 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobot Motion Planning using One-Step Diffusion with Noise-Optimized Approximate Motions
Apr 28, 2025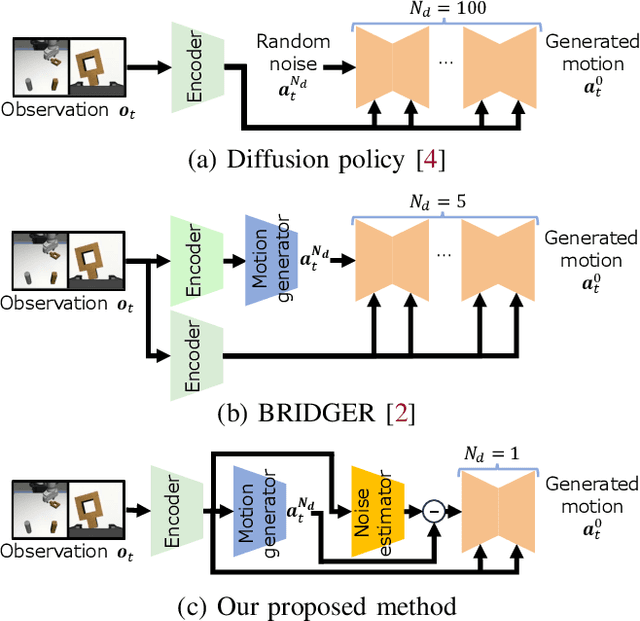
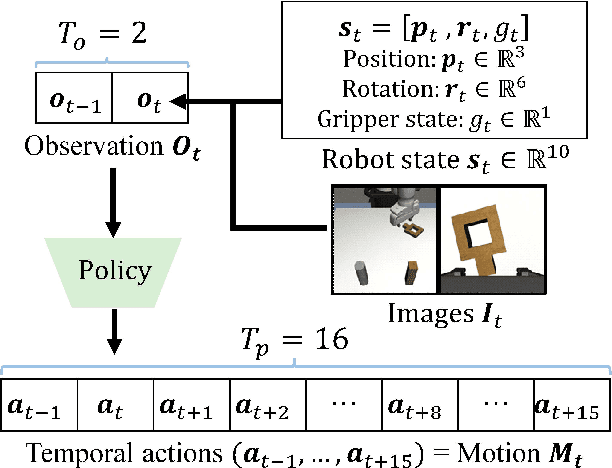
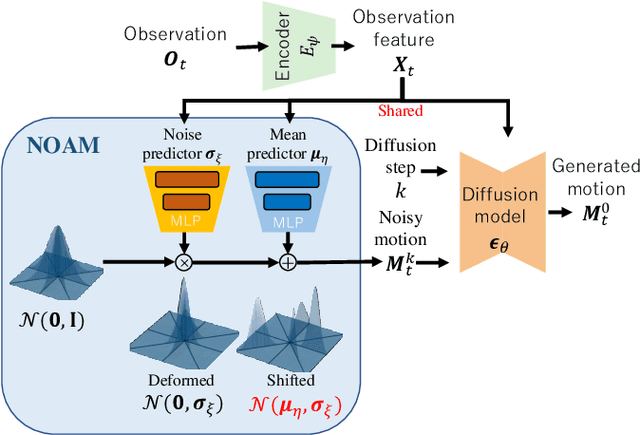
This paper proposes an image-based robot motion planning method using a one-step diffusion model. While the diffusion model allows for high-quality motion generation, its computational cost is too expensive to control a robot in real time. To achieve high quality and efficiency simultaneously, our one-step diffusion model takes an approximately generated motion, which is predicted directly from input images. This approximate motion is optimized by additive noise provided by our novel noise optimizer. Unlike general isotropic noise, our noise optimizer adjusts noise anisotropically depending on the uncertainty of each motion element. Our experimental results demonstrate that our method outperforms state-of-the-art methods while maintaining its efficiency by one-step diffusion.
