 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusion-Augmented Reinforcement Learning for Robust Portfolio Optimization under Stress Scenarios
Oct 08, 2025In the ever-changing and intricate landscape of financial markets, portfolio optimisation remains a formidable challenge for investors and asset managers. Conventional methods often struggle to capture the complex dynamics of market behaviour and align with diverse investor preferences. To address this, we propose an innovative framework, termed Diffusion-Augmented Reinforcement Learning (DARL), which synergistically integrates Denoising Diffusion Probabilistic Models (DDPMs) with Deep Reinforcement Learning (DRL) for portfolio management. By leveraging DDPMs to generate synthetic market crash scenarios conditioned on varying stress intensities, our approach significantly enhances the robustness of training data. Empirical evaluations demonstrate that DARL outperforms traditional baselines, delivering superior risk-adjusted returns and resilience against unforeseen crises, such as the 2025 Tariff Crisis. This work offers a robust and practical methodology to bolster stress resilience in DRL-driven financial applications.
Enhancing Traffic Flow Prediction using Outlier-Weighted AutoEncoders: Handling Real-Time Changes
Dec 27, 2023In today's urban landscape, traffic congestion poses a critical challenge, especially during outlier scenarios. These outliers can indicate abrupt traffic peaks, drops, or irregular trends, often arising from factors such as accidents, events, or roadwork. Moreover, Given the dynamic nature of traffic, the need for real-time traffic modeling also becomes crucial to ensure accurate and up-to-date traffic predictions. To address these challenges, we introduce the Outlier Weighted Autoencoder Modeling (OWAM) framework. OWAM employs autoencoders for local outlier detection and generates correlation scores to assess neighboring traffic's influence. These scores serve as a weighted factor for neighboring sensors, before fusing them into the model. This information enhances the traffic model's performance and supports effective real-time updates, a crucial aspect for capturing dynamic traffic patterns. OWAM demonstrates a favorable trade-off between accuracy and efficiency, rendering it highly suitable for real-world applications. The research findings contribute significantly to the development of more efficient and adaptive traffic prediction models, advancing the field of transportation management for the future. The code and datasets of our framework is publicly available under https://github.com/himanshudce/OWAM.
FairGen: Fair Synthetic Data Generation
Oct 24, 2022With the rising adoption of Machine Learning across the domains like banking, pharmaceutical, ed-tech, etc, it has become utmost important to adopt responsible AI methods to ensure models are not unfairly discriminating against any group. Given the lack of clean training data, generative adversarial techniques are preferred to generate synthetic data with several state-of-the-art architectures readily available across various domains from unstructured data such as text, images to structured datasets modelling fraud detection and many more. These techniques overcome several challenges such as class imbalance, limited training data, restricted access to data due to privacy issues. Existing work focusing on generating fair data either works for a certain GAN architecture or is very difficult to tune across the GANs. In this paper, we propose a pipeline to generate fairer synthetic data independent of the GAN architecture. The proposed paper utilizes a pre-processing algorithm to identify and remove bias inducing samples. In particular, we claim that while generating synthetic data most GANs amplify bias present in the training data but by removing these bias inducing samples, GANs essentially focuses more on real informative samples. Our experimental evaluation on two open-source datasets demonstrates how the proposed pipeline is generating fair data along with improved performance in some cases.
How Low is Too Low? A Computational Perspective on Extremely Low-Resource Languages
May 30, 2021
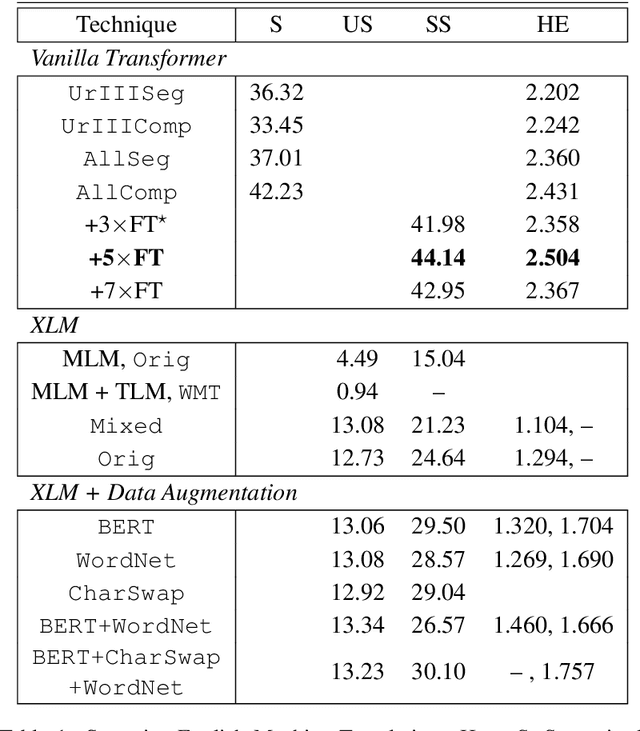
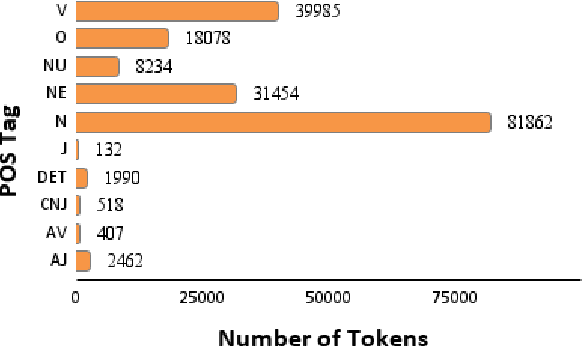
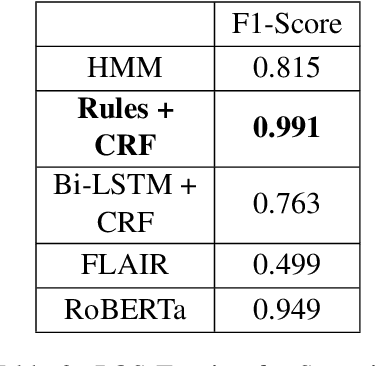
Despite the recent advancements of attention-based deep learning architectures across a majority of Natural Language Processing tasks, their application remains limited in a low-resource setting because of a lack of pre-trained models for such languages. In this study, we make the first attempt to investigate the challenges of adapting these techniques for an extremely low-resource language -- Sumerian cuneiform -- one of the world's oldest written languages attested from at least the beginning of the 3rd millennium BC. Specifically, we introduce the first cross-lingual information extraction pipeline for Sumerian, which includes part-of-speech tagging, named entity recognition, and machine translation. We further curate InterpretLR, an interpretability toolkit for low-resource NLP, and use it alongside human attributions to make sense of the models. We emphasize on human evaluations to gauge all our techniques. Notably, most components of our pipeline can be generalised to any other language to obtain an interpretable execution of the techniques, especially in a low-resource setting. We publicly release all software, model checkpoints, and a novel dataset with domain-specific pre-processing to promote further research.
