 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUFV-Splatter: Pose-Free Feed-Forward 3D Gaussian Splatting Adapted to Unfavorable Views
Jul 30, 2025This paper presents a pose-free, feed-forward 3D Gaussian Splatting (3DGS) framework designed to handle unfavorable input views. A common rendering setup for training feed-forward approaches places a 3D object at the world origin and renders it from cameras pointed toward the origin -- i.e., from favorable views, limiting the applicability of these models to real-world scenarios involving varying and unknown camera poses. To overcome this limitation, we introduce a novel adaptation framework that enables pretrained pose-free feed-forward 3DGS models to handle unfavorable views. We leverage priors learned from favorable images by feeding recentered images into a pretrained model augmented with low-rank adaptation (LoRA) layers. We further propose a Gaussian adapter module to enhance the geometric consistency of the Gaussians derived from the recentered inputs, along with a Gaussian alignment method to render accurate target views for training. Additionally, we introduce a new training strategy that utilizes an off-the-shelf dataset composed solely of favorable images. Experimental results on both synthetic images from the Google Scanned Objects dataset and real images from the OmniObject3D dataset validate the effectiveness of our method in handling unfavorable input views.
NLOS-NeuS: Non-line-of-sight Neural Implicit Surface
Mar 22, 2023



Non-line-of-sight (NLOS) imaging is conducted to infer invisible scenes from indirect light on visible objects. The neural transient field (NeTF) was proposed for representing scenes as neural radiance fields in NLOS scenes. We propose NLOS neural implicit surface (NLOS-NeuS), which extends the NeTF to neural implicit surfaces with a signed distance function (SDF) for reconstructing three-dimensional surfaces in NLOS scenes. We introduce two constraints as loss functions for correctly learning an SDF to avoid non-zero level-set surfaces. We also introduce a lower bound constraint of an SDF based on the geometry of the first-returning photons. The experimental results indicate that these constraints are essential for learning a correct SDF in NLOS scenes. Compared with previous methods with discretized representation, NLOS-NeuS with the neural continuous representation enables us to reconstruct smooth surfaces while preserving fine details in NLOS scenes. To the best of our knowledge, this is the first study on neural implicit surfaces with volume rendering in NLOS scenes.
Deep Depth from Focal Stack with Defocus Model for Camera-Setting Invariance
Feb 26, 2022



We propose a learning-based depth from focus/defocus (DFF), which takes a focal stack as input for estimating scene depth. Defocus blur is a useful cue for depth estimation. However, the size of the blur depends on not only scene depth but also camera settings such as focus distance, focal length, and f-number. Current learning-based methods without any defocus models cannot estimate a correct depth map if camera settings are different at training and test times. Our method takes a plane sweep volume as input for the constraint between scene depth, defocus images, and camera settings, and this intermediate representation enables depth estimation with different camera settings at training and test times. This camera-setting invariance can enhance the applicability of learning-based DFF methods. The experimental results also indicate that our method is robust against a synthetic-to-real domain gap, and exhibits state-of-the-art performance.
