 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhotometric Stereo in Participating Media Considering Shape-Dependent Forward Scatter
Apr 10, 2018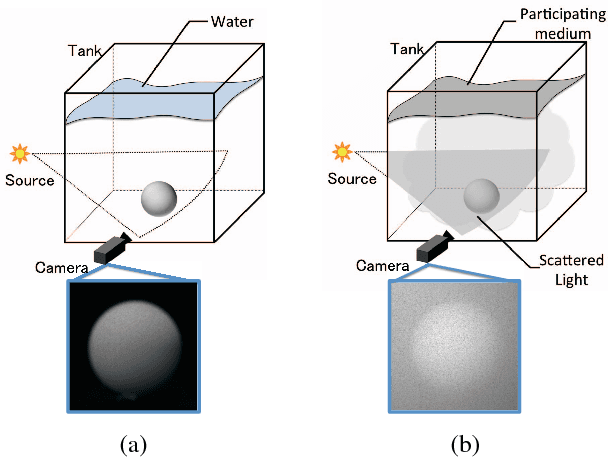

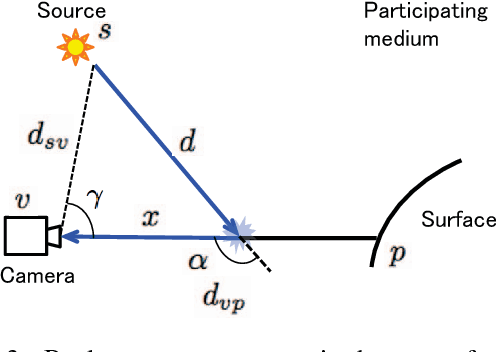
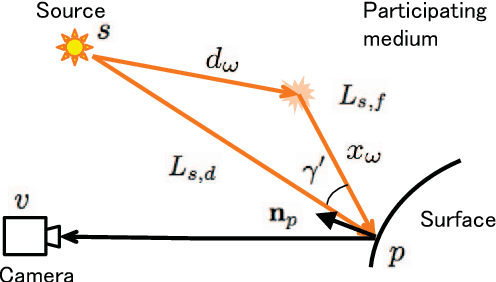
Images captured in participating media such as murky water, fog, or smoke are degraded by scattered light. Thus, the use of traditional three-dimensional (3D) reconstruction techniques in such environments is difficult. In this paper, we propose a photometric stereo method for participating media. The proposed method differs from previous studies with respect to modeling shape-dependent forward scatter. In the proposed model, forward scatter is described as an analytical form using lookup tables and is represented by spatially-variant kernels. We also propose an approximation of a large-scale dense matrix as a sparse matrix, which enables the removal of forward scatter. Experiments with real and synthesized data demonstrate that the proposed method improves 3D reconstruction in participating media.
Outlier Cluster Formation in Spectral Clustering
Mar 03, 2017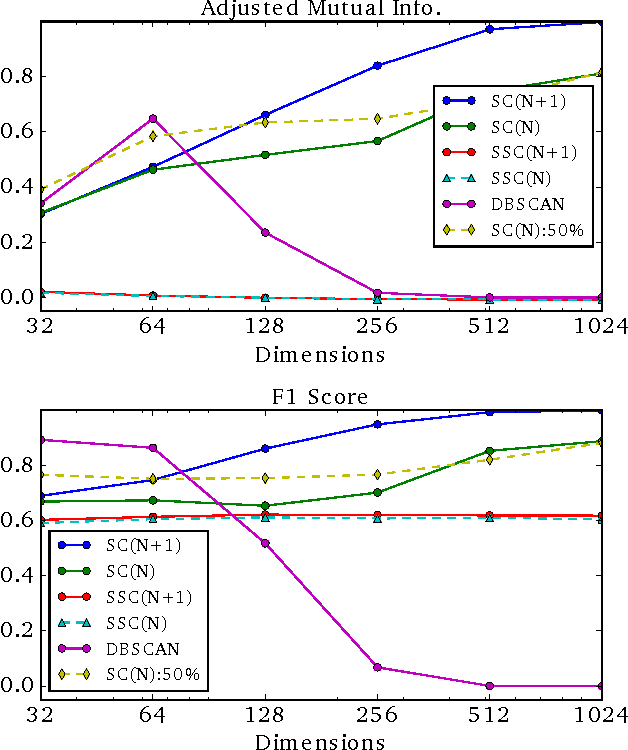
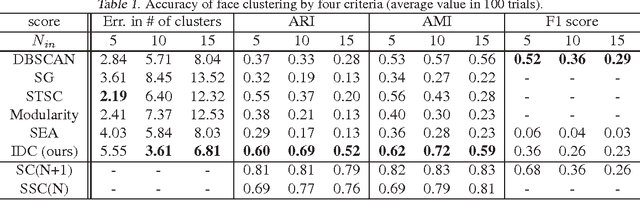
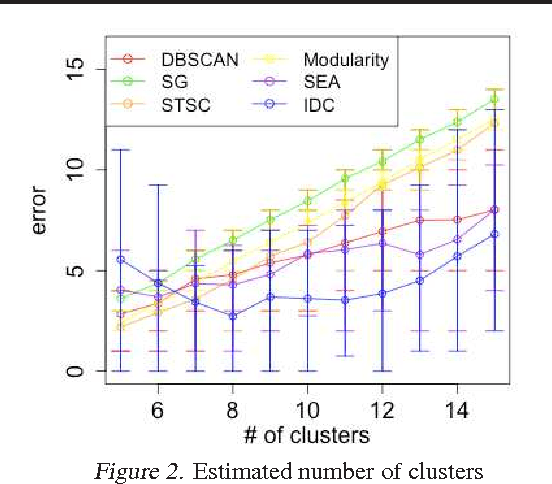
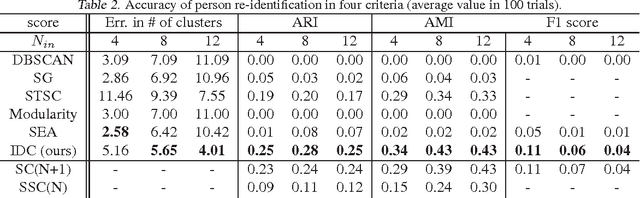
Outlier detection and cluster number estimation is an important issue for clustering real data. This paper focuses on spectral clustering, a time-tested clustering method, and reveals its important properties related to outliers. The highlights of this paper are the following two mathematical observations: first, spectral clustering's intrinsic property of an outlier cluster formation, and second, the singularity of an outlier cluster with a valid cluster number. Based on these observations, we designed a function that evaluates clustering and outlier detection results. In experiments, we prepared two scenarios, face clustering in photo album and person re-identification in a camera network. We confirmed that the proposed method detects outliers and estimates the number of clusters properly in both problems. Our method outperforms state-of-the-art methods in both the 128-dimensional sparse space for face clustering and the 4,096-dimensional non-sparse space for person re-identification.
