 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeManifoldNeRF: View-dependent Image Feature Supervision for Few-shot Neural Radiance Fields
Oct 20, 2023



Novel view synthesis has recently made significant progress with the advent of Neural Radiance Fields (NeRF). DietNeRF is an extension of NeRF that aims to achieve this task from only a few images by introducing a new loss function for unknown viewpoints with no input images. The loss function assumes that a pre-trained feature extractor should output the same feature even if input images are captured at different viewpoints since the images contain the same object. However, while that assumption is ideal, in reality, it is known that as viewpoints continuously change, also feature vectors continuously change. Thus, the assumption can harm training. To avoid this harmful training, we propose ManifoldNeRF, a method for supervising feature vectors at unknown viewpoints using interpolated features from neighboring known viewpoints. Since the method provides appropriate supervision for each unknown viewpoint by the interpolated features, the volume representation is learned better than DietNeRF. Experimental results show that the proposed method performs better than others in a complex scene. We also experimented with several subsets of viewpoints from a set of viewpoints and identified an effective set of viewpoints for real environments. This provided a basic policy of viewpoint patterns for real-world application. The code is available at https://github.com/haganelego/ManifoldNeRF_BMVC2023
Dehazing Cost Volume for Deep Multi-view Stereo in Scattering Media with Airlight and Scattering Coefficient Estimation
Dec 02, 2020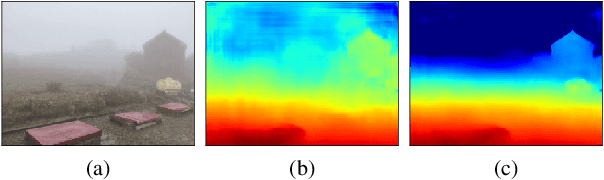
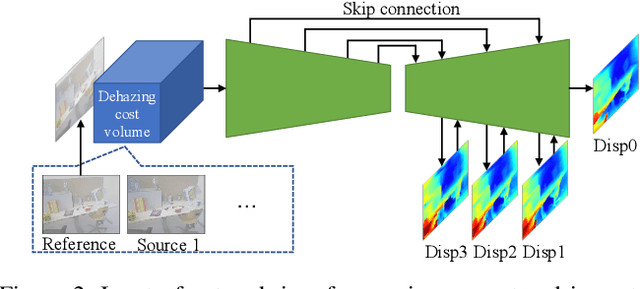
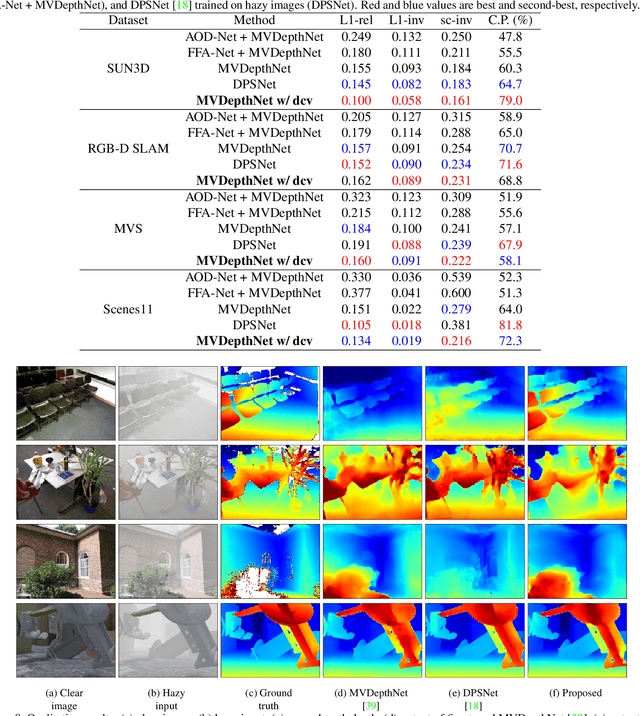
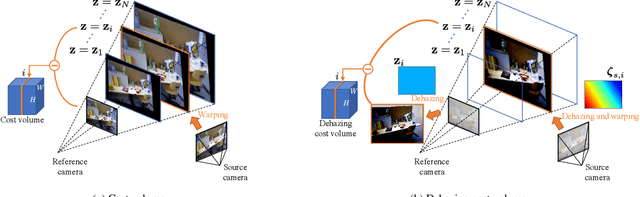
We propose a learning-based multi-view stereo (MVS) method in scattering media, such as fog or smoke, with a novel cost volume, called the dehazing cost volume. Images captured in scattering media are degraded due to light scattering and attenuation caused by suspended particles. This degradation depends on scene depth; thus, it is difficult for traditional MVS methods to evaluate photometric consistency because the depth is unknown before three-dimensional (3D) reconstruction. The dehazing cost volume can solve this chicken-and-egg problem of depth estimation and image restoration by computing the scattering effect using swept planes in the cost volume. We also propose a method of estimating scattering parameters, such as airlight, and a scattering coefficient, which are required for our dehazing cost volume. The output depth of a network with our dehazing cost volume can be regarded as a function of these parameters; thus, they are geometrically optimized with a sparse 3D point cloud obtained at a structure-from-motion step. Experimental results on synthesized hazy images indicate the effectiveness of our dehazing cost volume against the ordinary cost volume regarding scattering media. We also demonstrated the applicability of our dehazing cost volume to real foggy scenes.
Partially-Shared Variational Auto-encoders for Unsupervised Domain Adaptation with Target Shift
Jan 25, 2020