Dehazing Cost Volume for Deep Multi-view Stereo in Scattering Media with Airlight and Scattering Coefficient Estimation
Dec 02, 2020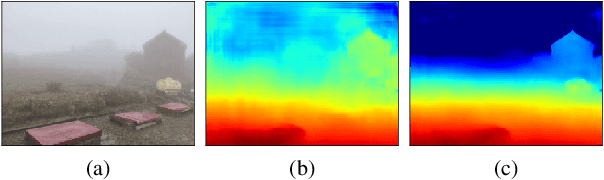
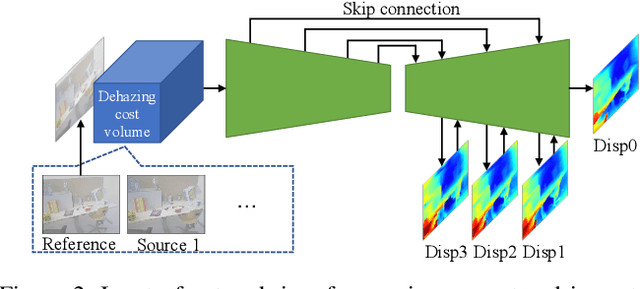
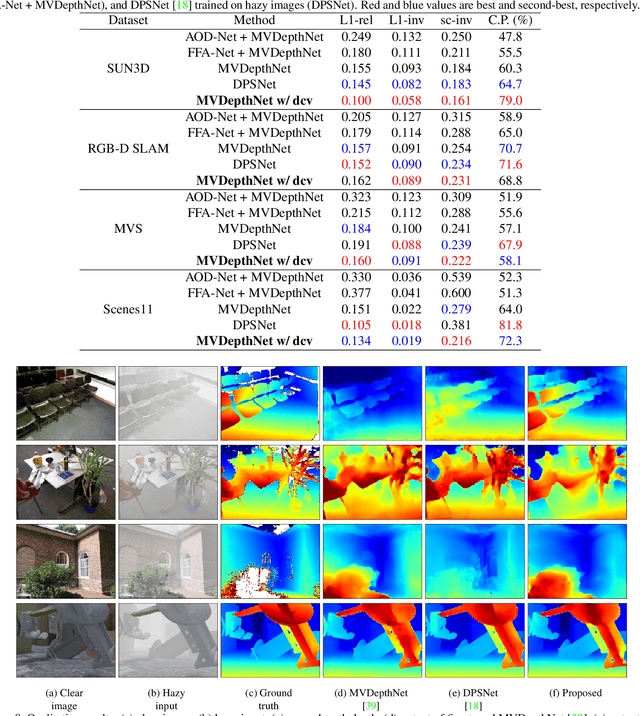
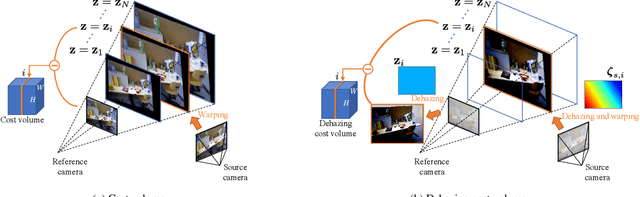
We propose a learning-based multi-view stereo (MVS) method in scattering media, such as fog or smoke, with a novel cost volume, called the dehazing cost volume. Images captured in scattering media are degraded due to light scattering and attenuation caused by suspended particles. This degradation depends on scene depth; thus, it is difficult for traditional MVS methods to evaluate photometric consistency because the depth is unknown before three-dimensional (3D) reconstruction. The dehazing cost volume can solve this chicken-and-egg problem of depth estimation and image restoration by computing the scattering effect using swept planes in the cost volume. We also propose a method of estimating scattering parameters, such as airlight, and a scattering coefficient, which are required for our dehazing cost volume. The output depth of a network with our dehazing cost volume can be regarded as a function of these parameters; thus, they are geometrically optimized with a sparse 3D point cloud obtained at a structure-from-motion step. Experimental results on synthesized hazy images indicate the effectiveness of our dehazing cost volume against the ordinary cost volume regarding scattering media. We also demonstrated the applicability of our dehazing cost volume to real foggy scenes.
