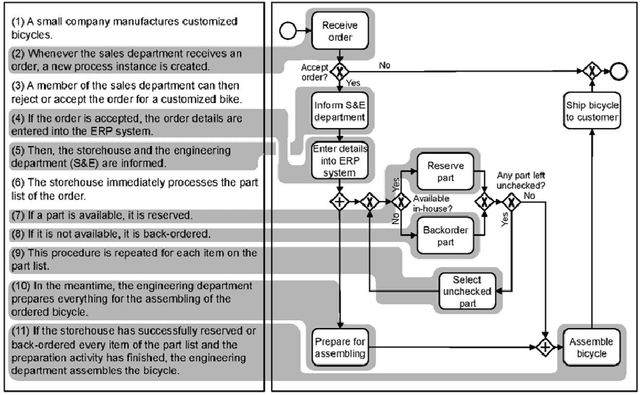
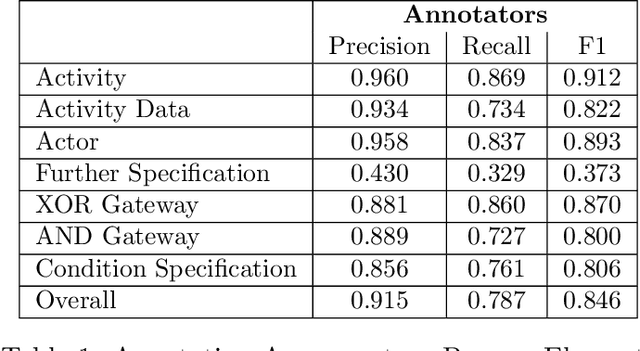
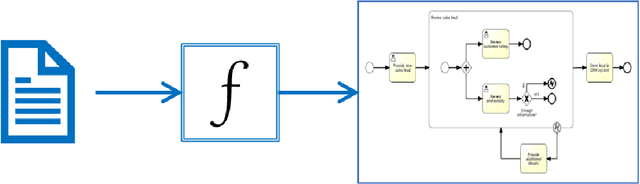

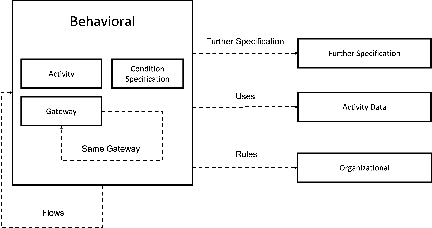
Although there is a long tradition of work in NLP on extracting entities and relations from text, to date there exists little work on the acquisition of business processes from unstructured data such as textual corpora of process descriptions. With this work we aim at filling this gap and establishing the first steps towards bridging data-driven information extraction methodologies from Natural Language Processing and the model-based formalization that is aimed from Business Process Management. For this, we develop the first corpus of business process descriptions annotated with activities, gateways, actors and flow information. We present our new resource, including a detailed overview of the annotation schema and guidelines, as well as a variety of baselines to benchmark the difficulty and challenges of business process extraction from text.
Machine Learning for Utility Prediction in Argument-Based Computational Persuasion
Dec 15, 2021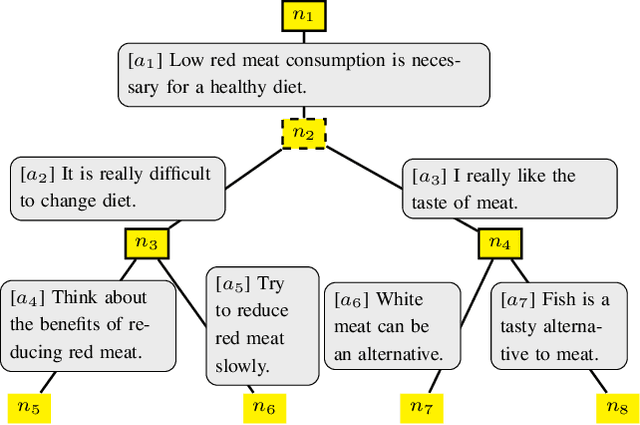
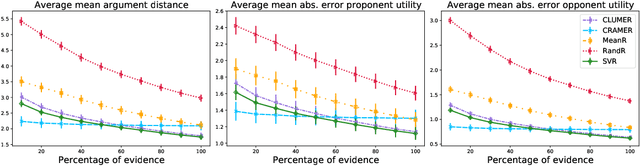
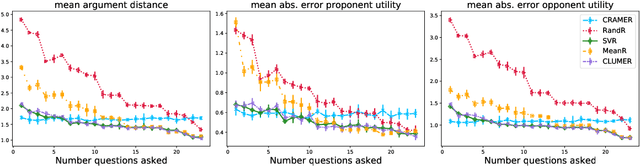
Automated persuasion systems (APS) aim to persuade a user to believe something by entering into a dialogue in which arguments and counterarguments are exchanged. To maximize the probability that an APS is successful in persuading a user, it can identify a global policy that will allow it to select the best arguments it presents at each stage of the dialogue whatever arguments the user presents. However, in real applications, such as for healthcare, it is unlikely the utility of the outcome of the dialogue will be the same, or the exact opposite, for the APS and user. In order to deal with this situation, games in extended form have been harnessed for argumentation in Bi-party Decision Theory. This opens new problems that we address in this paper: (1) How can we use Machine Learning (ML) methods to predict utility functions for different subpopulations of users? and (2) How can we identify for a new user the best utility function from amongst those that we have learned? To this extent, we develop two ML methods, EAI and EDS, that leverage information coming from the users to predict their utilities. EAI is restricted to a fixed amount of information, whereas EDS can choose the information that best detects the subpopulations of a user. We evaluate EAI and EDS in a simulation setting and in a realistic case study concerning healthy eating habits. Results are promising in both cases, but EDS is more effective at predicting useful utility functions.
