 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAction Selection Learning for Multi-label Multi-view Action Recognition
Paper and Code
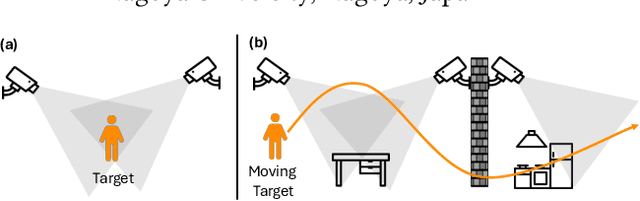
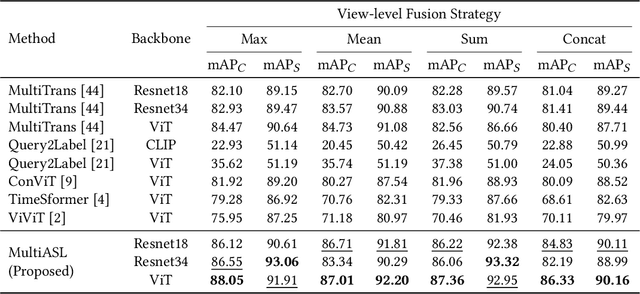
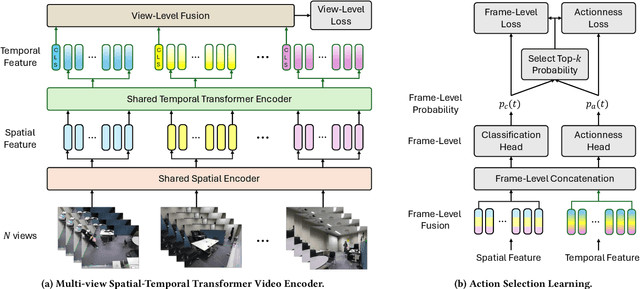

Multi-label multi-view action recognition aims to recognize multiple concurrent or sequential actions from untrimmed videos captured by multiple cameras. Existing work has focused on multi-view action recognition in a narrow area with strong labels available, where the onset and offset of each action are labeled at the frame-level. This study focuses on real-world scenarios where cameras are distributed to capture a wide-range area with only weak labels available at the video-level. We propose the method named MultiASL (Multi-view Action Selection Learning), which leverages action selection learning to enhance view fusion by selecting the most useful information from different viewpoints. The proposed method includes a Multi-view Spatial-Temporal Transformer video encoder to extract spatial and temporal features from multi-viewpoint videos. Action Selection Learning is employed at the frame-level, using pseudo ground-truth obtained from weak labels at the video-level, to identify the most relevant frames for action recognition. Experiments in a real-world office environment using the MM-Office dataset demonstrate the superior performance of the proposed method compared to existing methods.