Defogging Kinect: Simultaneous Estimation of Object Region and Depth in Foggy Scenes
Apr 01, 2019


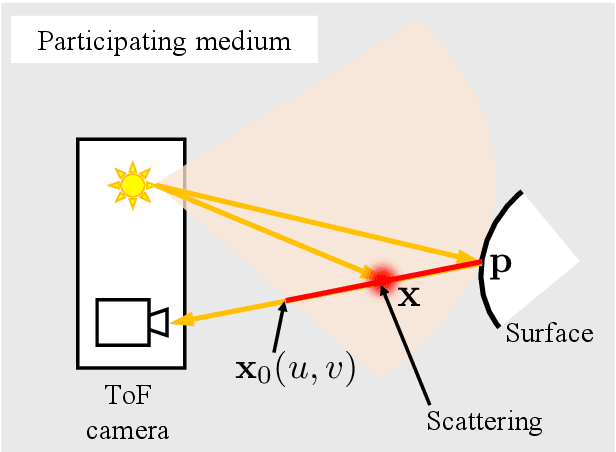
Three-dimensional (3D) reconstruction and scene depth estimation from 2-dimensional (2D) images are major tasks in computer vision. However, using conventional 3D reconstruction techniques gets challenging in participating media such as murky water, fog, or smoke. We have developed a method that uses a time-of-flight (ToF) camera to estimate an object region and depth in participating media simultaneously. The scattering component is saturated, so it does not depend on the scene depth, and received signals bouncing off distant points are negligible due to light attenuation in the participating media, so the observation of such a point contains only a scattering component. These phenomena enable us to estimate the scattering component in an object region from a background that only contains the scattering component. The problem is formulated as robust estimation where the object region is regarded as outliers, and it enables the simultaneous estimation of an object region and depth on the basis of an iteratively reweighted least squares (IRLS) optimization scheme. We demonstrate the effectiveness of the proposed method using captured images from a Kinect v2 in real foggy scenes and evaluate the applicability with synthesized data.
Photometric Stereo in Participating Media Considering Shape-Dependent Forward Scatter
Apr 10, 2018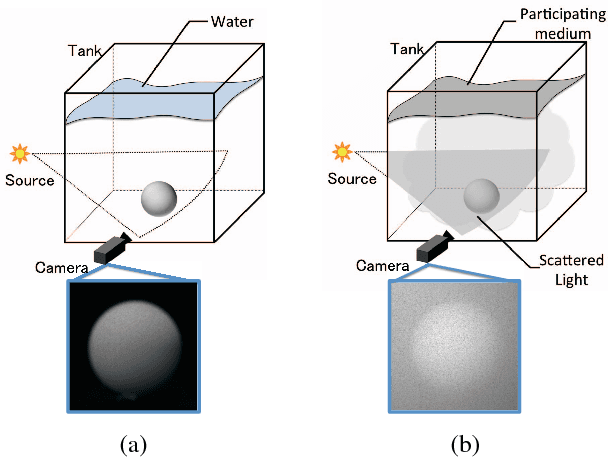

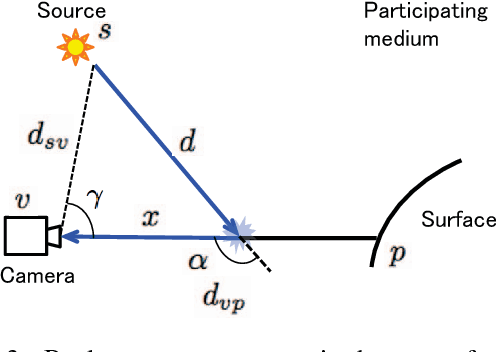
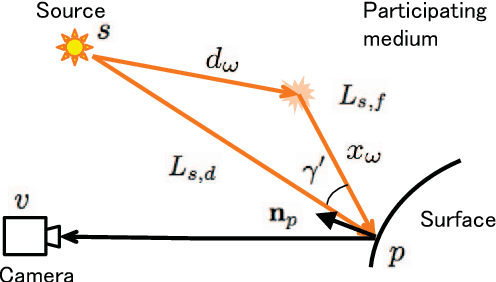
Images captured in participating media such as murky water, fog, or smoke are degraded by scattered light. Thus, the use of traditional three-dimensional (3D) reconstruction techniques in such environments is difficult. In this paper, we propose a photometric stereo method for participating media. The proposed method differs from previous studies with respect to modeling shape-dependent forward scatter. In the proposed model, forward scatter is described as an analytical form using lookup tables and is represented by spatially-variant kernels. We also propose an approximation of a large-scale dense matrix as a sparse matrix, which enables the removal of forward scatter. Experiments with real and synthesized data demonstrate that the proposed method improves 3D reconstruction in participating media.