A Practical Tutorial on Explainable AI Techniques
Nov 13, 2021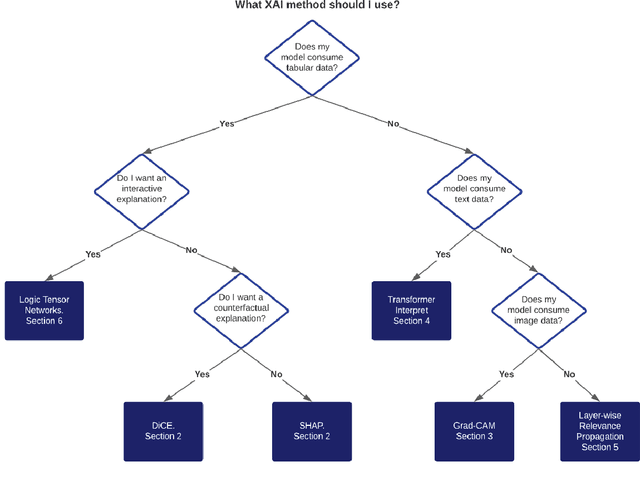
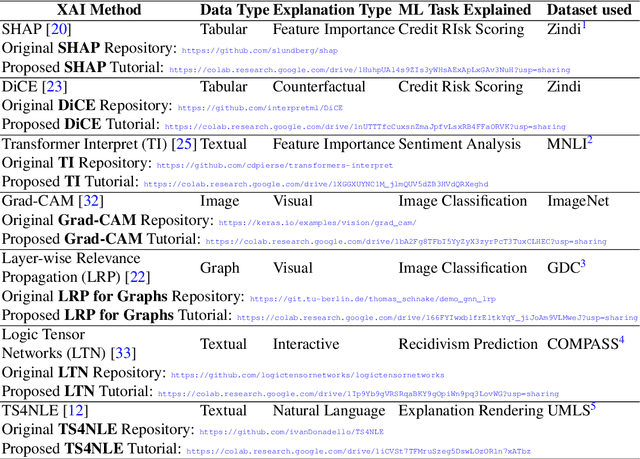
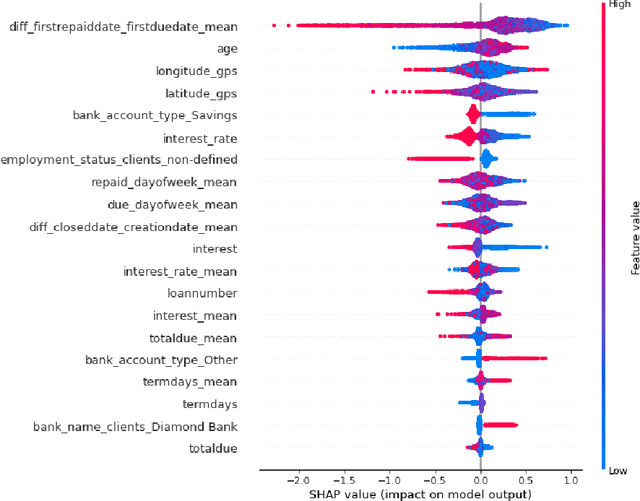
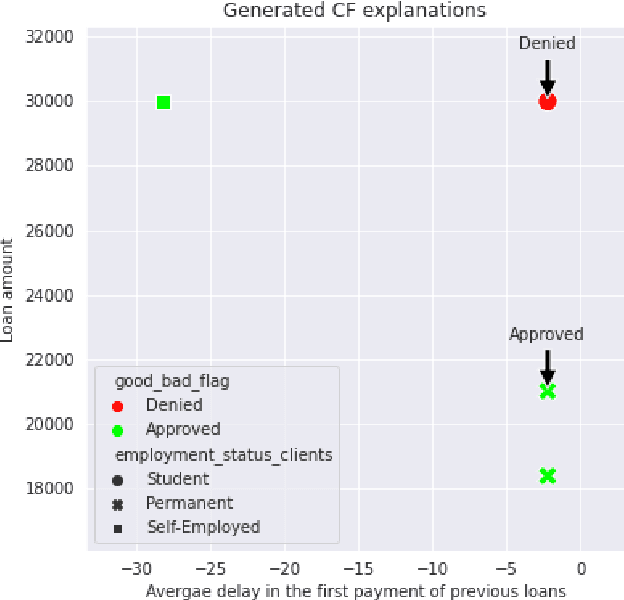
Last years have been characterized by an upsurge of opaque automatic decision support systems, such as Deep Neural Networks (DNNs). Although they have great generalization and prediction skills, their functioning does not allow obtaining detailed explanations of their behaviour. As opaque machine learning models are increasingly being employed to make important predictions in critical environments, the danger is to create and use decisions that are not justifiable or legitimate. Therefore, there is a general agreement on the importance of endowing machine learning models with explainability. The reason is that EXplainable Artificial Intelligence (XAI) techniques can serve to verify and certify model outputs and enhance them with desirable notions such as trustworthiness, accountability, transparency and fairness. This tutorial is meant to be the go-to handbook for any audience with a computer science background aiming at getting intuitive insights of machine learning models, accompanied with straight, fast, and intuitive explanations out of the box. We believe that these methods provide a valuable contribution for applying XAI techniques in their particular day-to-day models, datasets and use-cases. Figure \ref{fig:Flowchart} acts as a flowchart/map for