 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Responsible AI Music: an Investigation of Trustworthy Features for Creative Systems
Mar 24, 2025Generative AI is radically changing the creative arts, by fundamentally transforming the way we create and interact with cultural artefacts. While offering unprecedented opportunities for artistic expression and commercialisation, this technology also raises ethical, societal, and legal concerns. Key among these are the potential displacement of human creativity, copyright infringement stemming from vast training datasets, and the lack of transparency, explainability, and fairness mechanisms. As generative systems become pervasive in this domain, responsible design is crucial. Whilst previous work has tackled isolated aspects of generative systems (e.g., transparency, evaluation, data), we take a comprehensive approach, grounding these efforts within the Ethics Guidelines for Trustworthy Artificial Intelligence produced by the High-Level Expert Group on AI appointed by the European Commission - a framework for designing responsible AI systems across seven macro requirements. Focusing on generative music AI, we illustrate how these requirements can be contextualised for the field, addressing trustworthiness across multiple dimensions and integrating insights from the existing literature. We further propose a roadmap for operationalising these contextualised requirements, emphasising interdisciplinary collaboration and stakeholder engagement. Our work provides a foundation for designing and evaluating responsible music generation systems, calling for collaboration among AI experts, ethicists, legal scholars, and artists. This manuscript is accompanied by a website: https://amresearchlab.github.io/raim-framework/.
PathE: Leveraging Entity-Agnostic Paths for Parameter-Efficient Knowledge Graph Embeddings
Jan 31, 2025Knowledge Graphs (KGs) store human knowledge in the form of entities (nodes) and relations, and are used extensively in various applications. KG embeddings are an effective approach to addressing tasks like knowledge discovery, link prediction, and reasoning. This is often done by allocating and learning embedding tables for all or a subset of the entities. As this scales linearly with the number of entities, learning embedding models in real-world KGs with millions of nodes can be computationally intractable. To address this scalability problem, our model, PathE, only allocates embedding tables for relations (which are typically orders of magnitude fewer than the entities) and requires less than 25% of the parameters of previous parameter efficient methods. Rather than storing entity embeddings, we learn to compute them by leveraging multiple entity-relation paths to contextualise individual entities within triples. Evaluated on four benchmarks, PathE achieves state-of-the-art performance in relation prediction, and remains competitive in link prediction on path-rich KGs while training on consumer-grade hardware. We perform ablation experiments to test our design choices and analyse the sensitivity of the model to key hyper-parameters. PathE is efficient and cost-effective for relationally diverse and well-connected KGs commonly found in real-world applications.
