 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKS-DETR: Knowledge Sharing in Attention Learning for Detection Transformer
Paper and Code
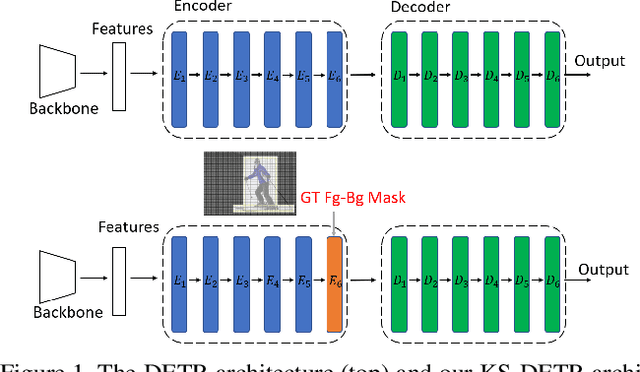

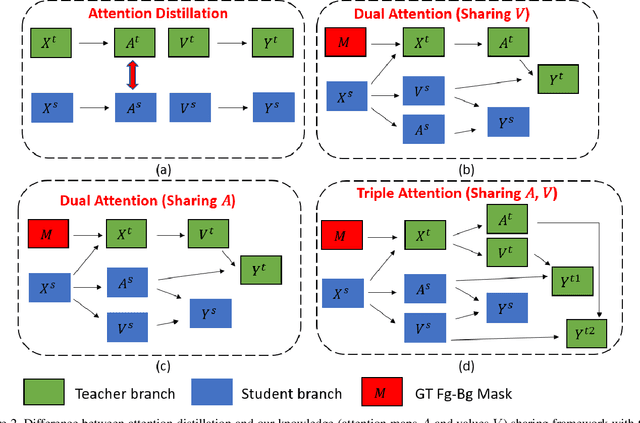
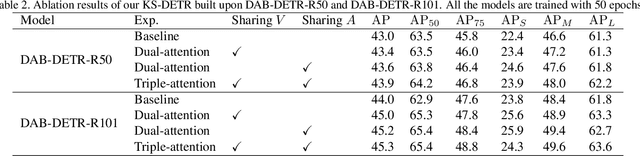
Scaled dot-product attention applies a softmax function on the scaled dot-product of queries and keys to calculate weights and then multiplies the weights and values. In this work, we study how to improve the learning of scaled dot-product attention to improve the accuracy of DETR. Our method is based on the following observations: using ground truth foreground-background mask (GT Fg-Bg Mask) as additional cues in the weights/values learning enables learning much better weights/values; with better weights/values, better values/weights can be learned. We propose a triple-attention module in which the first attention is a plain scaled dot-product attention, the second/third attention generates high-quality weights/values (with the assistance of GT Fg-Bg Mask) and shares the values/weights with the first attention to improve the quality of values/weights. The second and third attentions are removed during inference. We call our method knowledge-sharing DETR (KS-DETR), which is an extension of knowledge distillation (KD) in the way that the improved weights and values of the teachers (the second and third attentions) are directly shared, instead of mimicked, by the student (the first attention) to enable more efficient knowledge transfer from the teachers to the student. Experiments on various DETR-like methods show consistent improvements over the baseline methods on the MS COCO benchmark. Code is available at https://github.com/edocanonymous/KS-DETR.