 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProcess Extraction from Text: state of the art and challenges for the future
Paper and Code

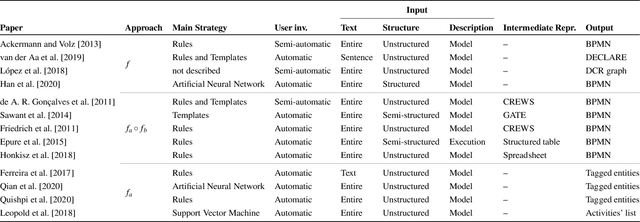
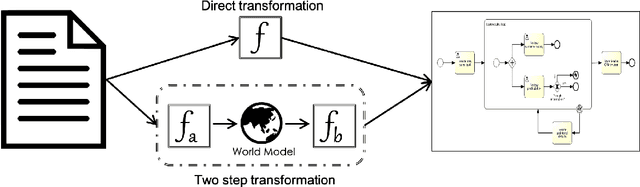
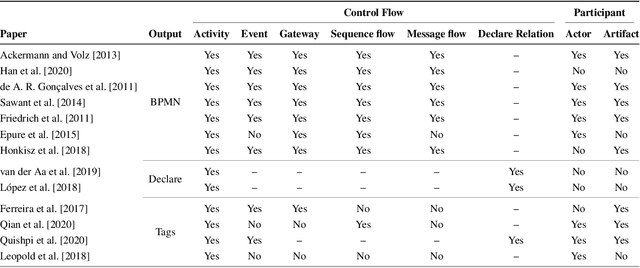
Automatic Process Discovery aims at developing algorithmic methodologies for the extraction and elicitation of process models as described in data. While Process Discovery from event-log data is a well established area, that has already moved from research to concrete adoption in a mature manner, Process Discovery from text is still a research area at an early stage of development, which rarely scales to real world documents. In this paper we analyze, in a comparative manner, reference state-of-the-art literature, especially for what concerns the techniques used, the process elements extracted and the evaluations performed. As a result of the analysis we discuss important limitations that hamper the exploitation of recent Natural Language Processing techniques in this field and we discuss fundamental limitations and challenges for the future concerning the datasets, the techniques, the experimental evaluations, and the pipelines currently adopted and to be developed in the future.