A Pattern to Align Them All: Integrating Different Modalities to Define Multi-Modal Entities
Oct 17, 2024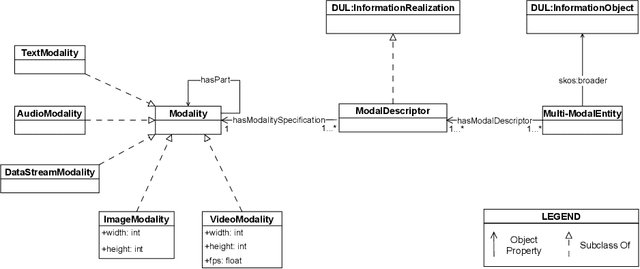

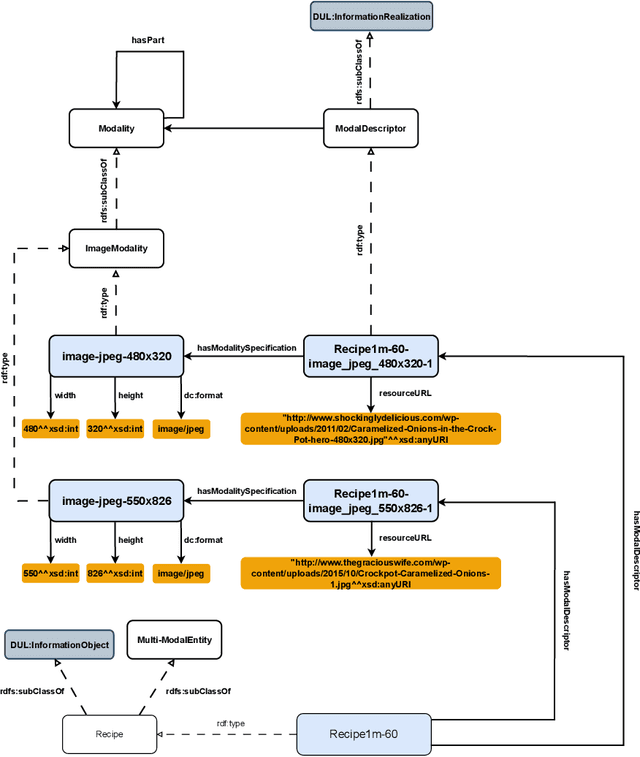
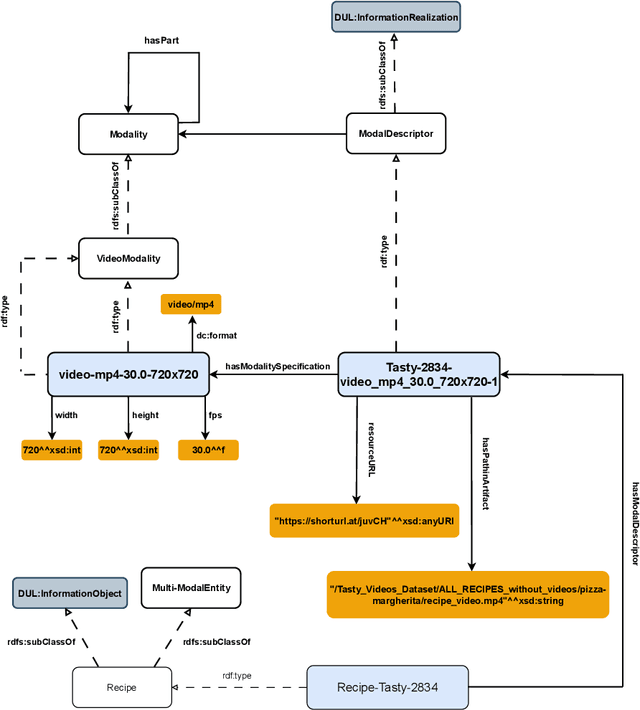
The ability to reason with and integrate different sensory inputs is the foundation underpinning human intelligence and it is the reason for the growing interest in modelling multi-modal information within Knowledge Graphs. Multi-Modal Knowledge Graphs extend traditional Knowledge Graphs by associating an entity with its possible modal representations, including text, images, audio, and videos, all of which are used to convey the semantics of the entity. Despite the increasing attention that Multi-Modal Knowledge Graphs have received, there is a lack of consensus about the definitions and modelling of modalities, whose definition is often determined by application domains. In this paper, we propose a novel ontology design pattern that captures the separation of concerns between an entity (and the information it conveys), whose semantics can have different manifestations across different media, and its realisation in terms of a physical information entity. By introducing this abstract model, we aim to facilitate the harmonisation and integration of different existing multi-modal ontologies which is crucial for many intelligent applications across different domains spanning from medicine to digital humanities.
OntoChat: a Framework for Conversational Ontology Engineering using Language Models
Mar 09, 2024Ontology engineering (OE) in large projects poses a number of challenges arising from the heterogeneous backgrounds of the various stakeholders, domain experts, and their complex interactions with ontology designers. This multi-party interaction often creates systematic ambiguities and biases from the elicitation of ontology requirements, which directly affect the design, evaluation and may jeopardise the target reuse. Meanwhile, current OE methodologies strongly rely on manual activities (e.g., interviews, discussion pages). After collecting evidence on the most crucial OE activities, we introduce OntoChat, a framework for conversational ontology engineering that supports requirement elicitation, analysis, and testing. By interacting with a conversational agent, users can steer the creation of user stories and the extraction of competency questions, while receiving computational support to analyse the overall requirements and test early versions of the resulting ontologies. We evaluate OntoChat by replicating the engineering of the Music Meta Ontology, and collecting preliminary metrics on the effectiveness of each component from users. We release all code at https://github.com/King-s-Knowledge-Graph-Lab/OntoChat.
