 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSaCoFa: Semantics-aware Control-flow Anonymization for Process Mining
Sep 17, 2021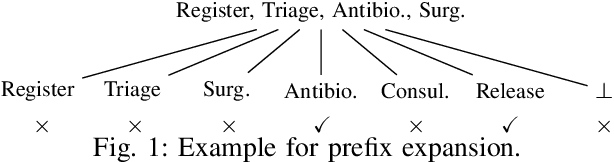
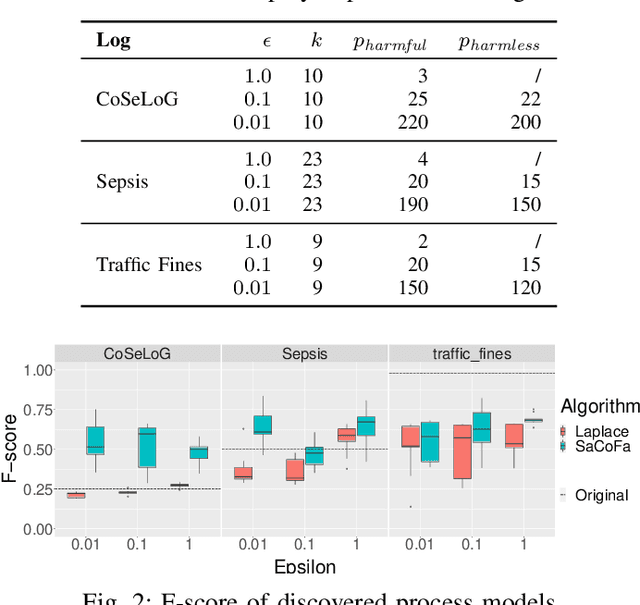
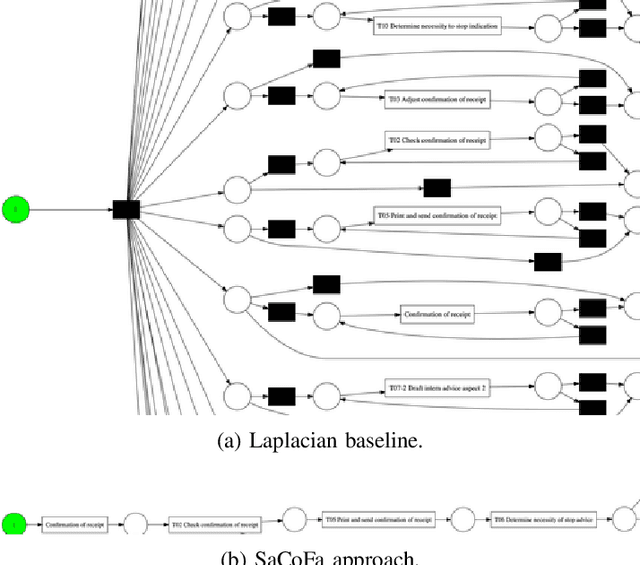
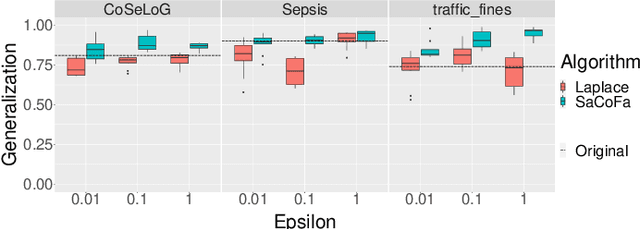
Privacy-preserving process mining enables the analysis of business processes using event logs, while giving guarantees on the protection of sensitive information on process stakeholders. To this end, existing approaches add noise to the results of queries that extract properties of an event log, such as the frequency distribution of trace variants, for analysis.Noise insertion neglects the semantics of the process, though, and may generate traces not present in the original log. This is problematic. It lowers the utility of the published data and makes noise easily identifiable, as some traces will violate well-known semantic constraints.In this paper, we therefore argue for privacy preservation that incorporates a process semantics. For common trace-variant queries, we show how, based on the exponential mechanism, semantic constraints are incorporated to ensure differential privacy of the query result. Experiments demonstrate that our semantics-aware anonymization yields event logs of significantly higher utility than existing approaches.
A Distance Measure for Privacy-preserving Process Mining based on Feature Learning
Aug 10, 2021
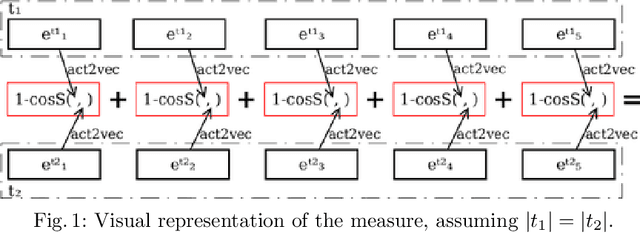
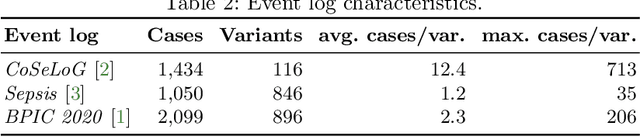
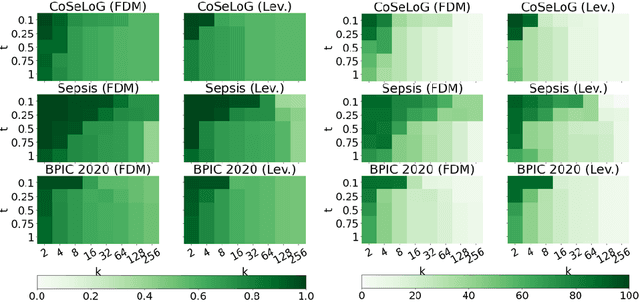
To enable process analysis based on an event log without compromising the privacy of individuals involved in process execution, a log may be anonymized. Such anonymization strives to transform a log so that it satisfies provable privacy guarantees, while largely maintaining its utility for process analysis. Existing techniques perform anonymization using simple, syntactic measures to identify suitable transformation operations. This way, the semantics of the activities referenced by the events in a trace are neglected, potentially leading to transformations in which events of unrelated activities are merged. To avoid this and incorporate the semantics of activities during anonymization, we propose to instead incorporate a distance measure based on feature learning. Specifically, we show how embeddings of events enable the definition of a distance measure for traces to guide event log anonymization. Our experiments with real-world data indicate that anonymization using this measure, compared to a syntactic one, yields logs that are closer to the original log in various dimensions and, hence, have higher utility for process analysis.