Physical Plausibility-aware Trajectory Prediction via Locomotion Embodiment
Mar 21, 2025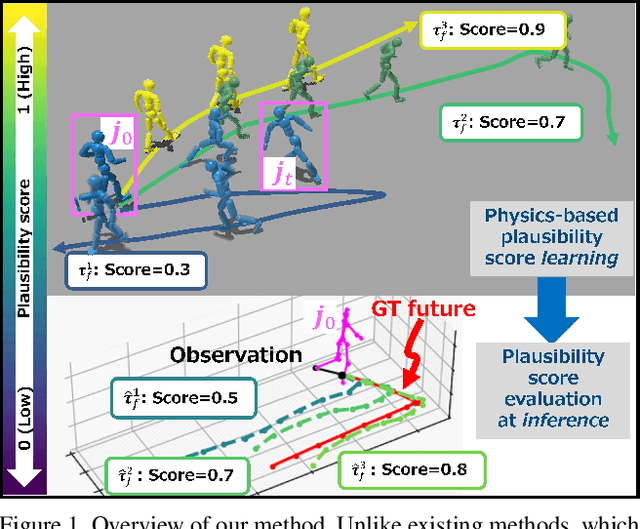
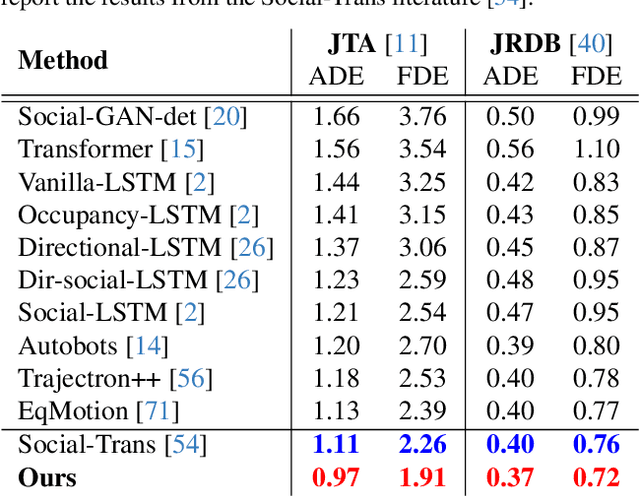
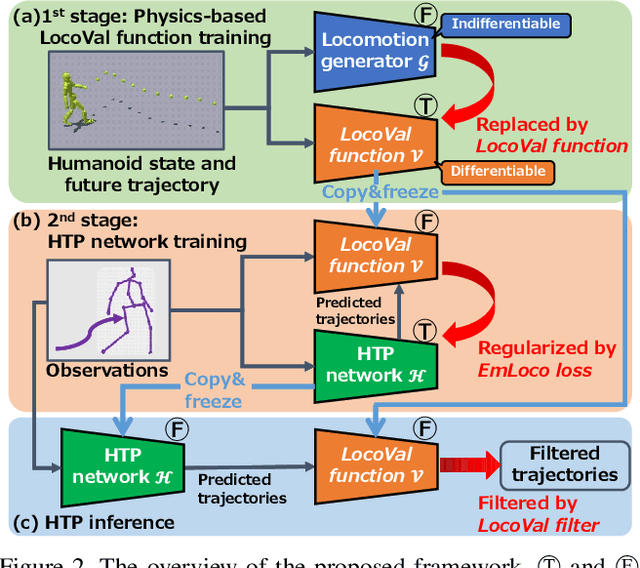

Humans can predict future human trajectories even from momentary observations by using human pose-related cues. However, previous Human Trajectory Prediction (HTP) methods leverage the pose cues implicitly, resulting in implausible predictions. To address this, we propose Locomotion Embodiment, a framework that explicitly evaluates the physical plausibility of the predicted trajectory by locomotion generation under the laws of physics. While the plausibility of locomotion is learned with an indifferentiable physics simulator, it is replaced by our differentiable Locomotion Value function to train an HTP network in a data-driven manner. In particular, our proposed Embodied Locomotion loss is beneficial for efficiently training a stochastic HTP network using multiple heads. Furthermore, the Locomotion Value filter is proposed to filter out implausible trajectories at inference. Experiments demonstrate that our method enhances even the state-of-the-art HTP methods across diverse datasets and problem settings. Our code is available at: https://github.com/ImIntheMiddle/EmLoco.
