 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFairLoop: Software Support for Human-Centric Fairness in Predictive Business Process Monitoring
Aug 27, 2025Sensitive attributes like gender or age can lead to unfair predictions in machine learning tasks such as predictive business process monitoring, particularly when used without considering context. We present FairLoop1, a tool for human-guided bias mitigation in neural network-based prediction models. FairLoop distills decision trees from neural networks, allowing users to inspect and modify unfair decision logic, which is then used to fine-tune the original model towards fairer predictions. Compared to other approaches to fairness, FairLoop enables context-aware bias removal through human involvement, addressing the influence of sensitive attributes selectively rather than excluding them uniformly.
A Human-In-The-Loop Approach for Improving Fairness in Predictive Business Process Monitoring
Aug 24, 2025Predictive process monitoring enables organizations to proactively react and intervene in running instances of a business process. Given an incomplete process instance, predictions about the outcome, next activity, or remaining time are created. This is done by powerful machine learning models, which have shown impressive predictive performance. However, the data-driven nature of these models makes them susceptible to finding unfair, biased, or unethical patterns in the data. Such patterns lead to biased predictions based on so-called sensitive attributes, such as the gender or age of process participants. Previous work has identified this problem and offered solutions that mitigate biases by removing sensitive attributes entirely from the process instance. However, sensitive attributes can be used both fairly and unfairly in the same process instance. For example, during a medical process, treatment decisions could be based on gender, while the decision to accept a patient should not be based on gender. This paper proposes a novel, model-agnostic approach for identifying and rectifying biased decisions in predictive business process monitoring models, even when the same sensitive attribute is used both fairly and unfairly. The proposed approach uses a human-in-the-loop approach to differentiate between fair and unfair decisions through simple alterations on a decision tree model distilled from the original prediction model. Our results show that the proposed approach achieves a promising tradeoff between fairness and accuracy in the presence of biased data. All source code and data are publicly available at https://doi.org/10.5281/zenodo.15387576.
Assisted Data Annotation for Business Process Information Extraction from Textual Documents
Oct 02, 2024



Machine-learning based generation of process models from natural language text process descriptions provides a solution for the time-intensive and expensive process discovery phase. Many organizations have to carry out this phase, before they can utilize business process management and its benefits. Yet, research towards this is severely restrained by an apparent lack of large and high-quality datasets. This lack of data can be attributed to, among other things, an absence of proper tool assistance for dataset creation, resulting in high workloads and inferior data quality. We explore two assistance features to support dataset creation, a recommendation system for identifying process information in the text and visualization of the current state of already identified process information as a graphical business process model. A controlled user study with 31 participants shows that assisting dataset creators with recommendations lowers all aspects of workload, up to $-51.0\%$, and significantly improves annotation quality, up to $+38.9\%$. We make all data and code available to encourage further research on additional novel assistance strategies.
Attention Please: What Transformer Models Really Learn for Process Prediction
Aug 12, 2024Predictive process monitoring aims to support the execution of a process during runtime with various predictions about the further evolution of a process instance. In the last years a plethora of deep learning architectures have been established as state-of-the-art for different prediction targets, among others the transformer architecture. The transformer architecture is equipped with a powerful attention mechanism, assigning attention scores to each input part that allows to prioritize most relevant information leading to more accurate and contextual output. However, deep learning models largely represent a black box, i.e., their reasoning or decision-making process cannot be understood in detail. This paper examines whether the attention scores of a transformer based next-activity prediction model can serve as an explanation for its decision-making. We find that attention scores in next-activity prediction models can serve as explainers and exploit this fact in two proposed graph-based explanation approaches. The gained insights could inspire future work on the improvement of predictive business process models as well as enabling a neural network based mining of process models from event logs.
A Universal Prompting Strategy for Extracting Process Model Information from Natural Language Text using Large Language Models
Jul 26, 2024Over the past decade, extensive research efforts have been dedicated to the extraction of information from textual process descriptions. Despite the remarkable progress witnessed in natural language processing (NLP), information extraction within the Business Process Management domain remains predominantly reliant on rule-based systems and machine learning methodologies. Data scarcity has so far prevented the successful application of deep learning techniques. However, the rapid progress in generative large language models (LLMs) makes it possible to solve many NLP tasks with very high quality without the need for extensive data. Therefore, we systematically investigate the potential of LLMs for extracting information from textual process descriptions, targeting the detection of process elements such as activities and actors, and relations between them. Using a heuristic algorithm, we demonstrate the suitability of the extracted information for process model generation. Based on a novel prompting strategy, we show that LLMs are able to outperform state-of-the-art machine learning approaches with absolute performance improvements of up to 8\% $F_1$ score across three different datasets. We evaluate our prompting strategy on eight different LLMs, showing it is universally applicable, while also analyzing the impact of certain prompt parts on extraction quality. The number of example texts, the specificity of definitions, and the rigour of format instructions are identified as key for improving the accuracy of extracted information. Our code, prompts, and data are publicly available.
Recent Advances in Data-Driven Business Process Management
Jun 03, 2024