Neural Machine Translation for Low-Resourced Indian Languages
Apr 19, 2020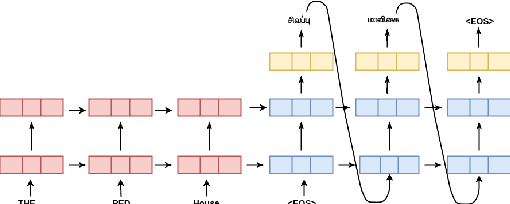
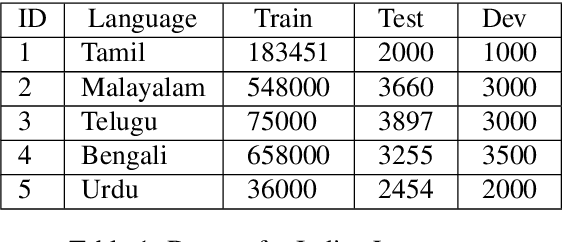
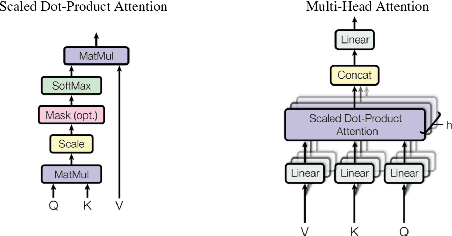

A large number of significant assets are available online in English, which is frequently translated into native languages to ease the information sharing among local people who are not much familiar with English. However, manual translation is a very tedious, costly, and time-taking process. To this end, machine translation is an effective approach to convert text to a different language without any human involvement. Neural machine translation (NMT) is one of the most proficient translation techniques amongst all existing machine translation systems. In this paper, we have applied NMT on two of the most morphological rich Indian languages, i.e. English-Tamil and English-Malayalam. We proposed a novel NMT model using Multihead self-attention along with pre-trained Byte-Pair-Encoded (BPE) and MultiBPE embeddings to develop an efficient translation system that overcomes the OOV (Out Of Vocabulary) problem for low resourced morphological rich Indian languages which do not have much translation available online. We also collected corpus from different sources, addressed the issues with these publicly available data and refined them for further uses. We used the BLEU score for evaluating our system performance. Experimental results and survey confirmed that our proposed translator (24.34 and 9.78 BLEU score) outperforms Google translator (9.40 and 5.94 BLEU score) respectively.
Low Cost Autonomous Navigation and Control of a Mechanically Balanced Bicycle with Dual Locomotion Mode
Nov 01, 2016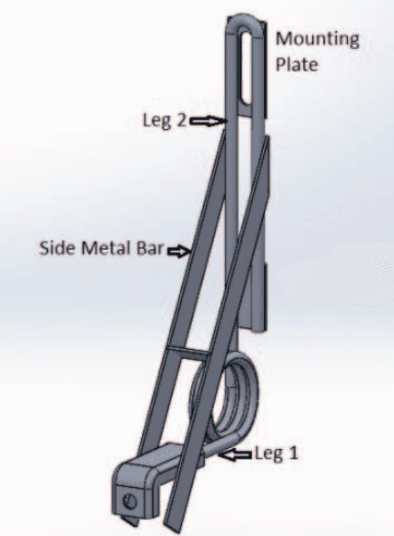
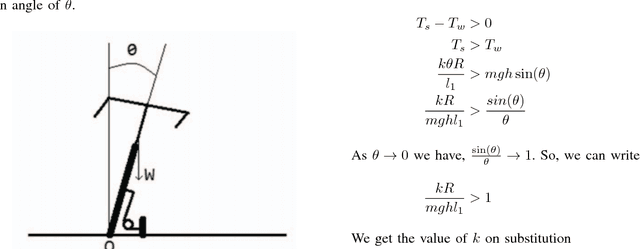
On the lines of the huge and varied efforts in the field of automation with respect to technology development and innovation of vehicles to make them run autonomously, this paper presents an innovation to a bicycle. A normal daily use bicycle was modified at low cost such that it runs autonomously, while maintaining its original form i.e. the manual drive. Hence, a bicycle which could be normally driven by any human and with a press of switch could run autonomously according to the needs of the user has been developed.
* Published in the International Transportation Electrification Conference (ITEC) in 2015 organized by IEEE Industrial Application Society (IAS) and SAE India in Chennai, India