 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMediaClaw: Multimodal Intelligent-Agent Platform Technical Report
May 14, 2026MediaClaw is a multimodal agent platform built on the OpenClaw ecosystem. Its core design follows a three-layer architecture of unified abstraction, pluginized extension, and workflow orchestration. The system is intended to address practical deployment pain points in AIGC adoption, including fragmented capabilities, heterogeneous interfaces, disconnected production processes, and limited reuse of high-quality production workflows. \system{} abstracts full-category AIGC capabilities into a unified invocation model, uses plugins to support hot-pluggable capability expansion, and uses task-oriented Skills to turn complex production processes into reusable workflow assets. This report focuses on the architectural design philosophy of MediaClaw, the design logic of its core capability model, and the key engineering trade-offs in implementation. It aims to provide reusable practical reference for building multimodal capability platforms.
MeanCache: From Instantaneous to Average Velocity for Accelerating Flow Matching Inference
Jan 27, 2026We present MeanCache, a training-free caching framework for efficient Flow Matching inference. Existing caching methods reduce redundant computation but typically rely on instantaneous velocity information (e.g., feature caching), which often leads to severe trajectory deviations and error accumulation under high acceleration ratios. MeanCache introduces an average-velocity perspective: by leveraging cached Jacobian--vector products (JVP) to construct interval average velocities from instantaneous velocities, it effectively mitigates local error accumulation. To further improve cache timing and JVP reuse stability, we develop a trajectory-stability scheduling strategy as a practical tool, employing a Peak-Suppressed Shortest Path under budget constraints to determine the schedule. Experiments on FLUX.1, Qwen-Image, and HunyuanVideo demonstrate that MeanCache achieves 4.12X and 4.56X and 3.59X acceleration, respectively, while consistently outperforming state-of-the-art caching baselines in generation quality. We believe this simple yet effective approach provides a new perspective for Flow Matching inference and will inspire further exploration of stability-driven acceleration in commercial-scale generative models.
A Realistic Face-to-Face Conversation System based on Deep Neural Networks
Aug 21, 2019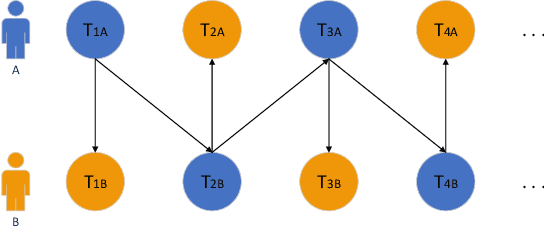

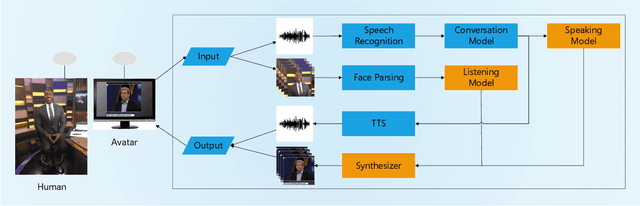
To improve the experiences of face-to-face conversation with avatar, this paper presents a novel conversation system. It is composed of two sequence-to-sequence models respectively for listening and speaking and a Generative Adversarial Network (GAN) based realistic avatar synthesizer. The models exploit the facial action and head pose to learn natural human reactions. Based on the models' output, the synthesizer uses the Pixel2Pixel model to generate realistic facial images. To show the improvement of our system, we use a 3D model based avatar driving scheme as a reference. We train and evaluate our neural networks with the data from ESPN shows. Experimental results show that our conversation system can generate natural facial reactions and realistic facial images.
Towards More Realistic Human-Robot Conversation: A Seq2Seq-based Body Gesture Interaction System
May 05, 2019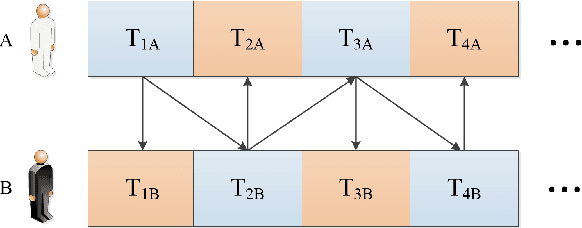

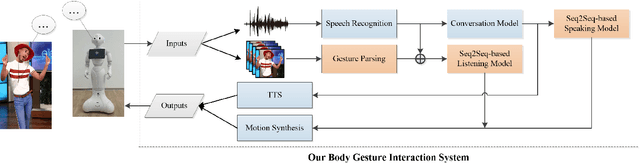
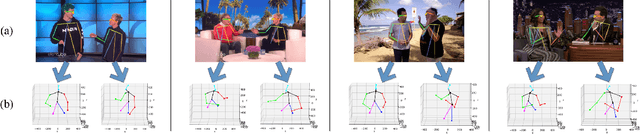
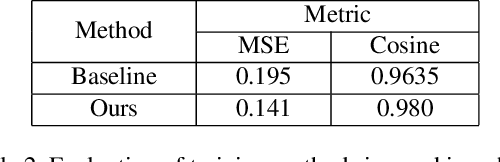
This paper presents a novel method to improve the conversational interaction abilities of intelligent robots to enable more realistic body gestures. The sequence-to-sequence (seq2seq) model is adapted for synthesizing the robots' body gestures represented by the movements of twelve upper-body keypoints in not only the speaking phase, but also the listening phase for which previous methods can hardly achieve. We collected and preprocessed substantial videos of human conversation from Youtube to train our seq2seq-based models and evaluated them by the mean squared error (MSE) and cosine similarity on the test set. The tuned models were implemented to drive a virtual avatar as well as a physical humanoid robot, to demonstrate the improvement on interaction abilities of our method in practice. With body gestures synthesized by our models, the avatar and Pepper exhibited more intelligently while communicating with humans.