Depth Estimation fusing Image and Radar Measurements with Uncertain Directions
Mar 23, 2024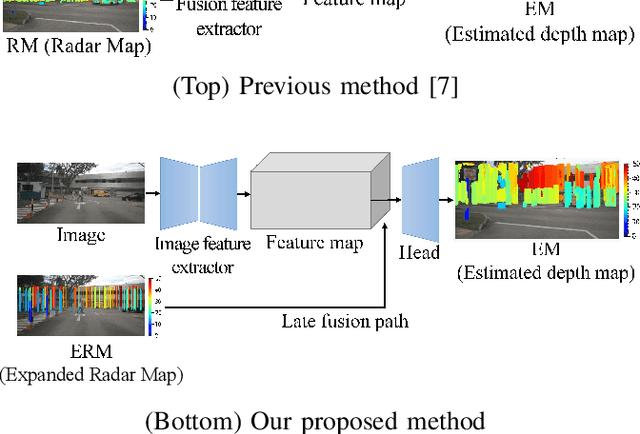
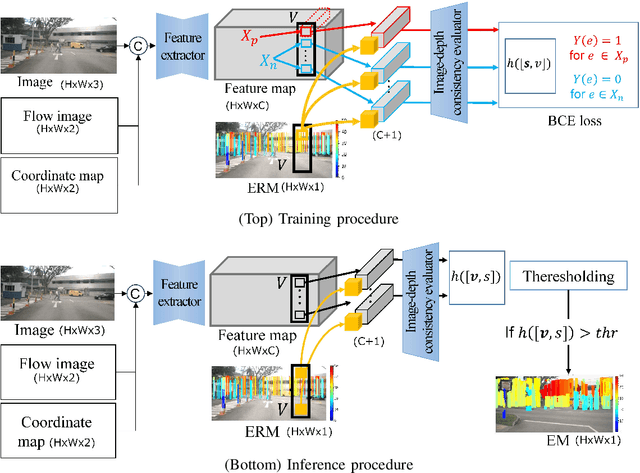
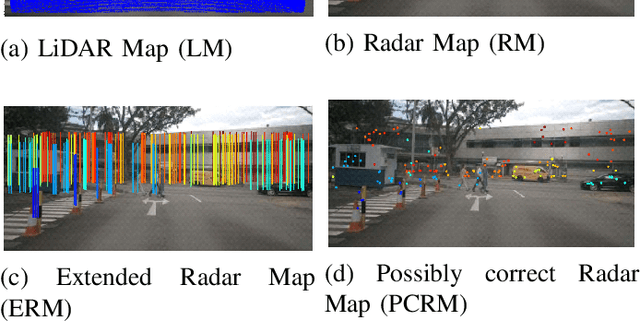
This paper proposes a depth estimation method using radar-image fusion by addressing the uncertain vertical directions of sparse radar measurements. In prior radar-image fusion work, image features are merged with the uncertain sparse depths measured by radar through convolutional layers. This approach is disturbed by the features computed with the uncertain radar depths. Furthermore, since the features are computed with a fully convolutional network, the uncertainty of each depth corresponding to a pixel is spread out over its surrounding pixels. Our method avoids this problem by computing features only with an image and conditioning the features pixelwise with the radar depth. Furthermore, the set of possibly correct radar directions is identified with reliable LiDAR measurements, which are available only in the training stage. Our method improves training data by learning only these possibly correct radar directions, while the previous method trains raw radar measurements, including erroneous measurements. Experimental results demonstrate that our method can improve the quantitative and qualitative results compared with its base method using radar-image fusion.
