 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCollaborative Representation for Classification, Sparse or Non-sparse?
Mar 06, 2014
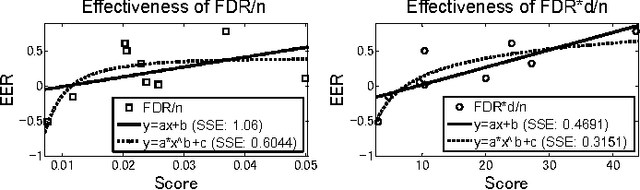
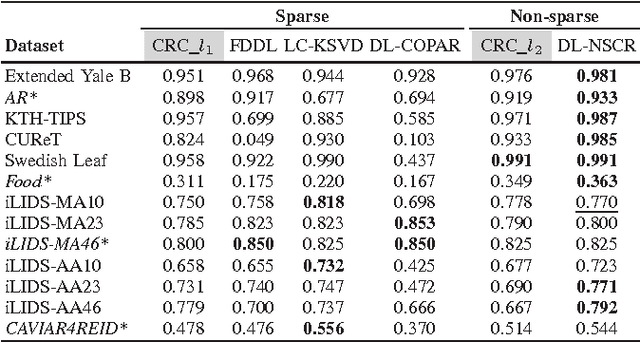

Sparse representation based classification (SRC) has been proved to be a simple, effective and robust solution to face recognition. As it gets popular, doubts on the necessity of enforcing sparsity starts coming up, and primary experimental results showed that simply changing the $l_1$-norm based regularization to the computationally much more efficient $l_2$-norm based non-sparse version would lead to a similar or even better performance. However, that's not always the case. Given a new classification task, it's still unclear which regularization strategy (i.e., making the coefficients sparse or non-sparse) is a better choice without trying both for comparison. In this paper, we present as far as we know the first study on solving this issue, based on plenty of diverse classification experiments. We propose a scoring function for pre-selecting the regularization strategy using only the dataset size, the feature dimensionality and a discrimination score derived from a given feature representation. Moreover, we show that when dictionary learning is taking into account, non-sparse representation has a more significant superiority to sparse representation. This work is expected to enrich our understanding of sparse/non-sparse collaborative representation for classification and motivate further research activities.