 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-grained Attention-based Video Face Recognition
Paper and Code
May 06, 2019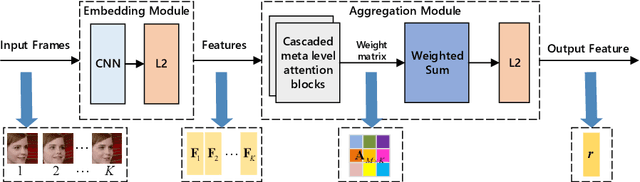



This paper aims to learn a compact representation of a video for video face recognition task. We make the following contributions: first, we propose a meta attention-based aggregation scheme which adaptively and fine-grained weighs the feature along each feature dimension among all frames to form a compact and discriminative representation. It makes the best to exploit the valuable or discriminative part of each frame to promote the performance of face recognition, without discarding or despising low quality frames as usual methods do. Second, we build a feature aggregation network comprised of a feature embedding module and a feature aggregation module. The embedding module is a convolutional neural network used to extract a feature vector from a face image, while the aggregation module consists of cascaded two meta attention blocks which adaptively aggregate the feature vectors into a single fixed-length representation. The network can deal with arbitrary number of frames, and is insensitive to frame order. Third, we validate the performance of proposed aggregation scheme. Experiments on publicly available datasets, such as YouTube face dataset and IJB-A dataset, show the effectiveness of our method, and it achieves competitive performances on both the verification and identification protocols.