 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel-Agnostic and Diverse Explanations for Streaming Rumour Graphs
Paper and Code
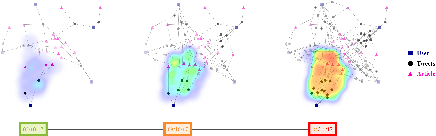

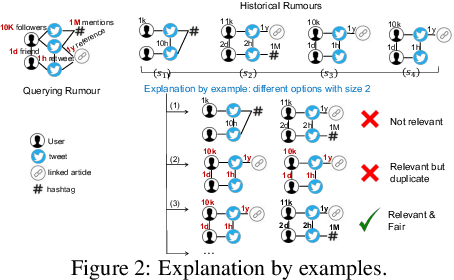
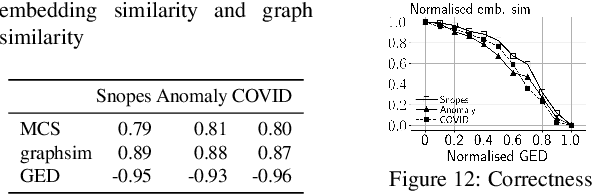
The propagation of rumours on social media poses an important threat to societies, so that various techniques for rumour detection have been proposed recently. Yet, existing work focuses on \emph{what} entities constitute a rumour, but provides little support to understand \emph{why} the entities have been classified as such. This prevents an effective evaluation of the detected rumours as well as the design of countermeasures. In this work, we argue that explanations for detected rumours may be given in terms of examples of related rumours detected in the past. A diverse set of similar rumours helps users to generalize, i.e., to understand the properties that govern the detection of rumours. Since the spread of rumours in social media is commonly modelled using feature-annotated graphs, we propose a query-by-example approach that, given a rumour graph, extracts the $k$ most similar and diverse subgraphs from past rumours. The challenge is that all of the computations require fast assessment of similarities between graphs. To achieve an efficient and adaptive realization of the approach in a streaming setting, we present a novel graph representation learning technique and report on implementation considerations. Our evaluation experiments show that our approach outperforms baseline techniques in delivering meaningful explanations for various rumour propagation behaviours.