 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeControl-flow Reconstruction Attacks on Business Process Models
Sep 17, 2024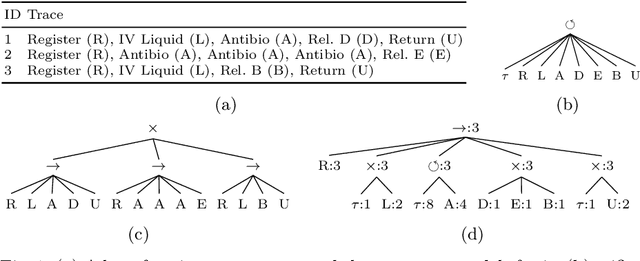
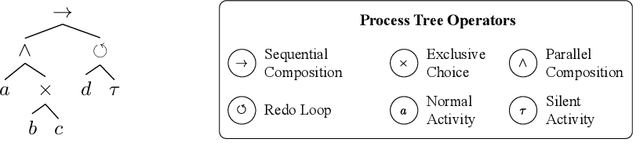
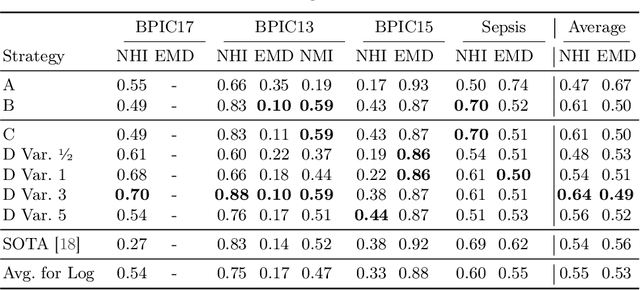
Process models may be automatically generated from event logs that contain as-is data of a business process. While such models generalize over the control-flow of specific, recorded process executions, they are often also annotated with behavioural statistics, such as execution frequencies.Based thereon, once a model is published, certain insights about the original process executions may be reconstructed, so that an external party may extract confidential information about the business process. This work is the first to empirically investigate such reconstruction attempts based on process models. To this end, we propose different play-out strategies that reconstruct the control-flow from process trees, potentially exploiting frequency annotations. To assess the potential success of such reconstruction attacks on process models, and hence the risks imposed by publishing them, we compare the reconstructed process executions with those of the original log for several real-world datasets.
What Averages Do Not Tell -- Predicting Real Life Processes with Sequential Deep Learning
Oct 31, 2021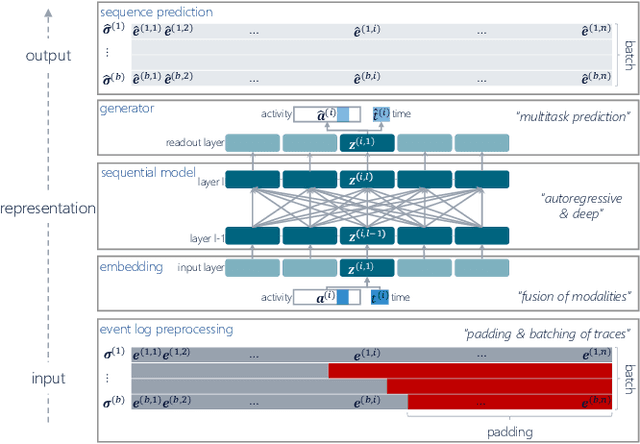
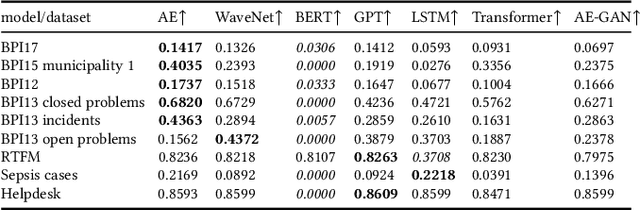
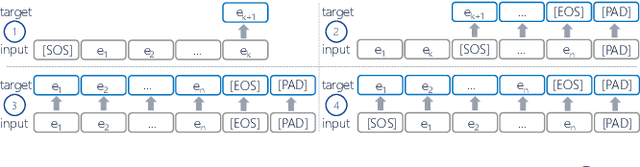
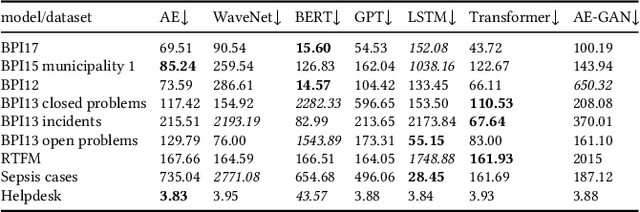
Deep Learning is proven to be an effective tool for modeling sequential data as shown by the success in Natural Language, Computer Vision and Signal Processing. Process Mining concerns discovering insights on business processes from their execution data that are logged by supporting information systems. The logged data (event log) is formed of event sequences (traces) that correspond to executions of a process. Many Deep Learning techniques have been successfully adapted for predictive Process Mining that aims to predict process outcomes, remaining time, the next event, or even the suffix of running traces. Traces in Process Mining are multimodal sequences and very differently structured than natural language sentences or images. This may require a different approach to processing. So far, there has been little focus on these differences and the challenges introduced. Looking at suffix prediction as the most challenging of these tasks, the performance of Deep Learning models was evaluated only on average measures and for a small number of real-life event logs. Comparing the results between papers is difficult due to different pre-processing and evaluation strategies. Challenges that may be relevant are the skewness of trace-length distribution and the skewness of the activity distribution in real-life event logs. We provide an end-to-end framework which enables to compare the performance of seven state-of-the-art sequential architectures in common settings. Results show that sequence modeling still has a lot of room for improvement for majority of the more complex datasets. Further research and insights are required to get consistent performance not just in average measures but additionally over all the prefixes.
Unsupervised Event Abstraction using Pattern Abstraction and Local Process Models
May 16, 2017


Process mining analyzes business processes based on events stored in event logs. However, some recorded events may correspond to activities on a very low level of abstraction. When events are recorded on a too low level of granularity, process discovery methods tend to generate overgeneralizing process models. Grouping low-level events to higher level activities, i.e., event abstraction, can be used to discover better process models. Existing event abstraction methods are mainly based on common sub-sequences and clustering techniques. In this paper, we propose to first discover local process models and then use those models to lift the event log to a higher level of abstraction. Our conjecture is that process models discovered on the obtained high-level event log return process models of higher quality: their fitness and precision scores are more balanced. We show this with preliminary results on several real-life event logs.