Synthetic Data Generation and Adaption for Object Detection in Smart Vending Machines
Apr 28, 2019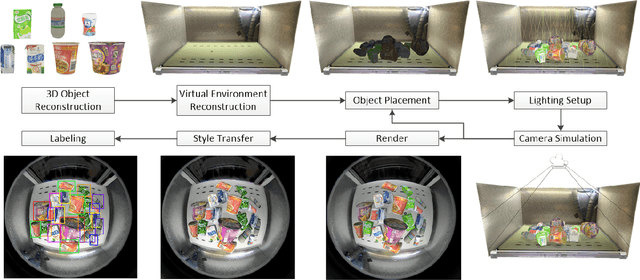
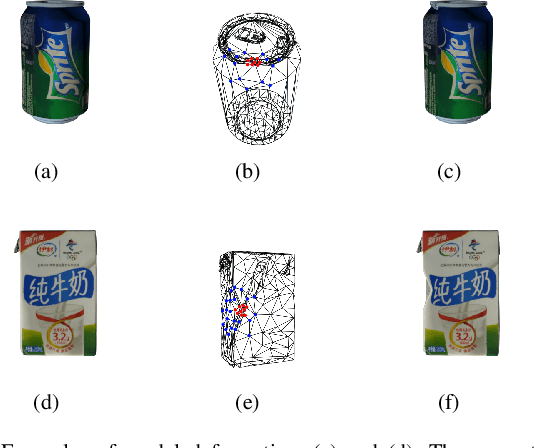
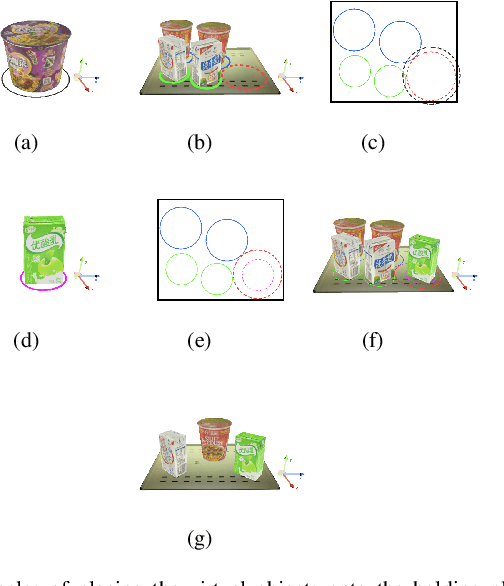
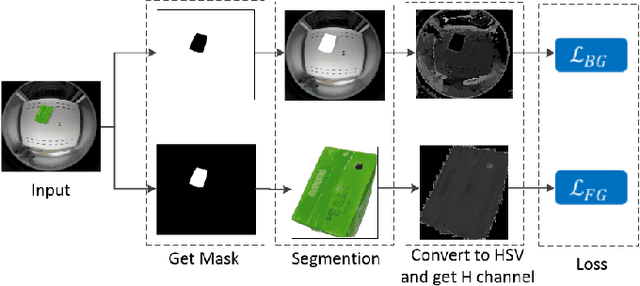
This paper presents an improved scheme for the generation and adaption of synthetic images for the training of deep Convolutional Neural Networks(CNNs) to perform the object detection task in smart vending machines. While generating synthetic data has proved to be effective for complementing the training data in supervised learning methods, challenges still exist for generating virtual images which are similar to those of the complex real scenes and minimizing redundant training data. To solve these problems, we consider the simulation of cluttered objects placed in a virtual scene and the wide-angle camera with distortions used to capture the whole scene in the data generation process, and post-processed the generated images with a elaborately-designed generative network to make them more similar to the real images. Various experiments have been conducted to prove the efficiency of using the generated virtual images to enhance the detection precision on existing datasets with limited real training data and the generalization ability of applying the trained network to datasets collected in new environment.