Collaborative Representation for Classification, Sparse or Non-sparse?
Mar 06, 2014
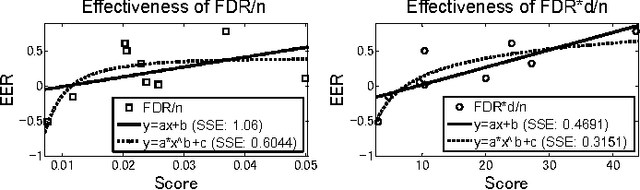
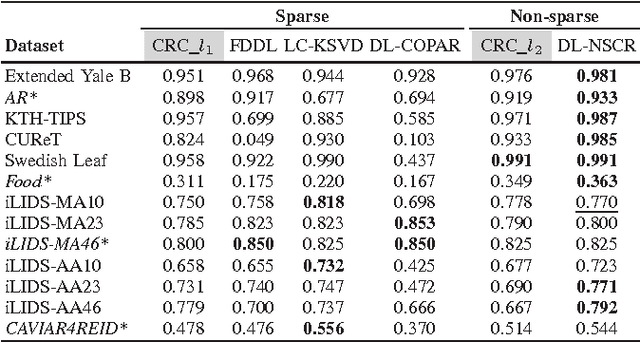

Sparse representation based classification (SRC) has been proved to be a simple, effective and robust solution to face recognition. As it gets popular, doubts on the necessity of enforcing sparsity starts coming up, and primary experimental results showed that simply changing the $l_1$-norm based regularization to the computationally much more efficient $l_2$-norm based non-sparse version would lead to a similar or even better performance. However, that's not always the case. Given a new classification task, it's still unclear which regularization strategy (i.e., making the coefficients sparse or non-sparse) is a better choice without trying both for comparison. In this paper, we present as far as we know the first study on solving this issue, based on plenty of diverse classification experiments. We propose a scoring function for pre-selecting the regularization strategy using only the dataset size, the feature dimensionality and a discrimination score derived from a given feature representation. Moreover, we show that when dictionary learning is taking into account, non-sparse representation has a more significant superiority to sparse representation. This work is expected to enrich our understanding of sparse/non-sparse collaborative representation for classification and motivate further research activities.
Communication of Social Agents and the Digital City - A Semiotic Perspective
May 25, 2006
This paper investigates the concept of digital city. First, a functional analysis of a digital city is made in the light of the modern study of urbanism; similarities between the virtual and urban constructions are pointed out. Next, a semiotic perspective on the subject matter is elaborated, and a terminological basis is introduced to treat a digital city as a self-organizing meaning-producing system intended to support social or spatial navigation. An explicit definition of a digital city is formulated. Finally, the proposed approach is discussed, conclusions are given, and future work is outlined.
* 15 pages, 1 figure. Preprint completed in 2001. An earlier version of the paper was presented at the Second Kyoto Workshop on Digital Cities, Kyoto, Japan in 2001