The Music Meta Ontology: a flexible semantic model for the interoperability of music metadata
Nov 07, 2023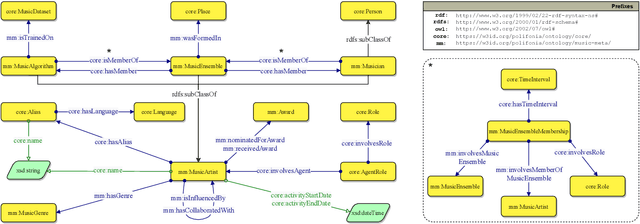
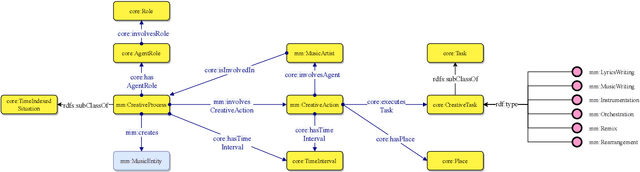
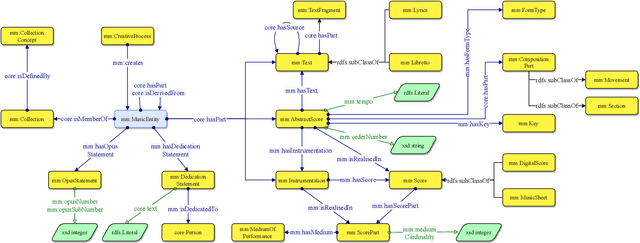

The semantic description of music metadata is a key requirement for the creation of music datasets that can be aligned, integrated, and accessed for information retrieval and knowledge discovery. It is nonetheless an open challenge due to the complexity of musical concepts arising from different genres, styles, and periods -- standing to benefit from a lingua franca to accommodate various stakeholders (musicologists, librarians, data engineers, etc.). To initiate this transition, we introduce the Music Meta ontology, a rich and flexible semantic model to describe music metadata related to artists, compositions, performances, recordings, and links. We follow eXtreme Design methodologies and best practices for data engineering, to reflect the perspectives and the requirements of various stakeholders into the design of the model, while leveraging ontology design patterns and accounting for provenance at different levels (claims, links). After presenting the main features of Music Meta, we provide a first evaluation of the model, alignments to other schema (Music Ontology, DOREMUS, Wikidata), and support for data transformation.
The Music Annotation Pattern
Mar 30, 2023The annotation of music content is a complex process to represent due to its inherent multifaceted, subjectivity, and interdisciplinary nature. Numerous systems and conventions for annotating music have been developed as independent standards over the past decades. Little has been done to make them interoperable, which jeopardises cross-corpora studies as it requires users to familiarise with a multitude of conventions. Most of these systems lack the semantic expressiveness needed to represent the complexity of the musical language and cannot model multi-modal annotations originating from audio and symbolic sources. In this article, we introduce the Music Annotation Pattern, an Ontology Design Pattern (ODP) to homogenise different annotation systems and to represent several types of musical objects (e.g. chords, patterns, structures). This ODP preserves the semantics of the object's content at different levels and temporal granularity. Moreover, our ODP accounts for multi-modality upfront, to describe annotations derived from different sources, and it is the first to enable the integration of music datasets at a large scale.
SOLIS: Autonomous Solubility Screening using Deep Neural Networks
Mar 18, 2022



Accelerating material discovery has tremendous societal and industrial impact, particularly for pharmaceuticals and clean energy production. Many experimental instruments have some degree of automation, facilitating continuous running and higher throughput. However, it is common that sample preparation is still carried out manually. This can result in researchers spending a significant amount of their time on repetitive tasks, which introduces errors and can prohibit production of statistically relevant data. Crystallisation experiments are common in many chemical fields, both for purification and in polymorph screening experiments. The initial step often involves a solubility screen of the molecule; that is, understanding whether molecular compounds have dissolved in a particular solvent. This usually can be time consuming and work intensive. Moreover, accurate knowledge of the precise solubility limit of the molecule is often not required, and simply measuring a threshold of solubility in each solvent would be sufficient. To address this, we propose a novel cascaded deep model that is inspired by how a human chemist would visually assess a sample to determine whether the solid has completely dissolved in the solution. In this paper, we design, develop, and evaluate the first fully autonomous solubility screening framework, which leverages state-of-the-art methods for image segmentation and convolutional neural networks for image classification. To realise that, we first create a dataset comprising different molecules and solvents, which is collected in a real-world chemistry laboratory. We then evaluated our method on the data recorded through an eye-in-hand camera mounted on a seven degree-of-freedom robotic manipulator, and show that our model can achieve 99.13% test accuracy across various setups.