 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging pre-trained language models for conversational information seeking from text
Paper and Code
Mar 31, 2022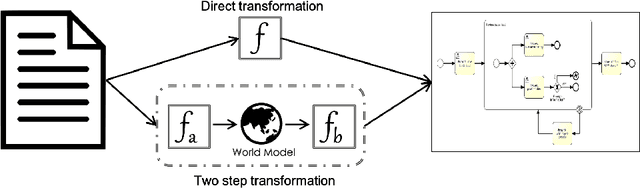
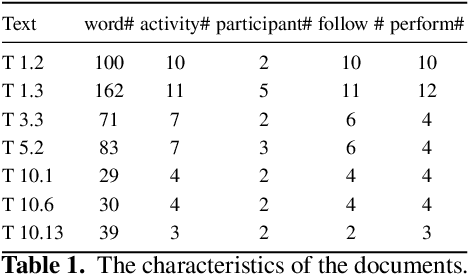
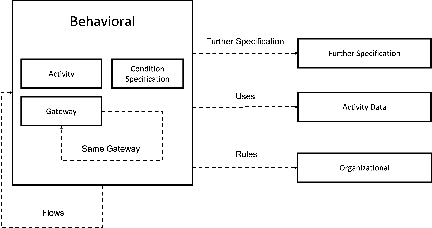
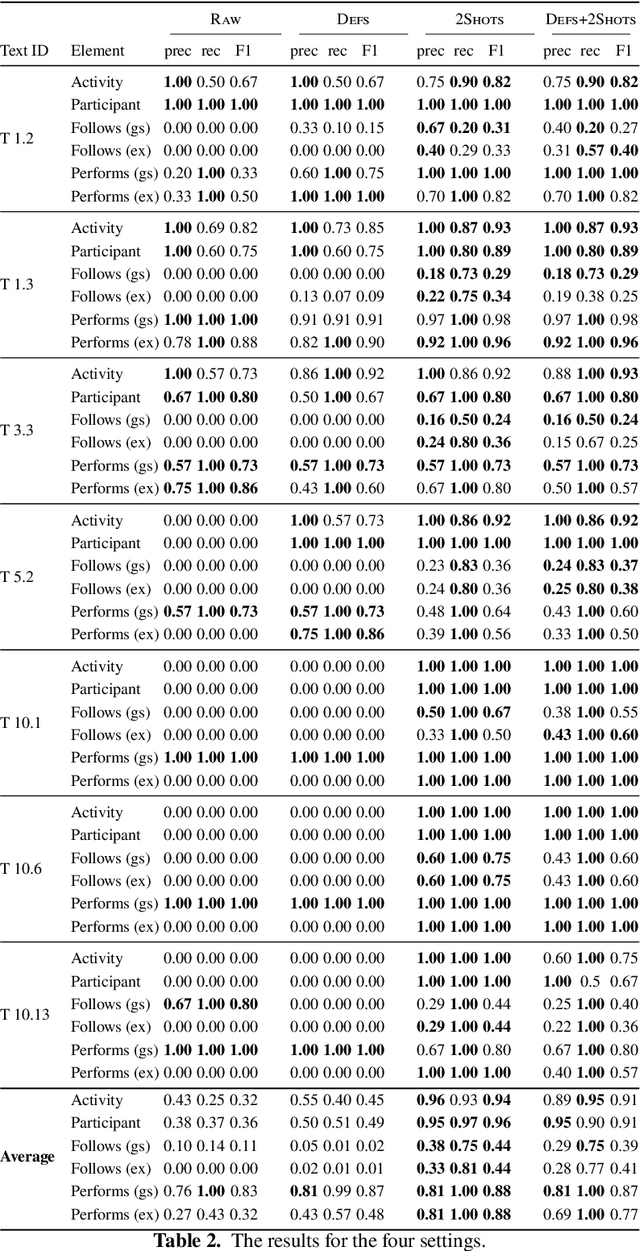
Recent advances in Natural Language Processing, and in particular on the construction of very large pre-trained language representation models, is opening up new perspectives on the construction of conversational information seeking (CIS) systems. In this paper we investigate the usage of in-context learning and pre-trained language representation models to address the problem of information extraction from process description documents, in an incremental question and answering oriented fashion. In particular we investigate the usage of the native GPT-3 (Generative Pre-trained Transformer 3) model, together with two in-context learning customizations that inject conceptual definitions and a limited number of samples in a few shot-learning fashion. The results highlight the potential of the approach and the usefulness of the in-context learning customizations, which can substantially contribute to address the "training data challenge" of deep learning based NLP techniques the BPM field. It also highlight the challenge posed by control flow relations for which further training needs to be devised.