the reader and should help him to find the ideal method to use according to his type of data. The reader will find a description of the proposed method as well as an example of use and a Python notebook that he can easily modify as he pleases in order to apply it to his own case of application.
Process Extraction from Text: state of the art and challenges for the future
Oct 07, 2021
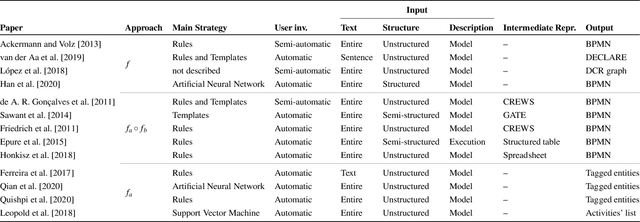
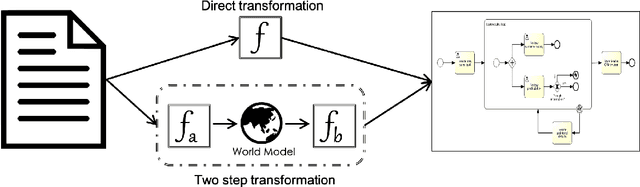
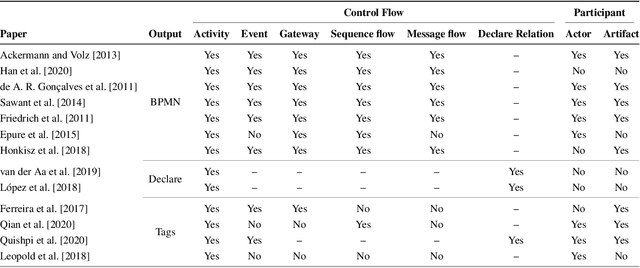
Automatic Process Discovery aims at developing algorithmic methodologies for the extraction and elicitation of process models as described in data. While Process Discovery from event-log data is a well established area, that has already moved from research to concrete adoption in a mature manner, Process Discovery from text is still a research area at an early stage of development, which rarely scales to real world documents. In this paper we analyze, in a comparative manner, reference state-of-the-art literature, especially for what concerns the techniques used, the process elements extracted and the evaluations performed. As a result of the analysis we discuss important limitations that hamper the exploitation of recent Natural Language Processing techniques in this field and we discuss fundamental limitations and challenges for the future concerning the datasets, the techniques, the experimental evaluations, and the pipelines currently adopted and to be developed in the future.