This paper proposes a novel approach for unsupervised domain adaptation (UDA) with target shift. Target shift is a problem of mismatch in label distribution between source and target domains. Typically it appears as class-imbalance in target domain. In practice, this is an important problem in UDA; as we do not know labels in target domain datasets, we do not know whether or not its distribution is identical to that in the source domain dataset. Many traditional approaches achieve UDA with distribution matching by minimizing mean maximum discrepancy or adversarial training; however these approaches implicitly assume a coincidence in the distributions and do not work under situations with target shift. Some recent UDA approaches focus on class boundary and some of them are robust to target shift, but they are only applicable to classification and not to regression. To overcome the target shift problem in UDA, the proposed method, partially shared variational autoencoders (PS-VAEs), uses pair-wise feature alignment instead of feature distribution matching. PS-VAEs inter-convert domain of each sample by a CycleGAN-based architecture while preserving its label-related content. To evaluate the performance of PS-VAEs, we carried out two experiments: UDA with class-unbalanced digits datasets (classification), and UDA from synthesized data to real observation in human-pose-estimation (regression). The proposed method presented its robustness against the class-imbalance in the classification task, and outperformed the other methods in the regression task with a large margin.
Defogging Kinect: Simultaneous Estimation of Object Region and Depth in Foggy Scenes
Apr 01, 2019


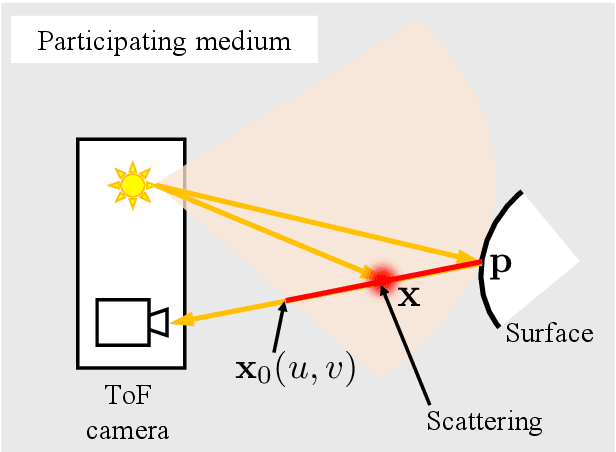
Three-dimensional (3D) reconstruction and scene depth estimation from 2-dimensional (2D) images are major tasks in computer vision. However, using conventional 3D reconstruction techniques gets challenging in participating media such as murky water, fog, or smoke. We have developed a method that uses a time-of-flight (ToF) camera to estimate an object region and depth in participating media simultaneously. The scattering component is saturated, so it does not depend on the scene depth, and received signals bouncing off distant points are negligible due to light attenuation in the participating media, so the observation of such a point contains only a scattering component. These phenomena enable us to estimate the scattering component in an object region from a background that only contains the scattering component. The problem is formulated as robust estimation where the object region is regarded as outliers, and it enables the simultaneous estimation of an object region and depth on the basis of an iteratively reweighted least squares (IRLS) optimization scheme. We demonstrate the effectiveness of the proposed method using captured images from a Kinect v2 in real foggy scenes and evaluate the applicability with synthesized data.