Cold Diffusion on the Replay Buffer: Learning to Plan from Known Good States
Oct 21, 2023



Learning from demonstrations (LfD) has successfully trained robots to exhibit remarkable generalization capabilities. However, many powerful imitation techniques do not prioritize the feasibility of the robot behaviors they generate. In this work, we explore the feasibility of plans produced by LfD. As in prior work, we employ a temporal diffusion model with fixed start and goal states to facilitate imitation through in-painting. Unlike previous studies, we apply cold diffusion to ensure the optimization process is directed through the agent's replay buffer of previously visited states. This routing approach increases the likelihood that the final trajectories will predominantly occupy the feasible region of the robot's state space. We test this method in simulated robotic environments with obstacles and observe a significant improvement in the agent's ability to avoid these obstacles during planning.
R2-Diff: Denoising by diffusion as a refinement of retrieved motion for image-based motion prediction
Jun 15, 2023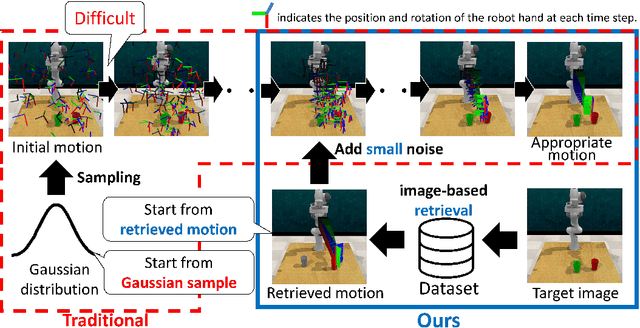
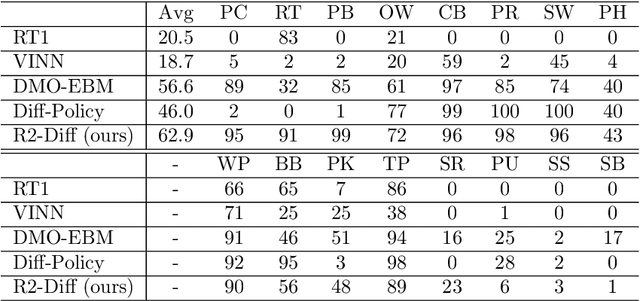
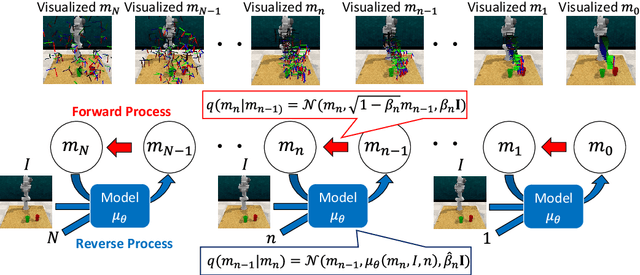
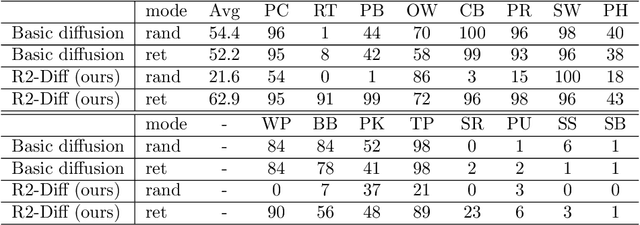
Image-based motion prediction is one of the essential techniques for robot manipulation. Among the various prediction models, we focus on diffusion models because they have achieved state-of-the-art performance in various applications. In image-based motion prediction, diffusion models stochastically predict contextually appropriate motion by gradually denoising random Gaussian noise based on the image context. While diffusion models are able to predict various motions by changing the random noise, they sometimes fail to predict a contextually appropriate motion based on the image because the random noise is sampled independently of the image context. To solve this problem, we propose R2-Diff. In R2-Diff, a motion retrieved from a dataset based on image similarity is fed into a diffusion model instead of random noise. Then, the retrieved motion is refined through the denoising process of the diffusion model. Since the retrieved motion is almost appropriate to the context, it becomes easier to predict contextually appropriate motion. However, traditional diffusion models are not optimized to refine the retrieved motion. Therefore, we propose the method of tuning the hyperparameters based on the distance of the nearest neighbor motion among the dataset to optimize the diffusion model for refinement. Furthermore, we propose an image-based retrieval method to retrieve the nearest neighbor motion in inference. Our proposed retrieval efficiently computes the similarity based on the image features along the motion trajectory. We demonstrate that R2-Diff accurately predicts appropriate motions and achieves high task success rates compared to recent state-of-the-art models in robot manipulation.
