 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChameleons do not Forget: Prompt-Based Online Continual Learning for Next Activity Prediction
Apr 02, 2026Predictive process monitoring (PPM) focuses on predicting future process trajectories, including next activity predictions. This is crucial in dynamic environments where processes change or face uncertainty. However, current frameworks often assume a static environment, overlooking dynamic characteristics and concept drifts. This results in catastrophic forgetting, where training while focusing merely on new data distribution negatively impacts the performance on previously learned data distributions. Continual learning addresses, among others, the challenges related to mitigating catastrophic forgetting. This paper proposes a novel approach called Continual Next Activity Prediction with Prompts (CNAPwP), which adapts the DualPrompt algorithm for next activity prediction to improve accuracy and adaptability while mitigating catastrophic forgetting. We introduce new datasets with recurring concept drifts, alongside a task-specific forgetting metric that measures the prediction accuracy gap between initial occurrence and subsequent task occurrences. Extensive testing on three synthetic and two real-world datasets representing several setups of recurrent drifts shows that CNAPwP achieves SOTA or competitive results compared to five baselines, demonstrating its potential applicability in real-world scenarios. An open-source implementation of our method, together with the datasets and results, is available at: https://github.com/SvStraten/CNAPwP.
Detecting Complex Money Laundering Patterns with Incremental and Distributed Graph Modeling
Apr 01, 2026Money launderers take advantage of limitations in existing detection approaches by hiding their financial footprints in a deceitful manner. They manage this by replicating transaction patterns that the monitoring systems cannot easily distinguish. As a result, criminally gained assets are pushed into legitimate financial channels without drawing attention. Algorithms developed to monitor money flows often struggle with scale and complexity. The difficulty of identifying such activities is further intensified by the (persistent) inability of current solutions to control the excessive number of false positive signals produced by rigid, risk-based rules systems. We propose a framework called ReDiRect (REduce, DIstribute, and RECTify), specifically designed to overcome these challenges. The primary contribution of our work is a novel framing of this problem in an unsupervised setting; where a large transaction graph is fuzzily partitioned into smaller, manageable components to enable fast processing in a distributed manner. In addition, we define a refined evaluation metric that better captures the effectiveness of exposed money laundering patterns. Through comprehensive experimentation, we demonstrate that our framework achieves superior performance compared to existing and state-of-the-art techniques, particularly in terms of efficiency and real-world applicability. For validation, we used the real (open source) Libra dataset and the recently released synthetic datasets by IBM Watson. Our code and datasets are available at https://github.com/mhaseebtariq/redirect.
Enhancing Traffic Flow Prediction using Outlier-Weighted AutoEncoders: Handling Real-Time Changes
Dec 27, 2023In today's urban landscape, traffic congestion poses a critical challenge, especially during outlier scenarios. These outliers can indicate abrupt traffic peaks, drops, or irregular trends, often arising from factors such as accidents, events, or roadwork. Moreover, Given the dynamic nature of traffic, the need for real-time traffic modeling also becomes crucial to ensure accurate and up-to-date traffic predictions. To address these challenges, we introduce the Outlier Weighted Autoencoder Modeling (OWAM) framework. OWAM employs autoencoders for local outlier detection and generates correlation scores to assess neighboring traffic's influence. These scores serve as a weighted factor for neighboring sensors, before fusing them into the model. This information enhances the traffic model's performance and supports effective real-time updates, a crucial aspect for capturing dynamic traffic patterns. OWAM demonstrates a favorable trade-off between accuracy and efficiency, rendering it highly suitable for real-world applications. The research findings contribute significantly to the development of more efficient and adaptive traffic prediction models, advancing the field of transportation management for the future. The code and datasets of our framework is publicly available under https://github.com/himanshudce/OWAM.
Topology-Agnostic Detection of Temporal Money Laundering Flows in Billion-Scale Transactions
Sep 24, 2023Money launderers exploit the weaknesses in detection systems by purposefully placing their ill-gotten money into multiple accounts, at different banks. That money is then layered and moved around among mule accounts to obscure the origin and the flow of transactions. Consequently, the money is integrated into the financial system without raising suspicion. Path finding algorithms that aim at tracking suspicious flows of money usually struggle with scale and complexity. Existing community detection techniques also fail to properly capture the time-dependent relationships. This is particularly evident when performing analytics over massive transaction graphs. We propose a framework (called FaSTMAN), adapted for domain-specific constraints, to efficiently construct a temporal graph of sequential transactions. The framework includes a weighting method, using 2nd order graph representation, to quantify the significance of the edges. This method enables us to distribute complex queries on smaller and densely connected networks of flows. Finally, based on those queries, we can effectively identify networks of suspicious flows. We extensively evaluate the scalability and the effectiveness of our framework against two state-of-the-art solutions for detecting suspicious flows of transactions. For a dataset of over 1 Billion transactions from multiple large European banks, the results show a clear superiority of our framework both in efficiency and usefulness.