The rapid development of cutting-edge technologies, the increasing volume of data and also the availability and processability of new types of data sources has led to a paradigm shift in data-based management and decision-making. Since business processes are at the core of organizational work, these developments heavily impact BPM as a crucial success factor for organizations. In view of this emerging potential, data-driven business process management has become a relevant and vibrant research area. Given the complexity and interdisciplinarity of the research field, this position paper therefore presents research insights regarding data-driven BPM.
Leveraging Data Augmentation for Process Information Extraction
Apr 11, 2024Business Process Modeling projects often require formal process models as a central component. High costs associated with the creation of such formal process models motivated many different fields of research aimed at automated generation of process models from readily available data. These include process mining on event logs, and generating business process models from natural language texts. Research in the latter field is regularly faced with the problem of limited data availability, hindering both evaluation and development of new techniques, especially learning-based ones. To overcome this data scarcity issue, in this paper we investigate the application of data augmentation for natural language text data. Data augmentation methods are well established in machine learning for creating new, synthetic data without human assistance. We find that many of these methods are applicable to the task of business process information extraction, improving the accuracy of extraction. Our study shows, that data augmentation is an important component in enabling machine learning methods for the task of business process model generation from natural language text, where currently mostly rule-based systems are still state of the art. Simple data augmentation techniques improved the $F_1$ score of mention extraction by 2.9 percentage points, and the $F_1$ of relation extraction by $4.5$. To better understand how data augmentation alters human annotated texts, we analyze the resulting text, visualizing and discussing the properties of augmented textual data. We make all code and experiments results publicly available.
Beyond Rule-based Named Entity Recognition and Relation Extraction for Process Model Generation from Natural Language Text
May 06, 2023Automated generation of business process models from natural language text is an emerging methodology for avoiding the manual creation of formal business process models. For this purpose, process entities like actors, activities, objects etc., and relations among them are extracted from textual process descriptions. A high-quality annotated corpus of textual process descriptions (PET) has been published accompanied with a basic process extraction approach. In its current state, however, PET lacks information about whether two mentions refer to the same or different process entities, which corresponds to the crucial decision of whether to create one or two modeling elements in the target model. Consequently, it is ambiguous whether, for instance, two mentions of data processing mean processing of different, or the same data. In this paper, we extend the PET dataset by clustering mentions of process entities and by proposing a new baseline technique for process extraction equipped with an additional entity resolution component. In a second step, we replace the rule-based relation extraction component with a machine learning-based alternative, enabling rapid adaption to different datasets and domains. In addition, we evaluate a deep learning-approach built for solving entity and relation extraction as well as entity resolution in a holistic manner. Finally, our extensive evaluation of the original PET baseline against our own implementation shows that a pure machine learning-based process extraction technique is competitive, while avoiding the massive overhead arising from feature engineering and rule definition needed to adapt to other datasets, different entity and relation types, or new domains.
Evaluating Predictive Business Process Monitoring Approaches on Small Event Logs
Apr 20, 2021

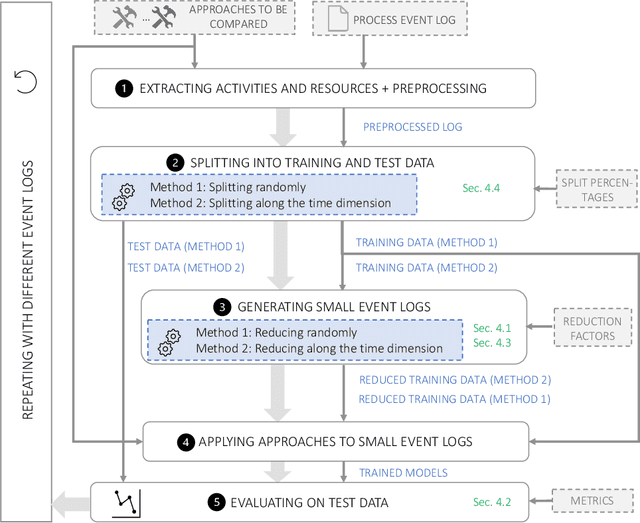
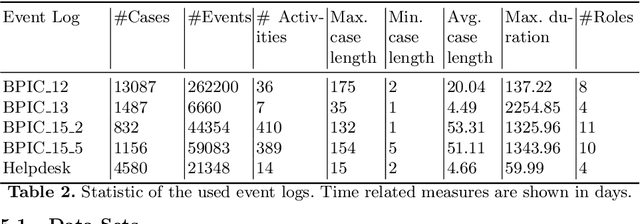
Predictive business process monitoring is concerned with the prediction how a running process instance will unfold up to its completion at runtime. Most of the proposed approaches rely on a wide number of different machine learning (ML) techniques. In the last years numerous comparative studies, reviews, and benchmarks of such approaches where published and revealed that they can be successfully applied for different prediction targets. ML techniques require a qualitatively and quantitatively sufficient data set. However, there are many situations in business process management (BPM) where only a quantitatively insufficient data set is available. The problem of insufficient data in the context of BPM is still neglected. Hence, none of the comparative studies or benchmarks investigates the performance of predictive business process monitoring techniques in environments with small data sets. In this paper an evaluation framework for comparing existing approaches with regard to their suitability for small data sets is developed and exemplarily applied to state-of-the-art approaches in predictive business process monitoring.