Data-Driven Stochastic Motion Evaluation and Optimization with Image by Spatially-Aligned Temporal Encoding
Feb 10, 2023This paper proposes a probabilistic motion prediction method for long motions. The motion is predicted so that it accomplishes a task from the initial state observed in the given image. While our method evaluates the task achievability by the Energy-Based Model (EBM), previous EBMs are not designed for evaluating the consistency between different domains (i.e., image and motion in our method). Our method seamlessly integrates the image and motion data into the image feature domain by spatially-aligned temporal encoding so that features are extracted along the motion trajectory projected onto the image. Furthermore, this paper also proposes a data-driven motion optimization method, Deep Motion Optimizer (DMO), that works with EBM for motion prediction. Different from previous gradient-based optimizers, our self-supervised DMO alleviates the difficulty of hyper-parameter tuning to avoid local minima. The effectiveness of the proposed method is demonstrated with a variety of experiments with similar SOTA methods.
NTIRE 2021 Challenge on Burst Super-Resolution: Methods and Results
Jun 07, 2021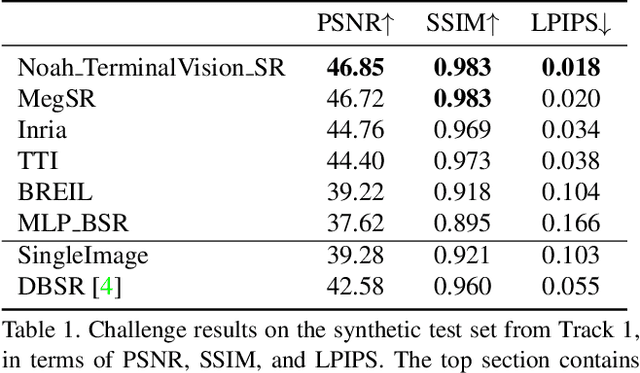

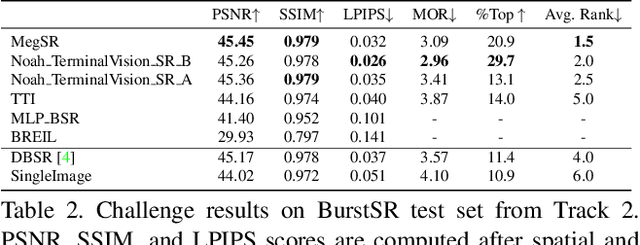

This paper reviews the NTIRE2021 challenge on burst super-resolution. Given a RAW noisy burst as input, the task in the challenge was to generate a clean RGB image with 4 times higher resolution. The challenge contained two tracks; Track 1 evaluating on synthetically generated data, and Track 2 using real-world bursts from mobile camera. In the final testing phase, 6 teams submitted results using a diverse set of solutions. The top-performing methods set a new state-of-the-art for the burst super-resolution task.