Clustering-based Aggregations for Prediction in Event Streams
Oct 18, 2022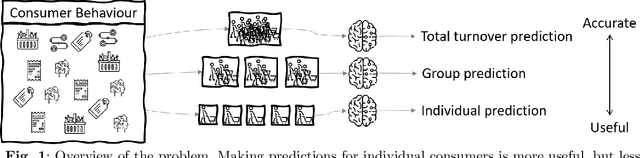
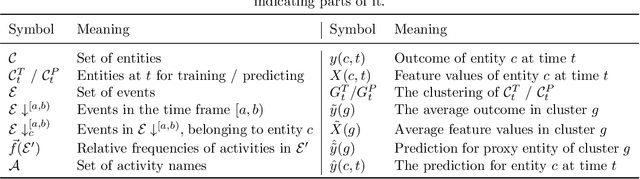
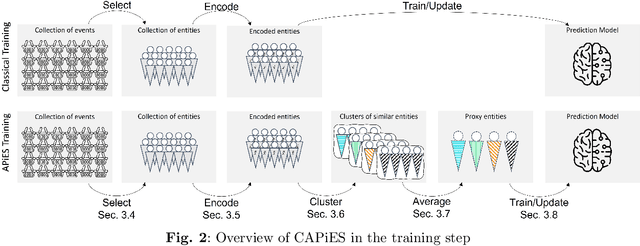

Predicting the behaviour of shoppers provides valuable information for retailers, such as the expected spend of a shopper or the total turnover of a supermarket. The ability to make predictions on an individual level is useful, as it allows supermarkets to accurately perform targeted marketing. However, given the expected number of shoppers and their diverse behaviours, making accurate predictions on an individual level is difficult. This problem does not only arise in shopper behaviour, but also in various business processes, such as predicting when an invoice will be paid. In this paper we present CAPiES, a framework that focuses on this trade-off in an online setting. By making predictions on a larger number of entities at a time, we improve the predictive accuracy but at the potential cost of usefulness since we can say less about the individual entities. CAPiES is developed in an online setting, where we continuously update the prediction model and make new predictions over time. We show the existence of the trade-off in an experimental evaluation in two real-world scenarios: a supermarket with over 160 000 shoppers and a paint factory with over 171 000 invoices.
What Averages Do Not Tell -- Predicting Real Life Processes with Sequential Deep Learning
Oct 31, 2021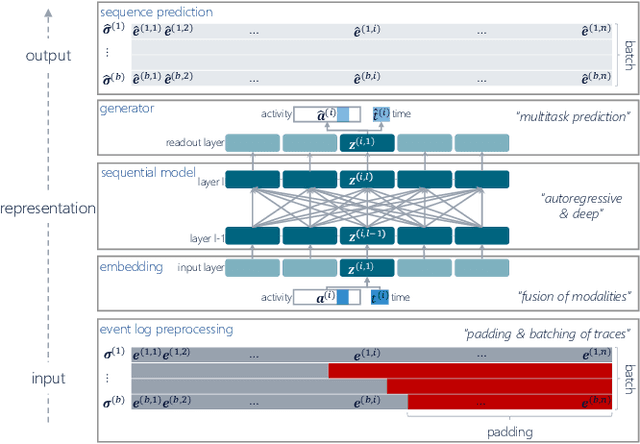
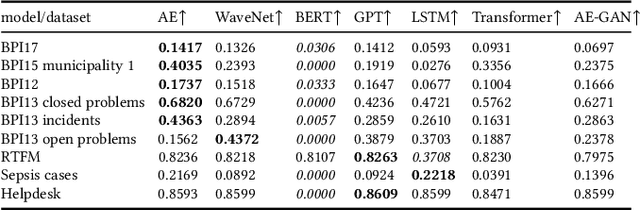
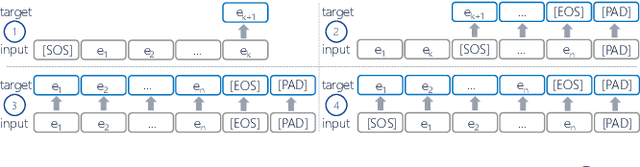
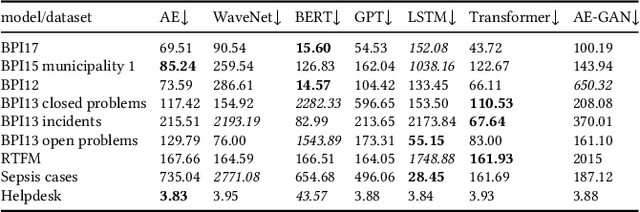
Deep Learning is proven to be an effective tool for modeling sequential data as shown by the success in Natural Language, Computer Vision and Signal Processing. Process Mining concerns discovering insights on business processes from their execution data that are logged by supporting information systems. The logged data (event log) is formed of event sequences (traces) that correspond to executions of a process. Many Deep Learning techniques have been successfully adapted for predictive Process Mining that aims to predict process outcomes, remaining time, the next event, or even the suffix of running traces. Traces in Process Mining are multimodal sequences and very differently structured than natural language sentences or images. This may require a different approach to processing. So far, there has been little focus on these differences and the challenges introduced. Looking at suffix prediction as the most challenging of these tasks, the performance of Deep Learning models was evaluated only on average measures and for a small number of real-life event logs. Comparing the results between papers is difficult due to different pre-processing and evaluation strategies. Challenges that may be relevant are the skewness of trace-length distribution and the skewness of the activity distribution in real-life event logs. We provide an end-to-end framework which enables to compare the performance of seven state-of-the-art sequential architectures in common settings. Results show that sequence modeling still has a lot of room for improvement for majority of the more complex datasets. Further research and insights are required to get consistent performance not just in average measures but additionally over all the prefixes.